
本記事の要点
- 顔認識システムに対する敵対的攻撃手法及び防御手法の網羅的なサーベイを行った。
- 手法の特性に基づき深層学習モデルを誤識別させる攻擊手法は4種類に大別し、対応する防御手法は3種類に分類した。
- 標的モデルの精度へ影響を与えにくい、あらゆるモデルやデータセットに有効な汎用的な敵対的摂動であるUniversal Pertubationが強く求められる。
概要
顔認識システムは高い認証精度を実現し、ソーシャルメディアでの写真タギング機能から自動入国審査 (ABC) まで様々な実用アプリケーションへの応用が示唆されている。目覚ましい発展を遂げた深層学習に基づく顔認証アルゴリズムは高い認識精度が評価される一方で、実用化に向けて外部からの攻擊に対してシステムが安全であることを証明する必要がある。近年の研究より深層学習手法は、一見人の目からは何も意味を持たない画像や通常の画像区別のつかない敵対的サンプルを入力に与えると誤識別を引き起こす脆弱性を持つことが確認されている。
原論文では顔認識システムに対する敵対的攻擊手法を対象に包括的なサーベイを行い、攻擊及び防御手法を紹介する。また、これらの手法を独自で定めた評価基準に基づいた分類を行いタクソノミーを提案し各特徴ごとの手法を比較する。
論文情報
公開日
2021年1月31日
著者情報
Fatemeh Vakhshiteha, Raghavendra Ramachandrab, Ahmad Nickabadic
- a .. Department of Biomedical Engineering, Amirkabir University of Technology
- b .. Department of Information Security and Communication Technology, Norwegian Biometrics Laboratory (NBL), Norwegian University of Science and Technology (NTNU i Gjovik)
- c .. Department of Computer Engineering and Information Technology, Amirkabir University of Technology
論文情報・リンク
https://arxiv.org/abs/2007.11709
$\newcommand{\bm}[1]{\boldsymbol{#1}}\newcommand{\argmax}{\mathop{\rm arg~max}\limits}\newcommand{\argmin}{\mathop{\rm arg~min}\limits}$
内容詳細
1. はじめに
顔認識システムの究極的なゴールは撮影された動画のフレームや写真から個人を特定もしくは認証することであり、研究者は顔認識システムを「個人の顔特徴のパターンを分析して排他的に個人を特定できる人工知能を用いた生体認証アプリケーション」と定める。顔認識システムは生体認証技術として金融や軍事、公共安全、日常生活において広く利用されている。
顔を生体的特徴として用いる考えは1960年代より存在し、著名な顔認識システムの誕生は1990年代に遡る。近年の深層学習技術と安価で高性能な計算資源の増加により、大量のデータによって顔認識システムの精度は向上し目覚ましい発展を遂げた。この実績により、ソーシャルメディア上のタギング機能や自動入国審査 (ABC) まで顔認証技術を様々な分野に応用することが可能となった。
しかしながら顔認識システムを実用化する上で、精度のみならず外部からの攻擊に対してシステムが安全であることを証明する必要がある。近年の顔認識システムに実装される識別器は、入力データに対して様々な変化を加え意図的に誤識別を誘発させる攻擊手法に脆弱であることが報告されている。攻擊手法は、
(a) 撮影が行われる前に物理的に見た目を加工する物理的攻撃
(b) 取得した画像に対して加工を施し入力として与えるデジタル攻擊
の二種類に大別することができる。
プレゼンテーション攻擊、別名スプーフィング攻擊とも呼ばれている手法は物理的攻撃で使われる主な攻撃手法であり、敵対的攻擊やその派生であるモーフィング攻擊はデジタル攻擊の極めて重要な手法である。中でも敵対的攻擊はデジタル攻擊手法に分類されるものの、その応用性の高さから物理的攻撃として設計されているものも存在する。多種多様な攻撃手法が存在する中で、敵対的攻擊手法は高精度な畳込みニューラルネットワークを標的に行い、下図の論文の投稿数の推移からも分かるように近年多くの注目を集めている。
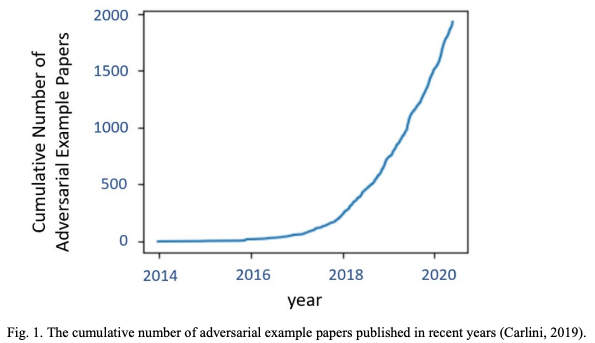
原論文では、顔認識システムを回避する目的で提案された様々な敵対的攻擊手法およびそれらの防御手法の総合的なサーベイ結果を紹介する。原論文の著者の知る限り、顔認識システムに対する敵対的攻撃手法と防御手法を扱った最初のサーベイ論文である。顔認識システムは「顔識別」および「顔検証」の異なる設計を指すが、原論文では両者をひとまとめにサーベイを行った。原論文の主な貢献は以下のとおりである。
- 顔認識システムに対する近年の敵対的攻擊手法の実例の紹介、ならびに手法を分類しタクソノミーを提案した。また、分類した攻撃手法を特徴ごとに分類し比較する。
- 顔認識システムに関する防御手法の実例を紹介し、これらアルゴリズムをカテゴライズした後にタクソノミーを提案する。
- 敵対的サンプルの標的となる顔認識システムの主な課題および解決方法を以下の4つの視点から述べる。
- 敵対的サンプルの特異性
- 顔認識システムの危険性
- 視覚システムからの逸脱
- 画像に依存しない敵対的サンプル生成手法
原論文の構成は次のとおりである。第2章で顔認識システムの背景および設計、データセットの説明を行う。続く3章では顔認識システムにおける攻擊および防御手法の論文で扱われる基本的な用語を解説する。4章では顔認識システムに対する攻撃手法を調査し、タクソノミーに基づいた分類および特性ごとに比較を行う。5章にて防御手法を紹介および比較し、第6章で現状の課題および今後の研究分野の方向性について議論する。最後に第7章では原論文の結論を述べる。
2. 背景
本章では顔認識システムを簡単に紹介し、ディープラーニング時代におけるモデルを詳述する。またよく使用されるアーキテクチャや標準データセットを紹介する。
2.1 顔認識システムの紹介
顔認識システムはコンピュータビジョンの領域では歴史のある研究テーマであり、最初の功績は90年代に遡る。それ以降、この領域は4度の目覚ましい発展を遂げた。
90年代初期に固有顔を用いた手法が提案され、顔認識の研究が活発化するきっかけとなった。2000年代までは、特定の分布の仮定に基づく顔画像からヒューリスティック手法を用いて低次元表現を抽出する手法が顔認識分野に強い影響をもたらした。これらの手法は前述した分布から逸脱した顔画像の変化に対応できない課題を抱えた。
2000年代初期には局所特徴に基づいた顔認識手法が提案され、ガボールやLBP特徴など人手によって設計された識別子が注目された。しかしこれらの手法は識別性能および容量の課題があった。2010年代初期には学習ベースの局所特徴量を抽出する手法が提案され、局所フィルタや埋め込み表現の対応表を学習し識別性能および容量の問題は改善されたが、これらの低次な特徴表現は依然として複雑で非線形な顔の外見上の変化に対して不安定であった。
これらの従来手法は単層もしくは2層から獲得される特徴表現を用いて顔認識を試み、精度の向上は緩やかであった。画像内の照度やオクルージョン、被写体の姿勢、表情といった顔上の変化を別々に扱っていた。ディープラーニング手法の登場により従来手法では不十分であったこれらの問題が解決された。
深層学習に基づく顔認識手法は、複数層からなるニューロンが画像の異なる抽象度の特徴表現を学習する。興味深いことに、高次の抽象的な特徴表現は照度、姿勢、表情、オクルージョンの変化に対して不変性を示し、並外れた安定性で顔特徴を表現できた。2014にはDeepFaceがLabeled Faces in the Wild (LFW) データセットに対して最高精度を実現した。9層のネットワークに400万枚の顔画像を学習させることで、初めて人間の認識精度に近い性能の実現に成功した。深層学習手法は顔認識の研究において、アルゴリズム設計や使用するデータセットから評価手法まで、全面的に一新させた。
2.2 著名な顔画像識別器の設計
DeepFaceは顔認識領域において初期の著名なディープアーキテクチャである。その後、FaceNetやVGG-Faceといった深層学習モデルが提案され、これらはそれぞれ一般物体認識で成功を収めたGoogleNetやVGGNetを用いて顔画像を学習させたものである。これらのモデルはtriplet lossを用いてfine-tuningが行われ、提案手法であるonline triplet mining methodによって作成した顔画像パッチを学習させた。
これらに続いてSphereFaceが提案され、これはResNetアーキテクチャに新しいangular softmax lossを用いてangular marginによって識別に有効な特徴量を学習した。SphereFaceに類似したCosFaceやArcFaceが提案され、これらはそれぞれcosineとangular marginに基づいた損失関数を用いて学習を行っている。GPUの性能やメモリ容量の問題を解決するために軽量なネットワークが提案され、これによってモバイルや組み込み機器に応用が可能となった。提案手法であるmax-feature-map (MFM) 活性化関数を用いたLightCNNは低容量な特徴表現および計算コストの削減を実現した。
2.3 顔認証タスク向けの標準データセットの紹介
2007年には3000枚の制御されていない環境下で撮影された顔画像からなるLFWデータセットが提供され、これをきっかけに顔認識タスクに用いられるデータベースが模索された。DeepFaceやFaceNet、DeepIDといった初期の顔認識モデルは、条件の制御された小規模な非公開データセットによって評価されているため、手法の比較を行うこと自体が困難であった。この課題を解決するために、CASIA-Webfaceと呼ばれる1万名の著名人からなる50万枚の画像データセットが提供され、広く公開データセットとして用いられるようになった。
枚数が十分にある学習データセットを用いて深層顔認識モデルの能力が評価されたことにより、この研究領域を促進させるためにより多くの複雑なデータセットが提供されるようになった。その後、MS-Celeb-1MやVGGface2、Megafaceといった100万枚を超える規模のものが大規模公開データセットとして最新の研究に採用された。
3. 敵対的攻擊生成手法
敵対的攻擊は標的とする識別器を意図的に誤識別させる目的で、人の目からは認識が不可能に近い軽微なノイズを画像に付与し加工する方法である。デジタル攻擊の領域では、入力画像 $\bm{x}$ に微小のベクトル $\bm{n}$ を加算した $(\bm{x}+\bm{n})$ によって実装できる。
これにより、敵対的サンプル $x’$ を生成するにはボックス制約最適化問題は以下のように記述できる。
\[ min ||x’-x||_2 \] \[
s.t. \mathcal{F}(x’)=l’ \] \[
\mathcal{F}(x)=l \] \[
l \ne l’ \] \[
x’ \in [0,1] \tag{1} \]
ここで、 $\bm{l}$および$\bm{l’}$は$\bm{x}$および$\bm{x’}$の出力ラベルを指し、$||\cdot||_2$は2枚の画像サンプルの$L_2$ノルムに基づく距離を示す。
下記図より表されているように顔認識システム (例ではVGG16) を騙すには、人が正しい画像カテゴリを特定できつつネットワークは異なるカテゴリへ誤識別してしまうように画像を加工する。Szedgedyら (2013)は入力画像に対して微小なノイズを加えることで生成される敵対的攻擊手法に対するCNNの脆弱性を初めて証明した。またGoogleNetやVGG-Faceモデルも精度の低下がカラーバランスの調整によって引き起こせることが証明された。

敵対的攻撃手法の不可視な性質と深層学習の広い応用範囲よりこの攻撃手法は非常に実世界において驚異となることを注意する必要である。例を挙げると、自動運転において敵対的攻撃手法により道路標識が加工されると、運転手や歩行者、他の通行車両を危険に晒すことになる。同様に顔認識システムにおいて、加工された入力の検証を誤りシステムの性能低下は第三者の侵入を許してしまう。
3.1 専門用語と定義
本節では顔認識システムに対する敵対手攻擊に関する一般用語を解説する。用語の理解は調査対象の文献で紹介される技術を理解する上で必要不可欠である。原論文の文中で用いられる用語は下記の定義に従う。
3.1.1 一般用語
- 敵対的サンプル / 敵対的画像:顔認識システムのような機械学習モデルを誤識別させるために元画像へ意図的にノイズを加えた画像。
- 敵対的学習:通常画像と敵対的画像を両方用いた学習過程。
- 敵対者 (Adversary):敵対的サンプルを生成する者を指すこともあれば、敵対的サンプルそのものを指す場合もある。文献によって解釈は異なる。
- 驚異モデル:脅威モデルは、攻撃者の目標や攻撃戦略、攻撃システムの知識、標的モデルに関する入力データおよびシステムコンポーネントの機能を定式化したモデル。
3.1.2 専門用語
- Dodging攻擊:顔画像を本人以外の任意の他人へ誤識別させる攻擊手法。
- Evasion攻擊:学習データに手を加えず、テストデータの用いてシステムの認証を回避する手法。
- なりすまし攻擊:システムに登録されている他人になりすますことで侵入を図る手法。
- ポイズニング攻擊:モデルに対して汚染データを用いて学習させることで、特定のテストデータを攻撃者の意図したクラスに誤分類させることができる手法。
3.2 敵対的攻擊の特性
本節では、敵対的サンプル生成手法の主な特性について論じる。
3.2.1 敵対的能力
敵対的能力は攻擊者が標的の識別器に関して知りうる知識量に応じて下記の2種類に分類することができる。
- ホワイトボックス攻擊:攻擊者は標的の識別器に関する一切の情報を持っていると仮定する。識別器のパラメータやネットワーク構造、学習手法、場合によっては学習データの情報も分かっている。
- ブラックボックス攻擊:標的の識別器に関する知識はなく、敵対的サンプルを与えながら挙動を確認し行う攻撃手法。敵対的サンプルの転移性能 (後述) を利用することで標的の識別器とやり取りすることができる。
3.2.2 敵対的特異性
敵対的特異性は攻撃手法が識別器を誤識別させた際に、予測ラベルの制御度合いによって次のタイプに分類できる。
- 標的型攻撃はモデルを騙し、敵対的サンプルを特定のラベルへ誤って予測させる。 生体認証システムでは、なりすまし攻擊等が標的型攻撃に分類される。
- 非標的型攻擊は敵対的サンプルの予測ラベルを正解ラベル以外に誤識別させる。顔認識または生体認証システムでは、これはDodging攻擊によって実現される。非標的型攻撃は出力ラベルの変更先の選択肢が多いため、標的型攻撃よりも実装が容易である。
3.2.3 敵対的転用性能
モデルの作成に使用した敵対的サンプルが外部モデルに対して同様に影響を与える特性は、転用性能と呼ばれる。データセットや学習パラメータといった標的モデルの設計を知ることができないブラックボックス攻擊において非常に有効である。このような状況では、代わりとなるニューラルネットワークモデルを学習し、それに対して敵対的サンプルを生成することができる。敵対的サンプルの転用性能は、標的モデルのアーキテクチャや使用するデータセットによって難易度が異なる(Yuan et al., 2019)。
3.2.4 敵対的摂動
敵対的摂動とは画像に付与するノイズを指し、ノイズの付与された敵対的サンプルは標的のモデルを高い確率で誤識別させることができる。敵対的機械学習の領域では敵対的摂動のノルムを最小化し、標的モデルを誤識別させる。入力画像$\bm{x}$が与えられたとき、摂動ベクトル$\bm{n}$は$\bm{x}$から分類器の決定境界までの最小距離に対応する$\bm{x}$のラベルを変更することを目的とする。
\[ \min_{\bm{n} \in \textbf{R}^d} |\bm{n}|_2 \] \[
s.t. \mathcal{F}(\bm{x})\mathcal{F}(\bm{x+n}) \le 0 \tag{2} \]
ここで $\textbf{R}^d$ 入力と摂動ベクトルの次元を指す。実装の範囲に応じて、敵対的摂動は次のように分類することができる。
- Image-specific perbutationは与えられた入力画像に従って明示的に生成することができる。
- Universal pertubationは与えられた画像の予備知識がなくても敵対的サンプルを生成することができる。ここでUniversalityは摂動が高い転用性能を持ち任意の入力に対して満遍なく適用できる特徴を表す。
Universal perbutationは実世界では非常に有効的な敵対的サンプルを生成できるものの、近年の攻撃手法はほとんどimage-specific pertubationが用いられる。しかしながらこれらの研究は入力画像が変更されても摂動の改変の必要のないuniversal pertubationの生成を目標に発展している。
3.3 著名データセットおよびモデル
顔認識システムに対する敵対的攻撃手法は、様々なデータセットと標的モデルを用いて評価される。
3.3.1 データセット
LFWおよびCASIA-Webface、MegaFace、VGGFace2、CelebA (Liu et al., 2015)は顔認識システムに対する敵対的攻撃手法を評価する上で最も広く使用される画像識別タスク向けのデータセットである。
3.3.2 標的モデル
攻撃者はDeepFaceやFaceNet、DeepID、SphereFace、CosFace ArcFace、OpenFace (Amos et al., 2016)、dlib (dlib C++ Library, 2018) 、LResNet100E-IR Face IDモデル (InsightFace Model Zoo, LResNet100E-IR, ArcFace@ms1m-refine-v2., 2018)などのいくつかの著名な深層顔認識モデルを対象に攻擊を行っている。次節でこれらのデータセットおよびモデルを採用した顔認識モデルを標的にした敵対的サンプルに関する近年の研究を紹介する。
3.4 従来手法
本節では、敵対的サンプルを生成するために提案されたいくつかの従来方法を紹介する。これらの手法のほぼ全てが実世界の機械学習システムで使用されるモデルに多大な影響を与えることができる。特にディープニューラルネットワークを攻撃する手法を対象に、時系列順に紹介する。
1) L-BFGS
Szegedyら (2013) はL-BFGS手法を用いて初めて敵対的サンプルを生成した。ボックス制約付きL-BFGS手法は下記の問題を近似的に求めた。
\[ \min_{x’} c |\bm{n}|_2 + \textbf{L}(\bm{x’},l) \] \[
s.t. \bm{x’} \in [0,1] \tag{3} \]
ここで $\textbf{L}(\bm{x’},l)$ は識別器の損失関数を示し、$c>0$の最小値は上記条件を満たすために直線探索を用いて近似的に計算される。著者らは上記手法がニューラルネットワークを誤識別させ、人間の目には判別不能な摂動を生成できることを証明した。
2) Fast Gradient Sign Method (FGSM)
Goodfellowら (2014) は高速で直感的なFast Gradient Sign Method (FGSM)を提案した。下式を効率的に解くことで敵対的摂動を生成する。
\[ \bm{n} = \grave{o}sign(\nabla_x\textbf{J}(\bm{\theta},\bm{x},l)) \tag{4} \]
ここで $\grave{o}$ は摂動の大きさを示し、$sign(\cdot)$は符号関数、$\nabla_x\textbf{J}(.,.,.)$は$\bm{x}$に関する現在のパラメータ値の損失関数の勾配を示す。生成された敵対的サンプル $\bm{x’}$ は $\bm{x’}=\bm{x}+\bm{n}$によって求まる。FGSMを応用することで、各ピクセルの勾配方向に一度だけ勾配更新を行うことで敵対的サンプルを生成できる。また、Miyatoら (2018) はFast Gradient $L_2$ と称した類似手法を提案し、摂動は次式で求めることができる。
\[ \bm{n} = \frac{\nabla_x\textbf{J}(\bm{\theta},\bm{x},l)}{|\nabla_x\textbf{J}(\bm{\theta},\bm{x},l)|_2} \tag{5} \]
(5)式より、計算された勾配は自身の $L_2$-norm によって正規化されている。同様に、Kurakinら (2016b)は $L_\inf$-normを正規化に用いたFast Gradient $L_\inf$手法を提案した。これらの勾配更新を一度しか行う必要のない手法は、ワンステップ手法として知られている。
3) Basic & Least-likely Iterative Class Methods
Kurakinら (2016a) は前述したワンステップ最急上昇法の考えを拡張しBasic Iterative Method (BIM)を提案した。BIMは複数の小さなステップをとりながら反復的に損失関数の値が増大する方向へ調整する。各反復処理において、画像のピクセル値は以下の値にクリッピングされる。
\[ \bm{x’^{(i+1)}} = Clip_\grave{o}{\bm{x’^{(i)}} + \alpha\cdot sign(\nabla_{x’^{(i)}}\textbf{J}\bm{\theta},\bm{x’}^{(i)},l)}
\tag{6} \label{6} \]
ここで $\bm{x’}^{(i)}$ は$i$回目の反復処理で生成された敵対的サンプルを示し、$Clip_\grave{o}{\cdot}$ で各反復処理での変化を範囲内に留め、$\alpha$はステップサイズを示す。BIMアルゴリズムの初期化は $x’^(0) = x$ によって行われ、反復処理の回数は $min(o+4,1.25o)$で決定する。文献内では本手法を Iterative Fast Gradient Sign Method (I-FGSM) と呼んでいる。また本手法を基に、勾配$\nabla_{x’^{(i)}}\textbf{J}$ の扱い方の異なるIterative Fast Gradient Value Method (I-FGVM)が提案された。とりわけ、I-FGVMは入力 $\bm{x}$ を勾配方向へ変化させる。I-FGSMの各反復処理において、画像のピクセル値は下式によってクリッピングされる。
\[ \bm{x’^{(i+1)}} = Clip_\grave{o}{\bm{x’^{(i)}} + \alpha\cdot \nabla_{x’^{(i)}}\textbf{J}(\bm{\theta},\bm{x’}^{(i)},l)} \tag{7} \]
同様に別の研究でKurakinら (2016a) はBIMを拡張しIterative Least-likely Class Method (ILCM)を提案した。式 $\eqref{6}$ におけるラベル情報 $l$ を最も予測確率の低かったクラス $ll$ に置換しクロスエントロピーロスの最大化を試みた。
4) Jacobian-based Saliency Map Attack (JSMA)
Papernotら (2016a) は摂動の $L_0$ ノルムを制限する敵対的攻撃手法を設計した。画像の全体に摂動を加えることに対して、本手法は出力に大きな影響を与える数ピクセルを対象に摂動を加えた。結果として、正規画像の各ピクセル値を変化させながら識別結果への影響を確認できるJacobian-based Saliency Map Attackを提案した。提案手法は標的モデルを誤識別させる目的で、敵対的画像における変更可能な最大のピクセル数まで繰り返される。
5) One Pixel Attack
J. Suら (2019) は単一のピクセルを変化させるだけで複数の標的モデルを誤識別させることのできる高性能な攻擊手法を提案した。最適化問題は以下の式で表す。
\[ \min_{x’} \textbf{J} (\bm{\theta}, \textbf{F}(\bm{x’}),l’) \tag{8} \] \[
s.t. |\bm{n}|_0 \le \grave{o}_0 \]
単一のピクセルのみ変更する場合は、$\grave{o}_0$を1に設定する必要があるため最適化問題は難しくなる。従って、差分進化の概念 (Das and Suganthan, 2010) を適用して最適解を求めた。この手法では、標的モデルによって予測された確率的なラベル情報が必要であり、ネットワークパラメーター値または勾配に関する情報は必要ない。本手法は単純な進化戦略を採用し標的モデルを効果的に誤識別させることできる。
6) DeepFool
Moosavi-Dezfooliら (2016) は、DeepFoolという反復的な手法を提案し、正規の入力画像の最小のノルムを持つ敵対的摂動を生成した。提案されたアルゴリズムでは、入力画像がアフィン識別器の決定境界によって制限された範囲に存在する仮定で初期化され、入力のクラスラベルが最初に求められた。各反復処理において、画像に微小な摂動が加えられる。得られた敵対的サンプルの識別境界は、画像が存在する領域の識別境界をもとに線形近似して導く。各反復で摂動が画像に加えられ、累積した最終的な摂動を計算する。これにより、画像領域の元の決定境界に従って入力画像ラベルが変更される。DeepFoolは、FGSMおよびJSMAと比較して、同様の誤識別率を達成しながら、より微小な摂動を用いられることを実証した。
7) Universal Adversarial Pertubations
特定の画像のみに有効な摂動を生成するDeepFoolに対して、画像の前提知識を必要としないuniversal Adversarial Pertubationを生成する手法をMoosavi-Dezfooliら (2017)は新しく提案した。下式の制約を満たすuniversal pertubationを求める手法を試みた。
\[ P(\textbf{F}(\bm{x})\ne\textbf{F}(\bm{x}+\bm{n}))\ge \delta \] \[
s.t. |\bm{n}|_p \le \xi \tag{9}\label{9} \]
ここで $P(.)$は確率、$\delta$ は誤識別率、$|.|_p$は$L_p$ノルム、$\xi$は摂動の大きさを示す。その結果、$\xi$の値を減少させることで敵対的サンプルは人の目では認識しづらくなることが確認できた。またUniversal Adversarial Pertubationは複数の著名なディープラーニングモデル (VGG、CaffeNet、GoogLeNet、ResNet) に対して高い汎化性能を示した。
8) Carlini & Wagner Attacks (C&W)
Carlini and Wagner (2017)は防御手法として著名なモデルの軽量化手法であるネットワークの蒸留に対していくつかの敵対的攻撃手法を提案した。従来の$L_0$および$L_1$、$L_2$ノルムに基づく敵対的サンプル生成手法は、蒸留手法によって防御できると説明した。また、蒸留前のネットワークによって学習された敵対的サンプルは蒸留を行ったネットワークに対しても有効でありブラックボックスの環境下でも効果的であることを示した。
4. 顔認識システムに対する敵対的サンプル生成手法
本節では、顔認識システムに対する敵対的サンプル生成手法を紹介する。まず、文献で紹介されている主な攻撃生成方法について説明し、次にそれぞれの指向型に応じて攻撃手法の比較を行う。最後に、敵対的能力および特異性、転用性能、摂動の種類の4特性に基づいて比較を行う。
4.1 手法
顔認識システムに対する敵対的サンプル生成手法を分類したタクソノミーを下記図に示す。これらの手法は主に4つのカテゴリに分類し、それぞれ(1)CNNモデル指向型、(2)物理攻撃指向型、(3)匿名化指向型、(4)幾何学指向型である。
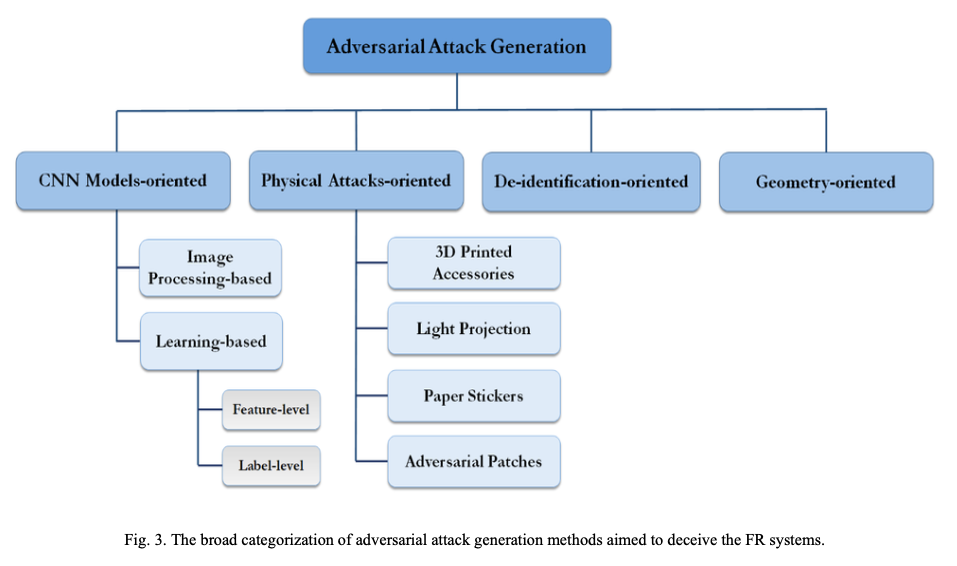
また原論文内で扱う攻撃手法を上記のカテゴリに分類し、一覧にまとめた結果を下記表に示す。
| 著者 | カテゴリ | 特徴 |
|---|---|---|
| Goswami et al., 2018 | CNNモデル指向 | 画像レベルおよび顔画像レベルでの敵対的サンプル生成手法を提案しDNNの頑健性を評価。 |
| Dong et al., 2019 | CNNモデル指向 | 顔認証モデルの出力ラベルのみの情報を用いた攻擊生成手法 (1+1)-CMA-ESを提案し、既存顔認証モデルの頑健性を評価。 |
| Zhong & Deng, 2020 | CNNモデル指向 | dropoutを利用した提案手法DFANetによって、既存の攻撃手法の転移性能を向上できることを確認。 |
| Goodman et al., 2020 | CNNモデル指向 | 多くのディープラーニング開発ライブラリに適用できるAdvboxツールボックスの提案。 |
| Sharif et al., 2019, 2016 | 物理的攻撃指向 | L-BFGS手法および3Dプリントされた眼鏡フレームを用いた物理レベルの侵入手法を提案。 |
| Zhou et al., 2018 | 物理的攻撃指向 | 赤外線LEDを貼付した帽子を用いた物理的な敵対的サンプル生成手法を提案。 |
| Shen et al., 2019 | 物理的攻撃指向 | 可視光を用いた実用的な攻撃手法を提案。 |
| Nguyen et al., 2020 | 物理的攻撃指向 | 光投影手法を用いたリアルタイム敵対的攻擊手法を提案。 |
| Komkov & Petiushko, 2019 | 物理的攻撃指向 | LResNet100E-IR顔認証システムに対してステッカーを用いた再現可能かつ転移性能の高い攻撃手法を提案。 |
| Pautov et al., 2019 | 物理的攻撃指向 | LResNet100E-IR顔認証システムに対して顔パーツの印刷物を貼付した攻擊手法を提案。 |
| Garofalo et al., 2018 | 匿名化指向 | OpenFaceにSVM識別器を拡張したフレームワークに基づく認証システムへのPoisoning攻擊手法を提案。 |
| Chatzikyriakidis et al., 2019 | 匿名化指向 | P-FGVM敵対的攻擊手法を用いた匿名化顔画像の生成手法を提案。 |
| Kwon et al., 2019 | 匿名化指向 | フレンド識別器を承認する敵対的顔画像サンプル生成手法を提案。 |
| Dabouei et al., 2019 | 幾何学特徴指向 | 幾何学的に摂動された敵対的サンプルに対する顔認証システムの脆弱性を確認するため、高速ランドマーク変換手法を提案。 |
| Song et al., 2018 | 幾何学特徴指向 | GANを用いたターゲットに類似した敵対的サンプル生成するアルゴリズムA3GNを提案。 |
| Deb et al., 2019 | 幾何学特徴指向 | 顔画像の隆起した領域に注目した転移性能の高い敵対的顔画像生成手法を提案。 |
各手法の詳細は本記事Appendixに記す。
4.2 タクソノミーに基づいた敵対的攻撃手法の分類および比較
4.2.1 CNNモデル指向型
前述のとおり、ディープラーニングは顔認識の領域において目覚ましい発展を遂げた。多くのモデルは複数のデータベースで評価した際に非常に高い精度を達成するように設計されている。多くの中間層と数百万のパラメーターから構成されるディープCNNベースのアーキテクチャである。日々精度の改良されたモデルが報告される中で、敵対的攻撃を受けやすいことが示されている。これを実現するために、多くの研究者はアルゴリズムの弱点を利用して、CNNモデルの堅牢性を調査し、それらの特異性を明らかにする手法が提案されている。
Goswamiらの研究
Goswamiらは画像レベルと顔特徴レベルの画像処理をそれぞれ入力画像に対して行い、CNNベースの顔認証アルゴリズムの脆弱性を調査した。これにより、攻撃手法は必ずしも複雑な学習ベースの手法である必要が無いことが確認できた。ランダムノイズや垂直と並行な線を顔画像上に描画することで顔認証精度を大幅に低下させることが可能と示した。

Dongらの研究
Dongらは入力に対する識別器の出力ラベルのみ得られる (decision-based) ブラックボックス環境下で高性能な顔認識システムであるSphereFaceおよびCosFace、ArcFaceそれぞれの頑健性を評価した。共分散行列適応進化戦略 (CMA-ES) 手法をベースとした攻撃アルゴリズム (1+1)-CMA-ESを提案し、顔画像データセットLFWおよびMegaFaceに対して顔認証および人物特定タスクを解いた。両タスクにおいて従来手法と比較し、より学習が速く収束し、同等の精度を達成しながら画像に対してより軽微な歪みを加えることに成功した。
Zhongらの研究
ZhongとDengはCNNの転用可能な敵対的サンプルに対する脆弱性を調査し、特徴レベルの攻撃手法はラベルレベルの手法と比較してより効果的で転移性能が高いことが確認できた。DropoutをベースにしたDFANetを提案し、本手法が既存の攻撃手法の転移性能を大幅に向上させることを確認した。
Goodmanらの研究
Goodmanらは、Advboxと呼ばれる敵対的サンプルを生成するPython toolboxを提案した。Advboxを用いることでPaddlePaddleおよびPyTorch、Caffe2、MxNet、Keras、Tensorflowによって実装されたモデルに対して攻擊を行うことで誤識別を引き起こし頑健性を評価することができる。従来の研究と比較して、本プラットフォームはMLaSSのブラックボックス攻撃や顔認識システムへの攻撃などの実際の攻撃シナリオに対応している。
4.2.2 物理的指向型
生体認証システムへ侵入を図る攻擊者は主に2つの課題を抱える。
- 他の利用者と同じように、顔認識システムのデジタル入力をコントロールする権限を持たない。
- 認証を突破するために過度な仮装をすることで、警察等から注目されやすくなる。
Sharifらの研究
Sharifらは物理的に実現可能で目立ちにくい自作メガネフレームを使用した攻撃手法を提案した。ホワイトボックス攻撃に注目し、著者らは認証を回避し他人になりすますことに成功した。

Zhouらの研究
Zhouらは帽子に小型の赤外線LEDを取り付け、目立たない物理的な敵対的攻撃手法を提案した。赤外線LEDは顔特徴をわずかに変化させる目的で特定の位置に配置される。本手法で使用されたLoss関数は、攻擊者の顔写真に則して照明の当たる点を調整することで最適化された。この光点の位置や大きさ、強さを調節することで攻擊者は検知の回避や他人になりすますことができる。LFWデータセットとFaceNet FRシステムで検証し、一人の攻擊者がデータセットに含まれる70%の個人を標的にすることができることが確認できた。
Shenらの研究
Shenらはカメラと人の目によって画像が構成される過程に注目し、光を扱った手法をブラックボックスFRシステムに対して行った。visible light-based attack (VLA) はプロジェクターを用いて攻擊者の顔面に敵対的サンプルを表現する光を投影させることで認証を回避する方法である。実験より、著者らは敵対的摂動は顔特徴を変化させる摂動フレームとその変化を人の目によって知覚を困難にさせる隠蔽フレームから構成されることを述べている。LFWデータセットとFaceNet、SphereFace、dlibに対して手法を適用し、提案手法の成功率を評価した。FGSMと比較して、提案手法は飛躍的に高い成功率を達成した。
Nyugenらの研究
Nyugenらは、Shenらと同様に敵対的光投影(light projection)によるFRシステムへのリアルタイム攻擊が実現可能かWebカメラとプロジェクタを用いて検証した。著者らは攻擊者となりすまし対象の画像を用いてカメラとプロジェクタの攻擊環境を整え、投影するデジタル敵対的模様を作成した。Zhouらの研究と同様に赤外線を利用した敵対的攻撃手法ではあるものの、本手法はウェアラブルを身につける必要なく認証を突破できることを示している。FaceNetおよびSphereFace、商業利用されているFRシステムに対して実験を行い、ホワイトボックスおよびブラックボックス環境下での光投影によるシステムの脆弱性を示した。

Komkovらの研究
KomkovとPetiushkoは公開されている顔認証モデルLResNet100E-IRおよびArcFace@ms1m-refine-v2を対象に、複製が容易な敵対的攻撃手法を生成できるAdvHatを提案した。著者らは標準的なカラープリンターで長方形のステッカーを印刷し帽子に貼付したのちに敵対的サンプルをステッカーに投影させた。
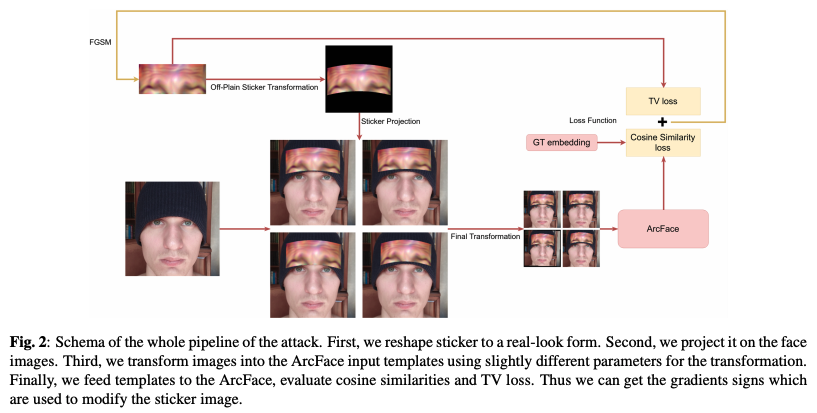
学習を行う上で2つのパラメータの最適化を行い、ステッカー画像を作成するための勾配値を取得した。これらのパラメータはそれぞれ、元の長方形ステッカーのtotal variation loss (TV loss) および攻擊者の顔画像とArcFaceによって算出された標的の顔画像のコサイン類似度である。CASIA-WebFaceデータセットを使用した実験では簡単にLResNet100E-IRを欺くことができ、他の顔認証モデルにも転用可能である。
Pautovらの研究
Pautovらも同一の顔認証モデルを対象に攻撃手法を提案した。著者らは敵対的パッチを印刷し貼付、撮影する方法を提案した。この敵対的パッチを身に着けた被験者の写真は分類器に与えられ、正常クラスから目的のクラスへ変更させる。本研究では、敵対的パッチは攻擊者の鼻や額、眼鏡といった顔における様々なパーツを用いることができる。CASIA-WebFaceデータセットおよび攻擊者役の著者二名の写真を用いた実験では、本提案手法のようなシンプルな攻撃手法がデジタルドメイン上のみならず、現実世界の顔認識システムを欺くことができた。現実世界のArcFaceシステムを眼鏡や額に貼付した敵対的ステッカーを用いて攻撃することが可能なことを実証した。
4.2.3 秘匿化指向型
顔分析タスクにおいて高精度な結果を出したディープラーニングモデルは多くの利点がある一方で、システムを利用する個人のプライバシーを侵害する可能性があると懸念されている。例えば、ソーシャルメディア上に存在するユーザーのプロフィール画像から年齢や性別、人種を推定することができる。個人のプライバシーを守るため、顔属性を利用した珍しい攻撃手法が提案されている。顔特徴指向の攻撃手法がその他の攻擊手法カテゴリと異なる特徴として、主な目的がシステムの悪用ではなく利用者のプライバシーの保護にある。つまり、本章で説明する攻擊手法は顔認識システムを正常に利用しつつ利用者の望む顔属性を秘匿化する目的で利用される。
Garofaloらの研究
GarofaloらはOpenFace認証フレームワークに基づく認証システムにたいしてpoisoning攻擊を行った。FaceNetモデルによって抽出された顔テンプレートを識別するためのSVMモデルに対する攻擊を実装した。実験より、最も成功した攻擊では50%を超える認証エラーを引き起こした。
Chatzikyriakidisらの研究
Chatzikyriakidisらは敵対的サンプルを匿名化に使用する手法を提案した。penalized fast gradient value method(P-FGVM)手法を提案し、画像ドメイン上で秘匿化された敵対的顔画像サンプルを生成する。本手法はfast gradient value method(I-FGVM)から影響受けており、差分として敵対的lossに写実loss(realism loss)を加えている。簡素なモデルとfine-tunedされたVGG-Face CNNを評価の対象に実験を行い、I-FGVMと比較して提案手法は画像のプライバシーと画質を保っていることを示した。

Kwonらの研究
Kwonらは最小限の画像の加工を行い、指定したシステムに対しては正しく認識を行い、その他のシステムに対しては誤識別を招くfriend-safe敵対的サンプル生成手法を提案した。提案手法はtransformerおよびフレンド分類器、エネミー分類器から構成され、敵対的顔画像サンプルを生成する。FaceNet顔認識システムを標的に著者らはVGGFace2を用いて提案手法を学習し、LFWデータセットで評価を行った。実験より、エネミー分類器に対すて92.2%の攻擊成功率を達成しつつフレンド分類器に対して91.2%の精度が得られ、タスクを達成するために加えた画像への歪みの最小値は64.22であった。
幾何学指向型
既存の輝度値を操作する敵対的攻撃手法は計算コストが小さいものの、生成画像は空間的な変換の影響を受けやすい問題が挙げられる。これらの手法は微小な回転、変換、スケールの変化によって画像の類似度を大きく変化させることができる。この問題によって、幾何学特徴に基づく新しい種類の攻撃手法が提案された。
Daboueiらの研究
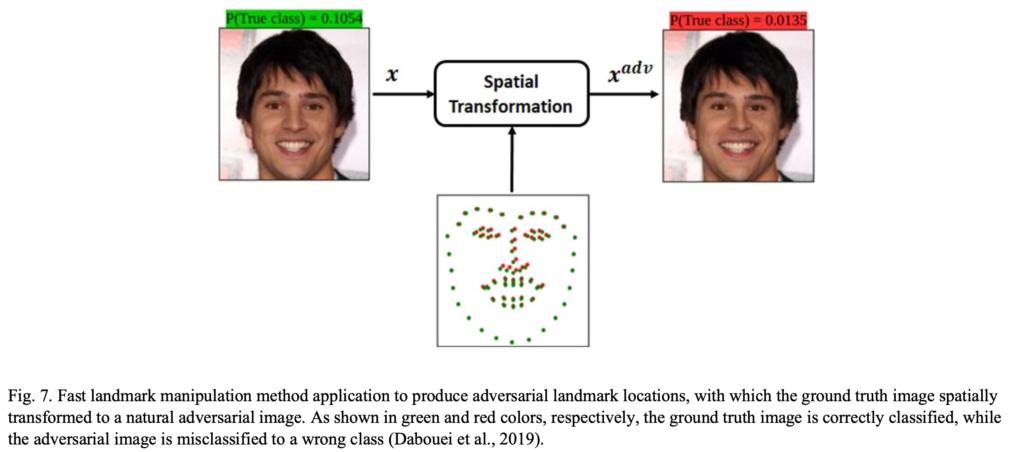
Daboueiらは画像を空間的に変換させることで敵対的サンプルを生成する手法『fast landmark manipulation method (FLM)』および『grouped fast landmark manipulation method (GFLM)』を提案した。pixel単位の変換に注目していた先行研究と異なり、本手法は顔のランドマークに注目し、限られたk個のランドマーク情報を用いて高速に敵対的サンプルを生成できる。FaceNetをVGGFace2およびCASIA WebFaceデータセットで学習しWebFaceで評価したところ、FLMとGFLMは99.86%のサンプルをご識別させられる敵対的顔画像サンプルを生成した。下記図がFLMの概略図である。
Songらの研究
SongらはGANを応用し指定したクラスへ誤識別させるattentional adversarial attack generative network (A3GN) を提案した。本手法は特徴空間上では標的の人物の顔画像と同じ特徴表現を持ちつつ、元画像と視覚的に似た敵対的サンプルを生成することができる。標的人物のセマンティック情報を獲得するために、conditional variational autoencoderおよびattentionモジュールを組み合わせた。提案モデルはCASIA-WebFaceによって学習され、LFWによる評価が行われた。先行研究stAdvやGFLMと比較し、十分な攻擊成功率を達成した。また視覚的類似度や類似スコア、異なる人物での認識精度といった評価基準によってA3GNの評価を行い、優れた性能を示した
Debらの研究
DebらはGANを利用して標的の顔画像とほぼ見分けのつかない顔画像生成手法AdvFacesを提案した。本手法は顔面における隆起した領域に最小限のpertubationを加えて敵対的顔画像サンプルを生成する手法である。モデルの構成は通常のGANネットワークにface matcherを組み込み敵対的マスクを生成し、画像に合成することで敵対的顔画像サンプルを取得できる。CASIA-WebFaceデータセットで学習を行い、LFWデータセットで評価したところ、提案手法はmodel-agnosticであり、他モデルに対しても転移可能であるため、複数の現代の顔照合手法を回避できることを示した。
4.3 特性別に分類した敵対的攻撃手法の比較
本節では、敵対的攻撃手法を特性ごとに比較する。
4.3.1 敵対的能力
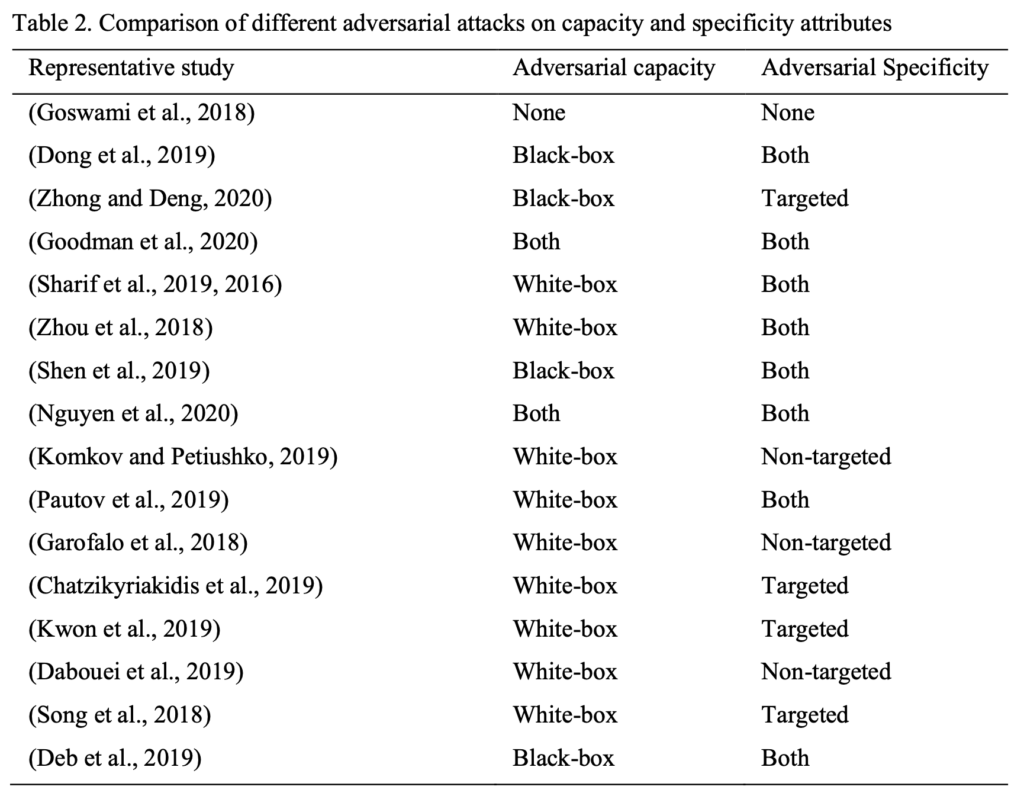
上記表は、敵対的攻撃手法の主要2特性である敵対的能力と敵対的特異性をまとめたものである。敵対的能力に関しては、攻撃生成手法のほとんどがホワイトボックス攻撃であることがわかる。ブラックボックス攻撃のシナリオでは、CNNモデルを対象にDongら (2019) ブラックボックスのdecision based攻撃設定を検討し、迅速に収束させ、微小なノイズで標的モデルをご識別させることを示した。 Zhong and Deng (2020) は、商用APIに対するブラックボックスの敵対的攻撃を設計し。CNNベースの顔認識モデルに対する特徴量レベルの敵対的サンプルの転用性能を調査した(4.3.3節参照)。Goodmanら (2020) は、顔認識システムに対するブラックボックス攻撃を行えるAdvboxツールボックスを提案した。物理的指向型の攻撃手法を提案したシェンら (2019) は、ブラックボックス顔認識システムに対するVLAを提案し、Nguyenら (2020) ホワイトボックス攻撃およびブラックボックス攻撃の両設定を考慮したリアルタイムの光投影ベースの攻撃に着目した研究を行った。幾何学指向型の攻撃では、Debら (2019) AdvFacesの敵対的な顔合成手法によって生成された顔画像は、前例のない高い攻撃成功率を達成しながら、複数のブラックボックスの顔認証技術を回避できることを示した。
4.3.2 敵対的特異性
上記表より、敵対的特異性をほとんどの攻撃方法が標的型および非標的型を兼ね揃えていることが分かる。 したがって、この特性に関して一般化が実際に考慮される。 実装が容易な非標的型攻撃では、Komkov and Petiushko(2019)は、帽子への紙のステッカーの投影を認証の回避目的に提案した。Garofaloら(2018)ポイズニング攻撃手法の提案し、Daboueiら(2019)はランドマークを使用した敵対的サンプル生成アルゴリズムの処理速度の向上を追求した。
4.3.3 転用性能
攻撃方法の転用性能に関して、いくつかの研究によって調査された(Deb et al., 2019; Komkov and Petiushko、2019; Zhong and Deng、2020)。Zhong and Deng(2020)は、CNNベースの顔認識モデルの転用性能の高い敵対的サンプルに対する脆弱性を調査し、特徴量レベルの攻撃手法がラベルレベルの手法よりも転用性能が高いことを示した。 提案したDFANet手法が、既存の攻撃方法の転用性能を向上させる可能性を示唆した。Komkov and Petiushko(2019)は、再現可能なAdvHat手法を提案し、帽子への紙のステッカーを投影することでFace認証モデルのLResNet100E-IRを簡単に混乱させ、他のFaceIDモデルに転用可能であることを示した。 Debら(2019)はAdvFacesの敵対的な顔画像の合成方法で生成された敵対的顔画像は、モデルにとらわれず転用性能が高く、複数のブラックボックスの最新顔認識システムを回避できることを確認しました。
4.3.4 摂動の汎用性
Universal perbutationは、実世界にアプリケーションに対して有効な敵対的サンプルを生成することを容易にするもの、本稿で調査したすべての攻撃手法は、特定の画像に囚われた摂動を生成する。 顔認識モデルに対するUniversal Pertubationの生成は、将来的に期待できる研究領域であり、入力画像の変化に頑健なノイズの生成手法は大いに価値がある(6節参照)。
5. 敵対的サンプルに対する防御手法
敵対的サンプルを作成するための新しい手法が提案されているため、標的となるディープネットワークのパフォーマンスへの影響を緩和することを目的とした攻擊者を対峙する研究も盛んに行われている。 リスクの潜む顔認識モデルのセキュリティを強化するために、いくつかの防御手法が提案されている。
5.1 防御手法の目的
防衛戦略の目的は、一般的に次のように分類できる。
1)モデルアーキテクチャの保存は、敵対的な例に対する防御手法を構築する際に考慮される主要な考慮事項です。 この目的では、モデルアーキテクチャに最小限の変更を加える必要がある。
2)精度の維持は、分類出力にほとんど影響を与えないようにするために考慮される主要な要素です。
3)モデル速度の保存は、次の展開によるテスト中に影響を受けてはならないもう1つの要素です。
大規模なデータセットに対する防御手法。
5.2 防御手法

| 著者 | 防御カテゴリ | 説明 |
|---|---|---|
| Agarwal et al., 2018 | 学習および評価画像の加工 | 画像の輝度値およびPCA、SVMを使用した敵対的サンプルの検知手法を提案。 |
| Kurnianggoro et al., 2019 | 学習および評価画像の加工 | 入力へ画像処理を行い識別のアンサンブルを行うことで敵対的サンプルを検知する手法を提案。 |
| Goswami et al., 2019 | ネットワーク構造の変更 | 畳込みの出力の一部を特徴づけながら異常を検知し、ドロップアウトさせることで敵対的サンプルによる影響を軽減させる手法を提案。 |
| Goel et al., 2019 | ネットワーク構造の変更 | ネットワークをブロックチェーン技術で用いられる構成要素に置き換えネットワークの異常を検知する手法を提案。 |
| Su et al., 2019 | ネットワーク構造の変更 | 敵対的摂動を除去するResGNモデルを提案、パラメータ最適化のために各種ロスを採用(pixel loss, texture loss and a verification loss)。 |
| Zhong & Deng, 2019 | ネットワーク構造の変更 | 摂動の検知および罰則化を目的としたMTER項を識別器の目的関数へ追加する手法を提案。 |
| Massoli et al., 2019 | ネットワーク構造の変更 | 入力に対する中間層の特徴表現を利用して摂動の変化を確認し検知する手法を提案。 |
| Kim et al., 2020 | ネットワーク構造の変更 | モバイルデバイスの認証アプリケーション向けの省電力で安全な顔認証プロセッサを提案。 |
| Xu et al., 2017 | 外部ネットワークによる補完 | 色深度の削減および空間的スムージングを行い特徴量を圧縮し、敵対的サンプルを検知するモデルを提案。 |
| Goel et al., 2018 | 外部ネットワークによる補完 | サンドボックスツールボックスの開発。 |
| Tao et al., 2018 | 外部ネットワークによる補完 | 入力画像の顔属性とネットワーク内部のニューロンの双方向推論を行うAmI手法を提案。 |
| Theagarajan & Bhanu, 2020 | 外部ネットワークによる補完 | 敵対的摂動を除去する反復処理を行いブラックボックス顔認証システムを防御する手法を提案。 |
上図のとおり、一般的に敵対的攻擊に対する防御手法は3つのカテゴリーに分類できる:
- 学習および評価画像の加工(例として、敵対的サンプルを学習時や評価時に使用するなど)
- ネットワーク構造の変更(層の数やサブネット、損失関数、活性化関数の変更)
- 外部モデルによる補完(未知な画像を分類する際に対して使用)
- カテゴリ2と比較して、元のモデルには変更を加えない利点がある。
5.2.1 学習および評価画像の加工
Agarwalらの研究
Agarwalらはモデルに依存しないUniversal Pertubationを効率的に検知し特定する敵対的サンプルの検知手法を提案した。本手法は画像のピクセル値およびPCAによって得られる写像をSVMに与えることで摂動を検知する。著者らは2つの摂動アルゴリズム universal pertubationおよびその派生であるfast feature fool[78]に対して実験を行い、3つの顔情報データベース(MEDS, PaSC, and Multi-PIE)を用いて4つのDNNアーキテクチャ(VGG-16, GoogLeNet, ResNet-152, and CaffeNet)に対して実験をおこなったところ、敵対的摂動の検知において提案手法が従来の手法と比べてより高い検知率が得られることがわかった。
Kurnianggoroらの研究
Kurnianggoroらは防御手法として、ドメイン変換を行った画像をアンサンブルモデルに与えて分類する手法を提案した。画像はまずグレースケールに変換され、クロップと回転処理が行われアンサンブルモデルの分類器に与えられる。本手法はモデルの再学習を行う必要がなく、VGGFace2データセットでの実験より、顔画像認証システムにおいてドメイン変換は敵対的攻擊を抑制するのに有効であることが確認できた。
5.2.2 ネットワーク構造の変更
Goswamiらの研究
Goswamiらは2つの防御手法を提案した。それぞれCNNの中間フィルタの情報を利用し敵対的摂動を検知するアルゴリズムおよび、特定のDropout手法を用いた摂動の効果を軽減させる手法である。前者の防御手法では、CNNの各層における元画像と対応する歪んだ画像の中間表現を比較した。この中間表現の差を利用し、両者を識別する分類器を学習させた。後者では、敵対的摂動の効果を軽減させるために、CNNの中間層においてノイズ付与データの影響を最も受けているフィルタをDropout処理により取り除いた。その後、通常のネットワークとの比較を行った。VGG-FaceおよびLightCNNネットワークを用いて、ノイズの検知と軽減手法の実験を行った。学習にはMulti-PIEデータベースを用い、評価にはMEDSおよびPasC、MBGCデータベースを使用した。実験より、わずかな偽陽性率と高い真陽性率を得ることができた。軽減手法の副次的な効果として、一定の割合で中間表現を取り除くことで認識精度を向上できることが確認できた。
Goelらの研究
Goelらはブロックチェーンのセキュリティ技術を用いて、顔認証モデルの防御手法を提案した。CNNの各ブロックをブロックチェーン上の構成要素に置き換えることで、分散システムの設定においてモデルはフォルトトレランス性を有することを示した。提案手法の特徴として、ネットワーク上の特定要素が改ざんされた際、システム全体に知らされる検知機能をもつ。提案ネットワークはMulti-PIEおよびMEDSデータベースにおいて、ディープラーニングモデルおよび生体認証用のテンプレートに対して高い安全性を有することが確認できた。
Suらの研究
Suらは顔認証タスクを対象に画像の敵対的摂動を取り除くdeep residual generative network (ResGN)を提案した。またResGNおよびVGG-Face、FaceNetを結合した学習フレームワークを提案した。VGG-FaceとFaceNetがそれぞれ有するtexture lossとverification lossを学習に組み込むことで、摂動除去済みの画像の認証性能を向上させる効果がある。提案手法の効果はLFW benchmark datasetによって検証された。
ZhongとDengの研究
ZhongとDengは特徴空間における局所領域の滑らかさを修復するために、モデルの目的関数にmargin-based triplet embedding regularizaiton (MTER) 正則化項を加え敵対的サンプルの影響を受けにくいモデルを提案した。正則化項では二段階の最適化を行い、摂動を検知した後に大きなマージンをとっているものに対して罰則を課す。CASIA-WebFaceおよびVGGFace2、SCeleb-1Mデータセットを用いた実験より、提案手法は頑健性を向上させ、特徴レベルおよびラベルレベルの敵対的攻擊に対して有効であることを示した。
Massoliらの研究
Massoliらは入力から得られる特徴表現に着目し、敵対的サンプルの検知手法を提案した。特定のネットワークの層の出力にaverage poolingを行い単一のベクトルを取得し、そのベクトルと各クラスのセントロイドとの距離embeddingを敵対的サンプル検知器へ与えた。著者らはMLPベースとLSTMネットワークの2種類の検知器を提案し、VGGFace2データセットとSe-ResNet-50を対象に実験を行った。提案手法を評価するために、各アーキテクチャに対するターゲット攻擊および非ターゲット攻擊のROC曲線を示した。ターゲット攻擊に対して両検知器は近いAUCが得られたが、非ターゲット攻擊に関してはLSTMネットワークの検知性能がMLPベースのものと比較して大幅に優れていた。
Kimらの研究
Kimらはモバイルデバイスの認証アプリケーション向けの省電力な顔認証プロセッサを提案した。提案したプロセッサは3つの特徴を有し、それぞれ(1) 敵対的攻擊手法および省電力を目的として採用したbranch net-based early stopping FR (BESF) 手法 (2) 外部メモリアクセスを節約するためのlayer fusionを組み合わせたpoint及びdepth-wise畳み込み演算を行う統一された処理要素 (3) 敵対的攻擊手法に対して頑健性を有し外部メモリアクセスを抑えるためのボトルネック構造に組み込まれたnoise injection layer (NIL)。FGSMおよびPGD攻擊の状況下において、提案手法は高い識別性能を保ちつつ、平均消費電力を著しく抑えられることを証明した。提案プロセッサはLFWデータセットに対して95.5%の顔認証精度を有する。
5.2.3 外部ネットワークによる補完
Xuらの研究
Xuらは単一画像を多数の特徴ベクトルと対応させ敵対的サンプルを生成するための探索空間を削減する手法を提案した。これを実現するために2つの外部ネットワークを分類器に加えた。分類器の前段部にはそれぞれ独自の前処理が施され、各ピクセルの色深度の削減および空間的スムージングが入力に対して行われる。本手法は高解像度画像においては有効であるが、現実世界の顔認識システムのように低解像度の画像を扱う場面においては機能しない恐れがあると類似研究に指摘されている。
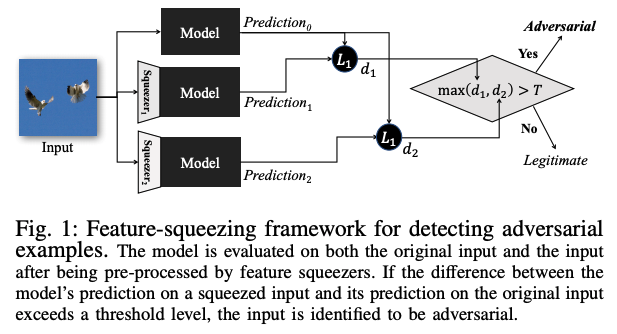
Pythonによって記述されているツールボックスSmartBoxは敵対的攻擊に対する検知手法や防御手法を評価するベンチマーク機能を持つ。ツールボックスに含まれる手法は畳込みフィルタの統計量による検知やPCAによる検知、アーティファクト学習、適応ノイズ軽減である。ここで、アーティファクト学習と適応ノイズ軽減は本項目の外部ネットワークによる補完に分類される防御手法である。
Taoらの研究
Taoらはニューラルネットワークの解釈可能性に注目し、Attacks meet Interpretability (AmI) を提案した。本手法は属性レベルの変化とニューロン強弱を用いて、顔属性とネットワーク内部のニューロンの双方向推論を行った。詳述するとこれらの出力は説明性を向上させるために強調されている。一方でその他の出力は弱化されモデルの解釈不能な部分を抑制した。VGGFaceデータセットおよびLFW、CelebAの3つのデータセットに対してAmIを組み込んだVGG-Faceネットワークを対象に7つの攻擊手法を行ったところ、提案手法は敵対的サンプルを検知することができた。真陽性率は94%であり、この結果は先行研究であるfeature squeezingと比較して大幅に高い結果となり、同時に低い偽陽性率を得られた。
TheagarajanとBhanuの研究
本章で述べた検知手法は主にブラックボックスな分類器を守るために特化している。しかしながら、これら手法は敵対的サンプルからノイズを取り除いたあとも、どのくらい敵対的なノイズを画像に残しているか定量的に知ることはできない。この不透明さを攻擊者は逆手に取り、認証システムを欺くために必要な最小限のノイズを調整することができる。
この問題に対してTheagarajan and Bhanuは上述したカテゴリには属さない異なる種類の検知手法に注目した。ブラックボックスな分類器を敵対的サンプルから守るために、反復処理を行いながらノイズ除去を行う手法を提案した。この手法はベイズの不確実性を用いて、ループごとのノイズ残留物を定量化しモデルを検証した。本手法の新規性は、モデルの事前知識を必要とせず反復的に防御を行い敵対的サンプルからモデルを守れる点である。MS-Celebデータセットを用いた実験より、付与された摂動の強度が異なる様々な敵対的攻擊を検知またノイズ除去できることが証明された。
6. 課題と議論
顔認識領域では、いくつかの敵対的サンプル生成方法とそれに対抗する防御手法の提案がされている中で、様々な課題を対処する必要がある。本節では、この分野を脅かす潜在的な課題をまとめ、課題を4種類に分類する。
1. 敵対的サンプルの特異性
本稿に記されているとおり、顔認識システムを誤識別させるには画像レベルおよび顔レベル、特徴レベルの敵対的サンプルの生成方法がいくつか提案されている。 ただしこれらの方法では汎化性の高い敵対的サンプルを生成することは難しく、限定された評価指標でのみ良好な精度を出す。これらの評価指標は、主に3つのカテゴリに分類される。敵対的サンプルの生成成功率および顔認識モデルの堅牢性、摂動の量や転用性能の程度である。この中で最も効果的な評価基準として知られている攻撃の成功率は、摂動の大きさに反比例すること分かっている。また顔認識モデルの堅牢性は、分類の精度と密接に関わっている。より顔認識モデルの設計が優れているほど、敵対的サンプルに対する脆弱性は少なくなる。攻撃手法の性質に関して言及すると、極端に小さい摂動は敵対的サンプルの生成が難しい一方で、大きすぎる摂動は人間によって違いが視認できる。従って、敵対的サンプルを生成するアルゴリズムと人間の視覚系に基づいてバランスよく調整する必要がある。また一定の範囲における摂動に関して、摂動が強いほど転用性能が高いことが知られている。これらの情報を踏まえ、元画像に与える摂動の量および識別モデルの設計は極めて重要である。
同様に、調査した研究に記載されている顔画像の撮影条件が、実世界と比較すると限定的であることが確認できた。つまり、多くの顔画像が照明やカメラとの距離などの条件が整った環境下で撮影されている。実用化にあたって、撮影環境に頑健な攻撃手法が求められる。
上記の問題は、防御側が一般化された敵対的サンプル検知システムを設計することを妨げ、限定された攻撃に対する非効率的な防御手法の提案を促す。このような課題を解決するためには、統一化されたベンチマークを用意し、包括的な実験設定を検討する必要がある。 これにより共通化された評価指標によって測定され、敵対的サンプル生成手法の能力を公平に報告することができる。また研究は次の3つの評価軸に焦点を当てる必要があると考える。(1)元画像に与えられる摂動の量、(2)対象となる顔認識モデルのアーキテクチャの設計(3)生成された敵対的サンプルの転用性能。表IIに示されているように、ブラックボックス環境下での敵対的攻撃に対する既存の顔認識モデルの脆弱性はあまり研究されておらず、転用性能の調査が不足していることが明らかになっている。
2. 顔認識モデルの危険性
深層学習に基づく顔認識システムの誕生により多くの恩恵を受けたものの、結果としてそのシステムを標的とする攻撃手法の高度化が起きた。例として、画像の歪みに基づく敵対的攻撃を実装すると、同じ評価データに従来手法を用いた市販の製品を適用した場合と比較して、深層学習ベースのシステムの識別性能が大幅に低下してしまう。したがって、これらの攻擊に対して頑健なアーキテクチャの設計が強く推奨される。敵対的サンプルの汎用性を高めるために堅牢なモデルを開発する必要性は既に前段落で述べている。より多くの研究が行われるブラックボックス攻撃に講じる策の重要性を説く際に必要であるため改めて述べる。現状、より堅牢な顔認識モデルを開発するためのセキュリティ上の懸念が残る。
3. 人の視覚システムからの逸脱
視覚システムに対する敵対的攻撃手法は、システムが人間では知覚できない画像の微小な変化対して強く影響を受ける性質を利用する。人間とより似た視覚的な判断を行うアルゴリズムを開発することを推奨する。特に、ピクセルの強度ではなく特徴に基づいて画像を分類するアプローチはより実用的になる可能性が高い。このようなアプローチは、性別や人種、年齢、髪の色などの外観の記述可能な側面の有無を認識し、顔画像の高レベルの視覚的特徴または特性を抽出して比較するように分類器をトレーニングすることが考えられる。またはポーズや照明、人間の表情、その他の画像条件に対して高い頑健性を持つ必要がある。また視覚生理学の知見によって、新たな研究の可能性をもたらすことも考えられる。例を挙げるとVLAは、物理的な敵対的攻撃の実装の成功を実証し、その設計では人間の視覚系を再現するする試みが行われた。
4. 画像に依存しない敵対的サンプル生成手法
既存の敵対的サンプルの生成方法は、画像にとらわれたものが実証されており、顔認識モデルに対するUniversal perbutationの生成に関する研究が少ないことが確認できた。異なる標的モデルを同時に攻撃することのできる性質は、Universal perbutationを生成することの副産物であり、多くの研究において懸念すべき存在と述べられている。
7. 終わりに
本稿では、深層学習に基づく顔認識システムを標的とした敵対的攻撃手法の包括的なサーベイを行い数々の文献を紹介した。高度な顔認識モデルの卓越したパフォーマンスにもかかわらず、それらを人の目では知覚できないレベルで出力を操作する「敵対的な入力画像」に対して脆弱であった。敵対的攻撃手法に関する脆弱性が露見したことにより、多数の対策手法の研究などの取り組みを助長している。
本稿では、数ある文献の中で効果的で興味深い研究を対象に批評を行った。既存の攻撃および防御方法のタクソノミーは、敵対的攻撃手法の様々な特性に基づいて提案した。また敵対的サンプルの現在の課題および考えられる解決策についても述べた。
Appendix. 敵対的サンプル生成手法の詳細
本節では、FRモデルに対する主な敵対的サンプルの生成方法を紹介する。
1) Image-level Grid-based Occlusion
特定の画像に依存せず任意の画像に適用できる摂動を加える画像処理は、画像レベルのノイズとして分類される。Goswamiら (2018) はGrid-based Occlusionと呼ばれる画像レベルのノイズを提案した。本手法ではパラメータ$\rho_{grids}$ に従い、複数の点$\textbf{P} = {p_1,p_2,…,p_n}$が画像の左上$(x=0, y=0)$の境界に沿って選択される。$\rho_{grids}$パラメータは画像を加工する上で使用されるグリッド数を決定し、この値を増加させることでよりグリッド線の多い密な格子模様が生成される。各点 $\rho = (x、y)$に対角な点$p’$が $y_i=0, x_i=0$ then $y’_i=H, x’_i=W$の条件を満たすように選択される。対となる$\textbf{P}$および$\textbf{P’}$が決定した後に、幅が1に設定された輝度値0の直線が各点を結ぶように元画像へ描画される。
2) Image-level Most Significant Bit-based Noise (xMSB) Distortion
Image-level Most Significant Bit-based Noise (xMSB) DistortionもGoswamiら (2018) によって提案され、本手法では3組のピクセル$X_1,X_2,X_3$が$|X_1|=\varnothing_i \times W \times H$を満たすように確率的に選ばれる。ここで$W \times H$は入力画像サイズであり、パラメータ$\varnothing_i$は上位$i$ビットが反転されたピクセルの割合を表す。その結果、$\varnothing$ がより高い値をとると、より多くの上位$i$番目のビットに歪みが加わる。それぞれの$\textbf{P}j\in\textbf{X}\textbf{I},\forall\in[1,3]$に対して下記の操作が行われる:
\[ \textbf{P}{kj}=\textbf{P}{kj}\oplus1 \tag{10}\label{10} \]
ここで、$\textbf{P}{kj}$ はj番目のピクセルの$k$番目の最上位ビットを示し、$\oplus1$はXOR演算子を表す。加えて、$\textbf{X}\textbf{I}$は重複することもあり、それゆえに歪みによって影響を受けたピクセルの総数は$|X_1+X_2+X_3|$以下になる。
3) Face-level Distortion
画像レベルのノイズの他にGoswamiら (2018)は顔レベルのノイズも提案した。これは顔のランドマークといった顔の情報を明示的に与える必要がある。従って本手法は顔およびランドマークの自動検知を前処理として行い、顔ランドマークが検知された後にマスキング処理が行われる。例として目の領域を覆う場合、次式で長方形領域を画像上に描画する。
\[ I{x,y}=0,\forall x\in[0,W],y\in \left[ y_e-\frac{d_{eye}}{\psi}, y_e+\frac{d_{eye}}{\psi}\right] \tag{11} \label{11} \]
ここで、$y_e=\left(\frac{y_{le}+y_{re}}{2}\right)$であり、$\left(x_{le},y_{le}\right)$および$\left(x_{re},y_{re}\right)$は左目と右目の中心を指す座標である。$d_{eye}$は目の内側の距離$x_{re}-x_{le}$であり、$\psi$は長方形領域の幅を調整するパラメータである。本手法と同様にEye Region Occlusion (ERO) 処理によって額や眉の領域を覆うマスキング処理を行うことができる。また上記手法を応用することで髭領域やその他の任意の部位をマスキング処理によって覆うことができる。
4) 進化的攻擊
Dongら (2019) は共分散行列適応進化戦略 (CMA-ES)の派生である(1+1)-CMA-ESに基づく進化的攻擊手法を提案した。(1+1)-CMA-ESの各更新処理においてノイズが付与され、現在の解より候補解が生成され、両者が評価された上でより良い方が次の反復処理に使用される。本手法は次式で表すブラックボックス最適化問題を解くことができる。
\[ \min_{x’} \textbf{L}\left(\bm{x’}\right) = |\bm{x’}-\bm{x}|_2 + \delta \left(C\left(F\left(\bm{x’}\right)\right)=1\right) \tag{12} \label{eq12} \]
ここで$C\left(.\right)$は2値の敵対的評価関数であり、攻擊条件が満たされた場合1をとりそれ以外は0をとる。$\delta$は$a$が真なら0であり、偽なら$+\infty$をとる。しかしながら、$\bm{x’}$が高次元なため、(1+1)-CMA-ESを用いて 式.$\eqref{eq12}$ の最適化を行わなかった。アルゴリズムの高速化を図るため、ガウス分布からランダムノイズをサンプリングし、サンプリングされた敵対画像と元画像の距離の最小化を行った。また著者らはこの問題の特性を活かすことで、探索空間の次元を縮小する手法を提案した。$m<d$の低次元空間$R^m$にてランダムノイズのサンプリングを行い、ノイズベクトルを元の空間に投影するためにバイリニア補完を行った。この手法により、入力画像の次元を保持しつつ検索空間の次元を縮小させた。
5) Feature Fast & Iterative Attack Methods
顔画像のペアとディープラーニングモデルを用いて、Zhong and Deng (2019)は顔画像から得られる特徴表現間の距離を利用する特徴レベルの攻撃手法を提案した。元画像と同一のラベルを持つ正の画像ペアおよび異なるラベルを持つ負の画像ペアをそれぞれ定義した。顔画像のペアを${\bm{x}^1,\bm{x}^2}$とし、敵対的サンプルを$\bm{x’}=\bm{x}^1+\bm{n}$と表し、正の顔画像$l^1=l^2$は以下の目的関数および損失関数の最適化を行った。
\[ \bm{n}=\argmax_\bm{n} |\textbf{F}(\bm{x}^1+\bm{n})-\textbf{F}(\bm{x}^2)|_2, |\bm{n}|_\infty < \varepsilon \] \[
\textbf{J}(\bm{x}^1+\bm{n},\bm{x}^2)=|\textbf{F}(\bm{x}^1+\bm{n})-\textbf{F}(\bm{x}^2)|_2 \tag{13} \label{13} \]
また負の顔画像ペア$\{\bm{x}^1,\bm{x}^2\}, l^1 \ne l^2$の場合、以下の目的関数及び損失関数の最適化を行う。
\[ \bm{n}=\argmax_\bm{n} |\textbf{F}(\bm{x}^1+\bm{n})-\textbf{F}(\bm{x}^2)|_2, |\bm{n}|_\infty < \varepsilon \] \[
\textbf{J}(\bm{x}^1+\bm{n},\bm{x}^2)=-|\textbf{F}(\bm{x}^1+\bm{n})-\textbf{F}(\bm{x}^2)|_2 \tag{14} \label{14}\]
ここで$\mathcal{F}(\bm{x’})$は正規化されたモデルから得られた特徴表現であり、$\varepsilon$は摂動の採りうる範囲を制限する。式$\eqref{13}$および式 $\eqref{14}$の損失関数に基づいて敵対的摂動を生成する手法はFeature Fast Attack Method (FFM) と呼ばれ次式で定義されている。
\[ \bm{x}^1+\bm{n}=\textbf{G}{\bm{x}^1,\varepsilon}\left(\bm{x}^1+sign\left(\nabla{\bm{x}^1}\textbf{J}\left(\bm{x}^1,\bm{x}^2\right)\right)\right) \tag{15} \]
著者らはこれに反復処理を導入したFeature Iterative Attack Method (FIM) を提案し、次式で表す。
\[ \bm{n}0=0 \] \[ g{N+1}=\nabla_{\bm{x}^1+\bm{n}N}\textbf{J}\left(\bm{x}^1+\bm{n}_N,\bm{x}^2\right) \] \[
bm{x}^1+\bm{n}{N+1}=\left( \bm{x}^1+\bm{n}N,sign\left(g{N+1}\right) \right) \ \tag{16} \]
ここで$\textbf{G}_{\bm{x}^1,\varepsilon}=\min(255,\bm{x}+\varepsilon,\max(0,\bm{x}-\varepsilon,\bm{x’}))$である。反復処理はヒューリスティックに決定する$\min(\varepsilon+4,1.25\varepsilon)$。
6) Eyeglass Accessory Printing
Sharifら (2016) は実世界で有効なdodging攻擊やなりすまし攻擊を提案した。実世界で実現するための最初のステップとして、3Dまたは2D印刷技術を利用し、顔の付属品(具体的には眼鏡フレーム)を装着して攻撃を実施した。容易に利用できる市販のインクジェットプリンターを使用し、眼鏡フレームを型取り光沢紙に印刷し、実際の眼鏡フレームに貼り付けた。位置合わせ後、224×224の顔画像におけるフレームの占有面積を約6.5%の範囲に留めた。なりすまし攻擊やdodging攻擊を実現するために必要なフレームの色を見つけるために、フレームの色が単色 (黄色など) に初期化され、フレームが被写体の画像にレンダリングされる。それらの色は、最急降下法によって繰り返し更新され、フレームを物理的に装着したときのわずかな自然な動きに耐える敵対的な摂動を作り出した。続くステップでは画像の撮影環境から影響を受けない頑健な敵対的摂動の生成を試みた。あらゆる画像に対して付与できる単一の敵対的摂動を求めるために以下の最適化問題を定式化した。
\[ argmin_n \sum_{x\in X} softmaxloss \left( \textbf{F}\left(\bm{x+n}\right),l\right) \ \tag{17} \]
摂動の持つ滑らかさを保持するために、次式で定義されているTotal Variation (TV)を最適化に加えた。
\[ argmin_n \sum_{x\in X} softmaxloss \left( \textbf{F}\left(\bm{x+n}\right),l\right) \ \tag{17} \]
摂動の持つ滑らかさを保持するために、次式で定義されているTotal Variation (TV)を最適化に加えた。
\[ TV\left( \bm{n} \right) = \sum_{i,j} \left( \left( \bm{n}{i,j} – \bm{n}{i+1,j} \right)^2 + \left( \bm{n}{i,j} – \bm{n}{i,j+1} \right)^2 \right)^{1/2} \tag{18} \]
ここで $\bm{n}_{i,j}$ は摂動 $\bm{n}$ の位置 $(i,j)$ における画素値を表す。隣接する画素値が近い場合、$TV(\bm{n})$ は小さい値をとりなめらかな摂動となるため、$TV(n)$ を最小化することで実用性が向上する。
7) Visible Light-based Attack (VLA)
Shenら (2019) はFRシステムに対するVisual Light-based Attack (VLA) を提案した。これは可視光を用いて敵対的摂動を人間の顔に直接投影する手法である。敵対的サンプルごとに、摂動フレームと隠蔽フレームを生成し、2つのフレームをユーザーの顔に投影して実現する手法である。摂動フレームには、入力ユーザーの顔の特徴を標的型もしくは非標的型に応じて本人以外のユーザーの特徴に変更する情報が含まれ、隠蔽フレームは、摂動フレーム内の摂動が人間の目で視認されないようにすることを目的としている。
摂動フレームの生成に関して、実世界の環境下で起こり得る摂動の劣化を避けるために、ピクセルレベルの画像修正から領域レベルへ広げた。したがって、摂動フレームは、含まれる色値の類似性に基づいて排他的な領域分割される。 MeanShiftクラスタリングを用いてすべての色に対して分割を行った。ここで、近くの類似した色は同じ領域に分割され、画像内の同じ色の近くのピクセルの各グループは1つの摂動領域と見なされる。続いて領域フィルタリング戦略を使用して、カメラが投影された摂動フレーム内の微細な情報を正常にキャプチャできるようにし、物理的なシナリオで撮影された画像で色の小領域が失われないようにする。$\bm{n} = \bm{x’}-\bm{x}$を摂動フレームとして表すと、$\bm{n}$のクラスタリングとフィルタリングの結果は$\textbf{C}_{\bm{x}、\bm{x’}}$ で表され、次のように定義される。
\[ \textbf{C}_{\bm{x}、\bm{x’}}={G_i(p),R_i|0\le i\le m} \tag{19} \]
ここで、$Gi(p)$はピクセル$p$の色を$R_i$として設定する可否を決定し、$m$は色領域の総数を表す。各ピクセル$p$について画像では、$Cx、x ‘、Gi(p)$は$Ri$内にある場合は$1$、それ以外の場合は$0$とする。次に、生成関数$H(\cdot)$を定義して、次式のようにクラスタリング結果$Cx、x’$を摂動フレーム$n$に変換する
\[ \bm{n}=\text{H}(\textbf{C}_{\bm{x}、\bm{x’}})=\left[R_i\text{ if }G_i(p)=1\right] \tag{20} \]
摂動フレームを人間の目から知覚できないようにするために、Persistence of Vision (POV) の効果に従って隠蔽フレームが生成されまる(Zhang et al.,2015)。POVによると、交互に切り替わる2つの色光により、人間の脳はこれらの変化が発生した瞬間に直接処理されず、人間の目はそれらの色の混合色を認識する。この錯覚を用いて、摂動フレームと隠蔽フレームを交互に投影することで、人間の目は摂動フレームを視認することが困難になる。
8) AdvHat Attack
AdvHatと呼ばれる再現可能な敵対的攻撃生成方法を提案した。標準のカラープリンターで長方形のステッカーを印刷し、変換アルゴリズムを使用して被写体の帽子に貼り付けた。提案されたアルゴリズムは2つのステップに分けられる。まずステッカーの各点を放物線円柱上の新しいポイントにマッピングするための3D空間での放物線変換が行われる。(2)次に、得られた新しい点に3Dアフィン変換を適用することでステッカーのピッチ回転を行った。著者らは上述の手順で得られたステッカーに微小の摂動を加え高品質の顔画像に投影しました。彼らは新しい顔画像をArcFace入力に合わせ変換し、最適化を行った。最適化のステップでは、ステッカー画像の変更に使用される勾配情報を得るために、TV損失および埋め込み表現間のコサイン類似度の合計を次式のように表した。
\[ \tag{21}
\text{L}\text{T}(\bm{x’}, \bm{a}) = \text{L}\text{sim} (\bm{x’},\bm{a}) + \lambda \cdot TV(patch) \]
ここで、$L$は総損失、patchはステッカー、$x’$はステッカー適用後の写真、$\lambda$はTV損失の重みであり、この作業では$1e^{−4}$と想定される。 ここで$L_{sim}$は、埋め込み表現間のコサイン類似度であり、次のように定義される。
\[ \tag{22} \text{L}\text{sim} (\bm{x’},\bm{a})=\cos(e\bm{x’},e_\bm{a}) \]
ここで$e_\bm{x’}$は攻撃者の顔画像の埋め込みを取得し、$e_\bm{a}$はArcFaceによって計算された目的の人物の顔画像の埋め込みを指す。
9) Penalized Fast Gradient Value Method (P-FGVM)
Chatzikyriakidisら(2019)は敵対的攻撃手法Penalzed Fast Gradient Value Method (P-FGVM) を提案した。これは画像空間で行われ、元の画像と同様に匿名化された敵対的顔画像を生成する。本手法は、最急降下法の更新式に敵対的損失とRealism損失項を組み合わせるという点を除いて、前述したI-FGVMに類似している。 この方法では、標的となる敵対的サンプル$x’$が、次式の最急降下法の更新によって生成される。
\[ \tag{23}
\bm{x’^{(i+1)}} = Clip_\grave{o}{\bm{x’^{(i)}} + \alpha\cdot (\nabla_{x’^{(i)}}\textbf{J} (\bm{\theta},\bm{x’}^{(i)},l)+\lambda(\bm{x’}^{(i)}-\bm{x})} \]
ここで$\lambda$は重み係数であり、$\bm{x’}^{(i)}-\bm{x}$ はリアリズム損失項である。
10) Face Friend-safe Attack
Kwonら (2019) は、微小な摂動を用いてエネミー顔認識システムを誤認識させ、許可するフレンド顔認識システムは正しく認識させる敵対的サンプル生成方法を提案した。提案された方法は、敵の顔画像を生成するために、トランスフォーマー、フレンド分類器$M_{friend}$、およびエネミー分類器$M_{enemy}$で構成される。 事前に学習させた$M_{friend}$と$M_{enemy}$、および元の入力$\bm{x}\in \bm{X}$が与えられた場合、敵対的顔画像$\bm{x’}$を生成する最適化問題は次式で表される。
\[ \tag{24}
\argmin_{x’} L(\bm{x},\bm{x’}) \]
ここで、$g_{friend}(x)$と$g_{enemy}(x)$は、それぞれフレンド分類器$M_{friend}$とエネミー分類器$M_{enemy}$の演算を示す。$L(.)$は、顔の元のサンプル$x$と顔を変換した例$x’$の間で測定された距離です。トランスフォーマーは、元のサンプル$x$とそれに対応する出力ラベルを取得して、敵対的な顔の例$x’$を生成する。$M_{friend}$と$M_{enemy}$による$x’$の分類損失はトランスフォーマーに返され、トランスフォーマーは合計損失$LT$を計算し、上記の手順を繰り返して、$LT$を最小化しながら敵対的な顔の例$x’$を生成する。これは次式のように表す。
\[ \tag{25}
L_\text{T}=L_{friend}+L_{enemy}+L_{distortion} \]
ここで、$L_{friend}$は$M_{friend}$の分類損失関数、$L_{enemy}$は$M_{enemy}$の分類損失関数、$L_{distortion}$は変換された変換された敵対的サンプルのノイズであり、$\bm{x}$と$\bm{x’}$間の距離として定義される。
11) Fast Landmark Manipulation (FLM) 手法
Daboueiら (2019) は敵対的な顔を作るための高速ランドマーク加工手法を提案した。元画像を空間的に変換することによって敵対的な例を生成することを提案しました。ランドマーク検出器関数$\mathbf{\Phi}$を使用して、顔画像$\bm{x}$を$k$個の2次元ランドマーク点$\bm{P} = … {p_1、、p_k},=p_i(u_i, v_i)$にマッピングし、$p’=(u’, v’)$が変換されたと仮定する。 $p$のバージョンであり、対応する敵対的サンプル$x’$の$i$番目のランドマーク位置を定義する。$\bm{P}$に基づいて顔画像を加工するために、ランドマークごとの変位$f$を定義し、対応する敵対的ランドマークの位置を生成する。 したがって、敵対的なランドマーク$p_i$は、元のランドマーク$p_i$から取得でき、特定の変位ベクトル$f_i =(\Delta u_i、\Delta v_i)$を次式のように最適化する。
\[ \tag{26}
p_i’=p_i + f_i \
(u_i’, v_i’) = (u_i + \Delta u_i, v_i + \Delta v_i) \]
入力画像のすべてのピクセル位置に対して$f$を定義するした先行研究(Xiao et al., 2018)とは対照的に、(Dabouei et al., 2019)は、k個のランドマークにのみ$f$を定義しました。 これは顔認識タスクのような実際のアプリケーションに組み込まれる場合、入力画像のピクセル数と比較して小さい方が好ましい。この限られた数の制御点は、空間変換によって生じる歪みも低減できる。変換$T$を使用して、良性の顔画像を次のように空間的に敵対的な顔画像に変換する。
\[ \tag{27}
\bm{x’}=T(\mathbf{P}, \mathbf{P’}, \bm{x}) \]
ここで、$\bm{P’}$は操作する点を指す。正しい分類の尺度としてSoftmax損失を組み込み、敵対的な顔を生成するための損失関数を次式のように定義した。
\[ \tag{28}
\text{L}(\bm{P},\bm{P’},\bm{x},l) = softmaxloss(\textbf{F}(T(\bm{P},\bm{P’},\bm{x})),l)-\lambda_{flow}L_{flow}(\bm{P’}-\bm{P}) \]
ここで、$\lambda_{flow}$は変位の大きさを調整するための正の係数であり、$L_{flow}$は ランドマーク変位$f$は、予測の勾配方向を使用して繰り返し検出され、FLMメソッドと呼ばれる。またこのアプローチを拡張し、各ランドマーク点を加工する代わりに、ランドマークを意味的にグループにまとめ、グループごとの特性を操作するGrouped Fast Landmark Manipulation(GFLM)手法を提案した。これはFLMによって生成された敵対的顔画像に顕著な歪みが生じていしまう問題を解決し、生成画像の構造を保持するために作成されました。