
概要
ニューラルネットワークの推論時に誤識別を招くAdversarial Attackに対する防御手法は多く提案されている。中でもAdversarial Noiseを汚染画像から取り除き正常画像を生成する方法は多くの攻撃を網羅的に対処できることから研究が盛んに行われている。現行の手法は生成モデルを用いて正常データを学習したデータ分布に汚染データを写像してノイズを取り除くという手法が採られている。 本研究では、Conditional Variational Autoencoderを生成モデルとして採用し、汚染された画像データからAdversarial Noiseを高速に高精度で取り除く方法を提案した。
論文情報
公開日
2019-03-02 (arXiv)
著者情報
Uiwon Hwang, Jaewoo Park, Hyemi Jang, Sungroh Yoon and Nam Ik Cho
Department of Electrical and Computer Engineering, Seoul National University, Seoul, Korea.
論文情報・リンク
PuVAE: A Variational Autoencoder to Purify Adversarial Examples – IEEE Journals & Magazine
新規性・差分
先行研究で用いられたAutoencoderやGANを用いたデータに対するAdversarial Noiseの除去方法に対して、本研究では特定クラスのデータ分布を考慮するconditional Variational Autoencoder(cVAE)を採用している。本アーキテクチャを用いて、事前に画像データからノイズを取り除くシステムを構築した。先行研究と比較した結果、精度および推論速度において改善が確認された。加えて、本手法はMNISTを始めとする3種類の画像データセットと4種類の攻撃手法に対して頑健性が高いことを示した。
手法
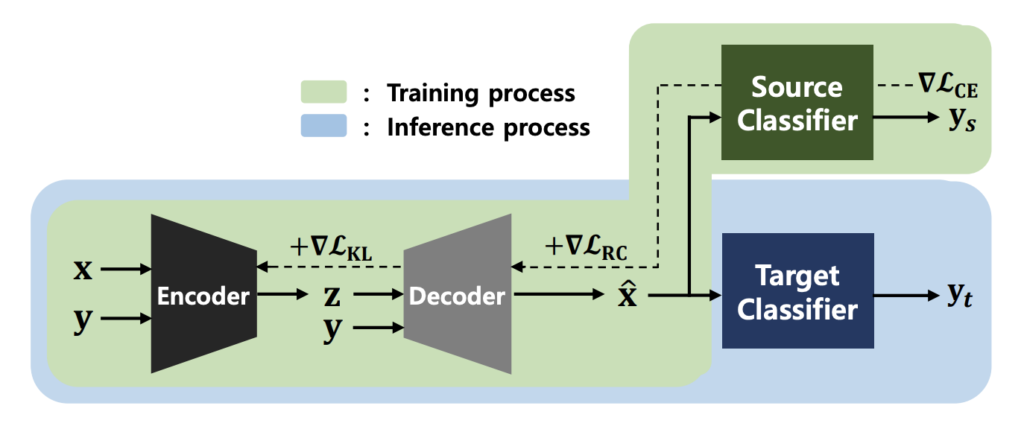
PuVAEのアーキテクチャの特徴として、cVAEに加えてアーキテクチャの後段部に各クラスの決定境界を学習する識別器を組み込みこんでいることが挙げられる。cVAEはニューラルネットワークと変分ベイズ法を組み合わせた生成モデルの一種であり、正規分布からデータを生成するようにデコーダを学習させる手法である。
PuVAEの学習方法
PuVAEの前段部のcVAEはエンコーダとデコーダの2つのネットワークから構成される。 まず、エンコーダではデータラベルペアを受け取り、入力に対応する潜在空間上のガウス分布の平均 $\mu$ および標準偏差 $\sigma$ を求める。
\[\mu, \sigma = \text{Encoder}(\mathbf{x}_\text{data},\mathbf{y}_\text{data})\]
平均と標準偏差を用いて、潜在空間上の潜在ベクトルzをサンプリングする。
\[
\mathbf{z} = \mu + \epsilon \cdot \sigma
\] \[
\epsilon \sim N(\mathbf{0}, \sigma_\epsilon \mathbf{I})
\]
ここでϵϵはVAEのReparameterization Trickに必要なランダムな変数であり、標準偏差をかけた $\epsilon \cdot \sigma$ は潜在ベクトルのサンプリング範囲を調整するためのものである。本実験では、事後潜在分布が正規分布に従うように学習時に $\epsilon \cdot \sigma = 1$ と指定している。
サンプリングされた$\mathbf{z}$はラベル生成ともにデコーダへ入力され入力と同じ次元数dの出力$\hat{\mathbf{x}}$を生成する。
\[\mathbf{\hat{x}} = \text{Encoder}(\mathbf{z},\mathbf{y}_\text{data})\]
学習の際にPuVAEはcVAEと同じ方法で変分下限を最大化する。エンコーダおよびデコーダの損失関数は以下のとおりである。
\[
\mathcal{L}_{RC} = \mathbf{x}_\text{data} \text{log} \hat{\mathbf{x}} + (1 − \mathbf{x}_\text{data}) \text{log}(1 − \mathbf{\hat{x}})
\] \[
\mathcal{L}_{KL} = \mu^2 + \sigma^2 − \text{log}(\sigma^2 − 1)
\]
ここで $\mathcal{L}_{RC}$ は入出力の誤差を最小化する再構成Lossであり、$\mathcal{L}_{KL}$ はエンコーダの出力分布と正規分布のカルバック・ライブラー・ダイバージェンスLossを指す。
上記のロスに加えて、PuVAEの後段にある識別器のクロスエントロピーLossを組み込んでいる。この識別器はデータ空間の決定境界を学習するものであり、出力画像がクラスCの特性を持つことを保証する役割を持つ。
\[
\mathcal{L}_{RC} = \mathbf{x}_\text{data} \text{log} \hat{\mathbf{x}} + (1 − \mathbf{x}_\text{data}) \text{log}(1 − \mathbf{\hat{x}})
\]
上記モデルは確率的勾配降下法によって学習される。 $\lambda$ はそれぞれの損失関数の係数を指す。
\[
\nabla(\lambda_{RC}\mathcal{L}_{RC} + \lambda_{KL}\mathcal{L}_{KL} + \lambda_{CE}\mathcal{L}_{CE})
\]
ノイズ除去画像の生成方法
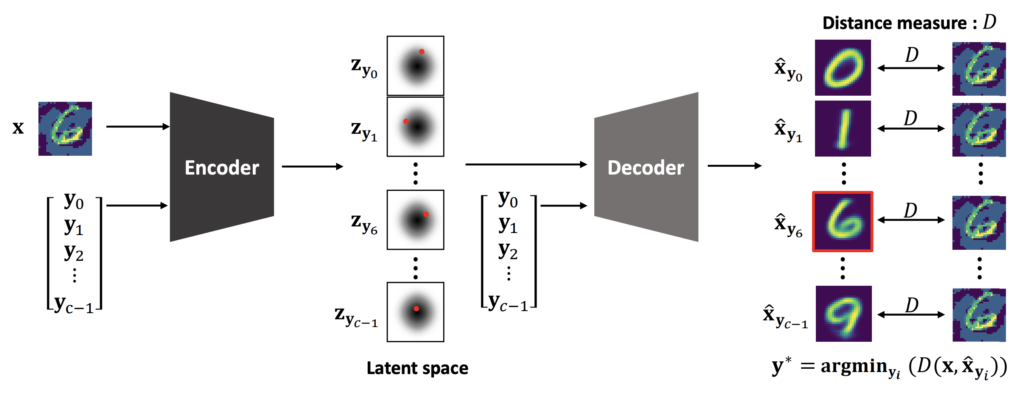
推論時にPuVAEへ与えられた入力サンプルは全クラスのデータマニフォールドに写像される。
\[
\mathbf{\hat{x}}_{\mathbf{y}_i} = \text{PuVAE} (\mathbf{x}, \mathbf{y}_{i})
\]
ここで $y_i$ は $C$ の $i$ 番目のクラスラベルを示し、これは入力を対応する潜在空間へ導くためのものである。また $\hat{\mathbf{x}}_{y_i}$ は生成サンプルの候補を示す。学習時の同様の手順(eq. 5, 6, 7)を行い $\sigma_{\epsilon}$ を用いて潜在ベクトル $z$ のサンプリングを行う。ハイパーパラメータ探索の結果、推論時に最も適切な $\sigma_{\epsilon}$ の値は0.1であった。
PuVAEは $z$ の分布を学習データのみから学習するため、Adversarial Exampleが入力された場合においても学習済みの潜在空間へ写像される。このとき、Adversarial Noiseは除去される。
その後、クラスラベルに最も近い写像が選択される。
\[
\mathbf{y^∗} = argmin_{\mathbf{y}_{i} \in C} D(\mathbf{x}, \mathbf{\hat{x}}_{\mathbf{y}_i})
\]
ここで、$D$ の選択に用いられる距離指標であり、本実験ではRMSEを用いている。したがって、ラベル $\mathbf{y^*}$ で生成された候補はターゲット識別器に与える生成サンプルである。
\[
\mathbf{x}_\text{purified} = \mathbf{\hat{x}_{y^*}}
\]
このノイズの除去された画像はもともとのターゲット識別器 $M_t$ に与えられ、通常通りに推論を行う。
\[
\mathbf{y}_t = M_t(\mathbf{x}_\text{purified})
\]
結果
下記の図に汚染データとPuVAEによってAdversarial Noiseを除去した結果を示す。対象が二値画像であるため、画像に付与されたAdversarial Noiseが視認できる。

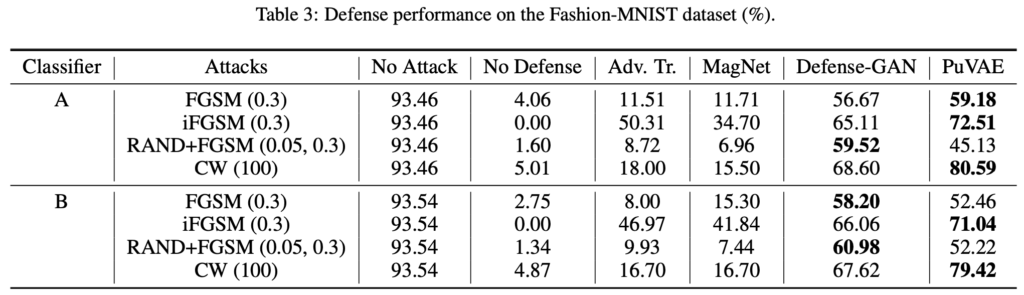
ネットワーク構成の異なる4つの識別器A,B,C,Dに対してそれぞれ4種類の攻撃手法 (FGSM, iFGSM, RAND+FGSM, CW)を使ってデータセット汚染を行った。それらに対し提案手法と3つの先行研究を適用しノイズ除去データに対する推論精度の比較を行った。各識別器のネットワーク構成は下記Supplementary Materialsから確認できる。
結果より、PuVAEは全データセットおよび攻撃手法に対して、高い水準でノイズを除去し識別精度の回復に貢献している手法であることが確認できる。
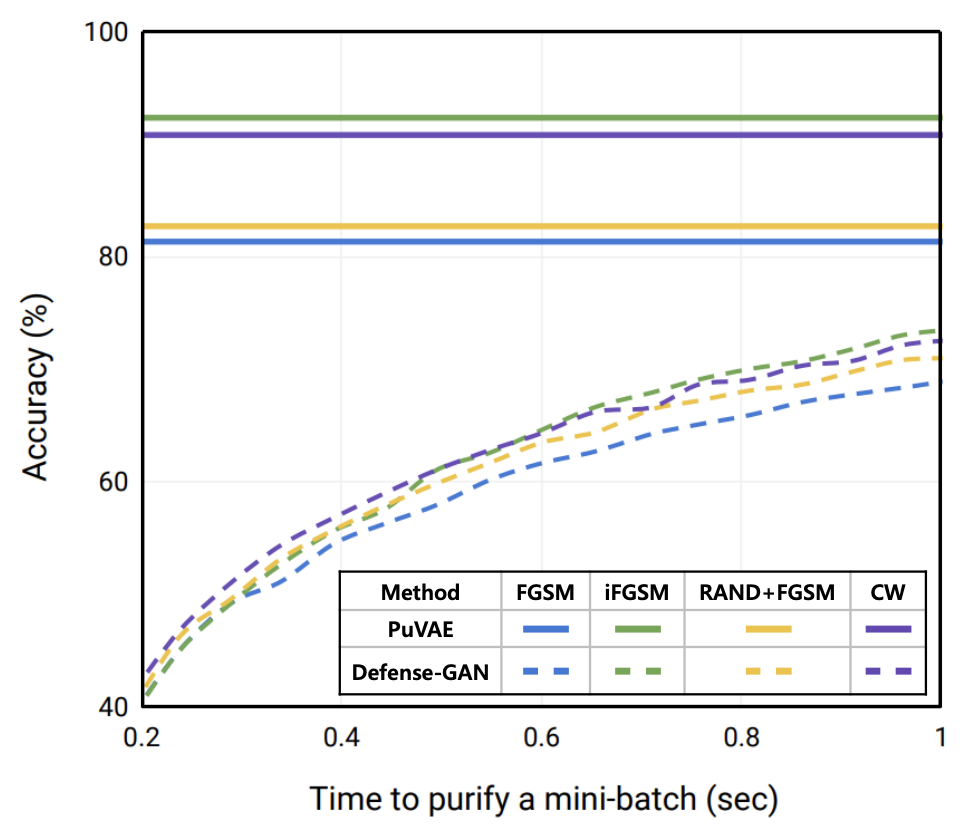
またDefense-GANとの精度および速度の比較を行った実験結果を表したグラフを下記に示す。グラフより、提案手法は時間に依存せず先行研究を上回る精度を実現したことが確認できる。PuVAEは一度の推論でノイズ除去が行えるため、実用的なアプリケーションに効率的に実装できることを著者らは述べている。
議論
本実験はMNISTといった画像サイズの小さいデータに限定されている。またRGB画像のCIFAR-10では最も多くの項目で最高精度を達しているものの、10クラス分類において平均的な精度が3割程度であることから現時点での実用利用は限られていると考えられる。
VAEのネットワークは比較的に簡素なものであるから、ネットワーク構成を拡張することでImageNet等の画像にも対応できることが期待できる。