
概要
ブラックボックス設定でDNNベースの画像分類器にバックドアを設置する攻撃手法。
その名も「Convex Polytope Attack」。
摂動を加えた画像データ(以下、汚染データ)を学習データに注入し、攻撃対象となる画像分類器に学習させることで、特定の正常データ(以下、トリガー)を攻撃者が意図したクラスに分類させることができる。なお、汚染データは見た目に違和感がないため、ラベリングなどの学習データ作成工程で異常に気付くことは困難。また、汚染データを作成する際にDropoutを適用することで、様々なアーキテクチャ(ResNet18, ResNet50, DenseNet121など)の分類器を攻撃することができる。
- 攻撃の流れ

本手法は、攻撃者が攻撃対象分類器の内部構造を知らない状態(以下、ブラックボックス)でも攻撃できるため実用性が高く、現実的な脅威になる可能性がある。
論文情報
公開日
2019-05-15
著者情報
Chen Zhu, W. Ronny Huang, Ali Shafahi, Hengduo Li, Gavin Taylor, Christoph Studer, Tom Goldstein
- University of Maryland
- United States Naval Academy
- Cornell University
論文情報・リンク
https://arxiv.org/abs/1905.05897
https://github.com/zhuchen03/ConvexPolytopePosioning
https://icml.cc/Conferences/2019/ScheduleMultitrack?event=4748
新規性・差分
学習データを汚染してバックドアを設置する手法は以前から存在する。
しかし、従来の手法は攻撃者が攻撃対象分類器の内部構造を把握している状態(以下、ホワイトボックス)を前提にしているものが多く、また、作成した汚染データの見た目に違和感が生じるという欠点もあった。
以下は、従来の手法である「Feature Collision Attack:FC」と、本論文の新手法である「Convex Polytope Attack:CP」で作成した汚染データを比較した画像である。なお、FCはホワイトボックスを前提にした手法、CPはブラックボックスを前提にした手法である。
- FCとCPで作成した汚染データの比較(論文から引用)

列「(d)FC Poisons」と列「(e)CP Poisons」に示したフックの画像は、それぞれFCとCPで作成した汚染データを示している。いずれの汚染データも、分類器に入力すると魚(Target)として分類されるように摂動が加えられている(敵対的サンプル)。この汚染データに「フック」ラベルを付けて分類器に学習させることで、Targetの魚画像を「フック」クラスに分類する決定境界が作成される。これがバックドアの原理である。
ところで、汚染データはベースとなる正常なフック画像((a)Base Images)に摂動を加えることで作成される。上図を見ると、FCで作成した汚染データには摂動により特殊な模様が現れていることが分かる((d)FC Poisons)。一方、CPで作成した汚染データは、より自然に見えることが分かる((e)CP Poisons)。このため、FCの汚染データは学習データのラベリング工程で排除される可能性が高いが(攻撃の失敗)、CPの汚染データは排除されずに学習データに取り込まれる可能性が高くなる(攻撃の成功)。
これが、本論文で提案された「Convex Polytope Attack」の新規性である。
纏めると以下のとおり。
- ブラックボックスで攻撃可能。
- 汚染データはラベリング工程で排除されにくい。
- 攻撃の汎用性が高い(詳細は後述)。
- バックドアが設置された分類器は、トリガーを攻撃者が意図したクラスに分類する。
手法
筆者らが実際に検証した結果を基に、攻撃の手順と対策を解説する。
| 注意 |
|---|
| 本ブログの内容は、攻撃の危険性と対策を理解していただくことを目的に書かれている。本ブログの内容を検証する場合は、必ずご自身の管理下にあるシステムにて、ご自身の責任の下で実行すること。許可を得ずに第三者のシステムで実行した場合、法律により罰せられる可能性があることに注意されたい。 |
検証のゴール
本検証では、Convex Polytope Attackで分類器にバックドアを設置し、特定の蛙画像を船クラスに誤分類させることをゴールとする。
これを行うために、船画像をベースに汚染データを作成し、学習データに注入する。そして、汚染された学習データを分類器に学習させることで、バックドアを設置する。
- 検証のゴール

データセット
本検証では、検証時間を短縮するためにCIFAR10を5クラスに削減した独自データセット「CIFAR5」を使用する。
CIFAR5のクラスは以下のとおり。
- CIFAR5

CIFAR5には32×32ピクセルのカラー画像が30,000枚含まれている。
本検証では、CIFAR5を以下のように分割して使用する。
| カテゴリ | データ数 | 用途 |
|---|---|---|
| 学習データ | 24,000 | 分類器の学習に使用。 |
| テストデータ | 5,000 | 分類器のテストに使用。 |
| 汚染データ作成用データ | 1,000 | 汚染データの作成に使用。 |
なお、汚染データ作成用のデータにはクラス毎に200枚の画像が含まれている。
各クラスにはあらかじめ0~4の識別IDを付与しておく。
| クラス名 | 識別ID | データ数 |
|---|---|---|
| automobile | 0 | 200 |
| cat | 1 | 200 |
| deer | 2 | 200 |
| frog | 3 | 200 |
| ship | 4 | 200 |
分類器
本検証では4つの分類器を使用する。
| アーキテクチャ | 用途 |
|---|---|
| ResNet50 | シャドウモデル(汚染データの作成に使用)。 |
| ResNet18 | 攻撃対象の分類器。 |
| ResNet50 | 攻撃対象の分類器。 |
| DenseNet121 | 攻撃対象の分類器。 |
シャドウモデルと攻撃対象の分類器は、学習データを異なるランダムシードで学習して作成する。
ここで、「シャドウモデル」という言葉を初めて聞く方もいるかもしれないので、シャドウモデルについて少し補足する。
シャドウモデル
シャドウモデルとは、攻撃者が効率よくブラックボックスな攻撃を行うために使用されるモデルであり、攻撃対象の分類器を模倣して作成される。敵対的サンプルを例にとると、通常、敵対的サンプルを作成するには、攻撃対象の分類器に関する情報(特徴抽出器など)が必要である。しかし、ブラックボックスではそれを知る由がない。そこで、攻撃者は分類器の学習データ分布などを推測し、攻撃対象の分類器に似せたシャドウモデルを手元に作成する。そして、これを使用して敵対的サンプルを作成する。
ところで、シャドウモデルと攻撃対象の分類器の学習データ分布やアーキテクチャが一致していない場合でも、有効な敵対的サンプルを作成できることが知られている。ここでは検証しないが、敵対的サンプルについて書かれた著名な論文「Intriguing properties of neural networks」には以下のように書かれている。
- とある学習データを学習したモデルの敵対的サンプルは、異なるデータで学習したモデルにも有効である。
- とあるモデルの敵対的サンプルは、異なるアーキテクチャのモデルにも有効である。
それゆえに、攻撃者はシャドウモデルを使用することで、攻撃対象分類器の内部構造を知らない状態(ブラックボックス)でも効率よく攻撃を行うことが可能となる。
汚染データの作成
繰り返しになるが、本検証のゴールはバックドアのトリガーとなる蛙画像を船クラスに誤分類させることである。
そこで、トリガー用としてテストデータから蛙(Frog)クラスの画像を1枚、汚染データのベース画像として汚染データ作成用データから船(Ship)クラスの画像を5枚を取り出す。
| クラス | 画像 | 枚数 | |
|---|---|---|---|
| トリガー画像 | 蛙(Frog) |  | 1枚 |
| 汚染データのベース画像 | 船(Ship) |  | 5枚 |
次に、シャドウモデルとベース画像、そしてトリガーを使用して汚染データを作成する。
汚染データを端的に言うと、ベース画像(船)をトリガーのクラス(蛙)に誤分類させるように摂動が加えられた敵対的サンプルである。ポイントになるのは、特徴空間においてトリガーを汚染データから成る凸集合内に配置するように汚染データを作成することである。これがConvex Polytope Attackの名前の由来である。
以下に汚染データの配置イメージを示す。
- 汚染データの配置イメージ(論文から引用)

既存手法と比較するため、左に既存手法(FC)の配置イメージを載せている。
青丸はトリガークラスのデータ、赤丸は汚染データクラスのデータ、青いストライプ柄はトリガー、赤いストライプ柄は汚染データ、そして、直線はクラスを分類する決定境界を表している。
FCは汚染データをトリガーに接近させることで、トリガーを汚染データクラスに引きずり込むように決定境界を歪ませようとする。しかし、ブラックボックスで汚染データの特徴量をトリガーに近づけることは困難であり、仮に近づけることができた場合でも上図のように攻撃が失敗する場合がある。
一方、CPはトリガーが凸集合内に配置されるように汚染データを配置することで、トリガーを汚染データクラスに引きずり込もうとする。この時、トリガーを凸集合内に配置でき、かつ、汚染データが汚染データクラスに正しく分類されるように学習できれば、トリガーと汚染データの距離が離れていても攻撃が成功することを保証する。
この「距離が離れていても攻撃は成功する」という特性により、汚染データとトリガーの特徴距離を離すことが可能となり(攻撃のハードルが下がる)、汚染データには特殊な模様が現れ難い(=攻撃が見破られ難い)というメリットを享受することができる。
汚染データの汎用性向上
より効率よく攻撃を行うために、一つのシャドウモデルで作成した汚染データで様々なアーキテクチャの分類器を攻撃することを考える。これを行うために、本論文では「汚染データ作成時にシャドウモデルにDropoutを適用」する方法を提案している。
本来、Dropoutは過学習を防いで分類精度を向上させるための手法であるが、汚染データの汎用性向上にも役立つ。Dropoutはシャドウモデルのネットワークをランダム化するが、これは深さの異なるネットワークを取得できることを意味する。よって、このようにランダム化されたネットワークで汚染データを作成することで、様々なアーキテクチャを攻撃できる汎用性を獲得することができる。
以下、本検証で作成した汚染データ(船)を示す。
- 汚染データ

これらの汚染データは、攻撃対象分類器に入力すると蛙クラスに分類される敵対的サンプルである。摂動により少しノイズが乗っているが、十分に人間の見た目には船に見える。よって、学習データ作成工程でこれらの汚染データは船クラスとしてラベリングされる可能性が高い。
汚染データを学習データに注入
攻撃者は汚染データを何らかの方法で攻撃対象分類器の学習データに注入する必要がある。
本論文では、汚染データをインターネット上で公開し、学習データの自動収集クローラーによって取り込まれることを想定している。
本検証では、何らかの方法で汚染データが学習データに取り込まれた前提で検証を進める。
バックドアの設置
上述したように、汚染データにはトリガー(Frog)のクラスに分類されるような摂動が加えられている。すなわち、船画像を蛙クラスに誤分類させる敵対的サンプルである。しかし、汚染データは人間の見た目には船に見えるため、学習データに取り込まれる際に「船」クラスのラベルが付けられることになる。
この学習データで攻撃対象分類器の学習を行うと、以下のようにクラスの決定境界(Decision boundary)が歪められることになる。
- 汚染データにより決定境界が歪むイメージ
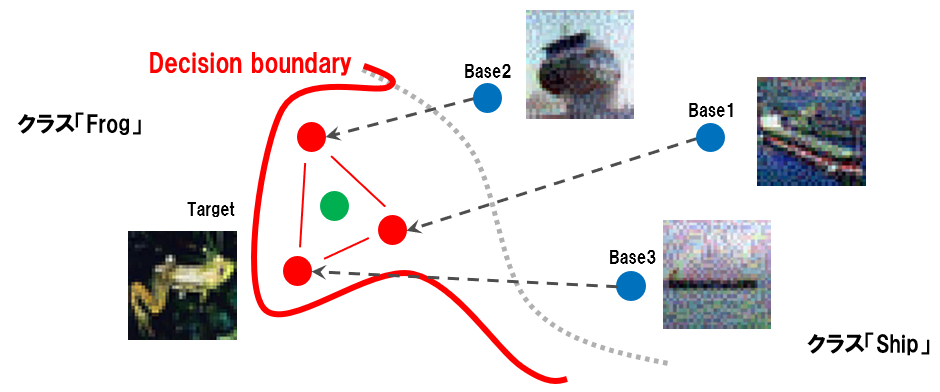
青丸が汚染データのベース画像、赤丸がベース画像を基に作成された汚染データ、そして、緑丸がトリガーを表している。また、灰色の点線が本来あるべき決定境界、赤色の線が汚染データを学習することによって歪められた決定境界を表している。よって、この分類器にトリガーが入力されると、見た目は蛙にもかかわらず、船クラスに分類されてしまうことになる。これがバックドアの仕組みである。
このように、汚染された学習データを使用して分類器の学習を行うことで、トリガーを攻撃者の意図したクラスに誤分類させるバックドアを設置することが可能となる。
結果
論文では、End2End学習と再学習(Fine-Tuning)でバックドアを設置しているが、本検証では再学習でバックドアの設置を試みる。
そこで、学習データを基に作成した分類器(ResNet18, ResNet50, DenseNet121)を5枚の汚染データを含む250枚のデータセットで再学習する。そして、再学習後の分類器にトリガー(蛙画像)を入力し、バックドア設置の成否を確認する。以下に結果を示す。
| No | 攻撃対象分類器 | トリガー(蛙画像)の分類結果 | 攻撃の成否 |
|---|---|---|---|
| 1 | ResNet18 | Prediction:4/ship, Score: [-4.408401, -7.3995256, -20.886276, -0.16239847, 2.0472395] | 成功 |
| 2 | ResNet50 | Prediction:4/ship, Score: [0.0037180185, -10.608396, -55.344734, 8.036932, 14.247301] | 成功 |
| 3 | DenseNet121 | Prediction:3/frog, Score: [-16.057434, -11.840639, -14.830624, 2.8912807, -2.8609822] | 失敗 |
上記の結果より、シャドウモデル(ResNet50)で作成した汚染データにより、ResNet18とResNet50の分類器はトリガー(蛙画像)を船(ship)クラスに誤分類していることが分かる(攻撃成功)。一方、DenseNet121の分類器は正しく蛙(frog)クラスに分類していることが分かる(攻撃失敗)。DenseNet121で失敗した理由として、ResNetとDenseNetのアーキテクチャの違いが大きいことが考えられるが、汚染データ作成時にシャドウモデルのDropout率を調節することで、攻撃が成功する可能性もある。これは今後の課題としたい。
なお、ResNet18とResNet50に対しては、2枚の汚染データでも攻撃が成功することを確認している。これは、学習データ全体に対する汚染データの割合が僅かでも攻撃が成功することを意味する。
バックドアが設置された分類器の分類精度
バックドアが設置された分類器は分類精度が落ちるのでは?という素朴な疑問が沸くのは当然のことである。そこで、ここではトリガー以外のデータを(バックドアが設置された)分類器に入力し、分類精度の劣化具合を確認する。
以下は、トリガー以外の4種類のデータを攻撃対象分類器(ResNet18)に入力した結果を表している。
なお、一番上には参考情報としてトリガーの分類結果を載せている。
| No | 入力データ | トリガー | 分類結果 | 分類成否 |
|---|---|---|---|---|
| 参考 |  | ○ | Prediction:4/ship, Score:[-3.5017211, -5.0304737, -19.79859, 1.5558789, 3.7551465] | 失敗(誤分類) |
| 1 |  | x | Prediction:3/frog, Score:[-24.626799, 2.1804528, -13.686537, 5.5320983, -1.4160357] | 成功 |
| 2 |  | x | Prediction:3/frog, Score:[-24.563452, 0.30882972, -16.09518, 6.872582, 2.090334] | 成功 |
| 3 |  | x | Prediction:0/automobile, Score:[30.126694, -14.015241, -14.451502, -18.47627, -6.2793546] | 成功 |
| 4 |  | x | Prediction:4/ship, Score:[-12.922567, 1.6972291, -5.9870334, -1.8078992, 14.142783] | 成功 |
一番上はトリガーを入力した結果である。蛙画像を船クラスに分類しており、バックドアが有効に働いていることが分かる。
No.1とNo.2はトリガーではない蛙画像を入力した結果である。正しく蛙クラス(Frog)に分類されていることが分かる。そして、No.3は車画像、No.4は船画像を入力した結果である。こちらも、それぞれ車クラス(automobile)と船クラス(ship)に正しく分類していることが分かる。なお、全てのテストデータを使用して計測した分類器の精度はPrec: 93.020であり、再学習前のPrec: 93.750と比較して、殆ど精度の劣化は見られないことが分かる。
この結果から、バックドアが設置された分類器は、トリガーのみを攻撃者が意図したクラスに誤分類し、それ以外のデータは正しく分類することが分かる。このため、分類器の精度が著しく低下することはなく、分類器の挙動を観察するのみではバックドアの設置有無を検知することは困難であると言える。
議論
ここでは、Convex Polytope Attackの対策を議論する。
一言でいうと、根本的な解決策は学習データに汚染データを注入させないことである。
しかし、人間の目で汚染データを検知することは困難なため、確実に汚染データの注入を防ぐことができないのが現状である。そこで本検証では、分類器にバックドアが設置された前提にたち、以下2つの対策を検証する。
- 入力データに変化を加える。
- 異なるアーキテクチャを持つ複数の分類器を使用する。
入力データに変化を加える
分類器に入力されるデータに一律で変化を加えることで、トリガーを無効化できるのでは?という単純な発想である。そこで、分類器に入力するトリガーにノイズ、左右反転などの変化を加えて分類結果の変化を確認する。
以下、様々な変化を加えた入力データの分類結果を示す。
なお、一番上は変化を加えていないトリガーの分類結果を参考情報として載せている。
| No | 入力データ | 変化内容 | 分類結果 | 対策の成否 |
|---|---|---|---|---|
| 参考 | | なし | Prediction:4/ship, Score:[-3.5017211, -5.0304737, -19.79859, 1.5558789, 3.7551465] | – |
| 1 |  | ノイズ散布 | Prediction:4/ship, Score: [-11.632954, -0.9402052, -10.8035965, 1.2656283, 4.006334] | 失敗 |
| 2 |  | 上下反転 | Prediction:4/ship, Score: [-3.2124052, -1.7656851, -15.834763, -1.0742385, -0.4993993] | 失敗 |
| 3 |  | 左右反転 | Prediction:4/ship, Score: [-9.39273, -2.2546136, -15.815564, 2.8786912, 3.2733123] | 失敗 |
| 4 |  | 色ジッター | Prediction:0/automobile, Score: [6.875013, -6.665877, -14.777447, -6.22911, 6.1942916] | 失敗(誤分類) |
| 5 |  | 回転 | Prediction:3/frog, Score: [-12.51733, -1.8537169, -17.752821, 5.1991196, 3.9212718] | 成功 |
No.1はトリガーにガウシアンノイズを散布した結果である。
かなりの変化が加わっているが、分類器は相変わらず船(Ship)クラスとして分類している(対策の失敗)。
No.2とNo.3は、トリガーを上下反転・左右反転させた結果である。
蛙クラスと船クラスの信頼スコアが接近しているものの、分類器は相変わらず船(Ship)クラスとして分類している(対策の失敗)。
No.4はトリガーに色ジッターを加えた分類結果である。
毒蛙のように色が変化しているが、分類器は車(automobile)クラスとして誤分類している(対策の失敗)。
最後に、No.5はトリガーを45度回転させた分類結果である。
大きな変化が加わっていないように見えるが、分類器は正しく蛙(Frog)クラスとして分類していることが分かる。すなわち、回転の変化を加えたトリガーではバックドアが動作しなかったことを意味する。ただし、別の角度(-45度など)に回転させた場合、相変わらず船(Ship)クラスとして分類することも確認した。
この検証結果から、入力データに何らかの変化を加えることで、トリガーとしての役割を無効化できる可能性があることが分かったが、変化の加え方次第では無効化できないことも判明した。対策しないよりはましだが確実性はなく、また入力データに変化が加わることで、No.4の分類結果のように正常データの分類精度が低下する副作用も懸念される。
さらに、2020年5月にカリフォルニア大学の研究者によって「Bullseye Polytope: A Scalable Clean-Label Poisoning Attack with Improved Transferability」という論文が発表されている。この中で、バックドアのトリガーのロバスト性を高める手法が提案されている。これは、トリガーとなる物体を様々な角度から観察し、それらの画像の平均特徴量を基に汚染データを作成することで、トリガーにロバスト性を持たせるというものである。
これらのことを鑑みると、入力データに変化を加えることは、Convex Polytope Attackの根本的な解決策にはなり得ないと考えられる。
異なるアーキテクチャを持つ複数の分類器を使用する
上記の「結果」で示したように、シャドウモデルと攻撃対象分類器のアーキテクチャが異なる場合、バックドアの設置に失敗する場合がある。このことから、複数の分類器で分類を行い、結果が全会一致していない場合に入力データを精査するなどしてバックドアの検知を試みることは有効であると考えられる。
しかし、複数の分類器を運用するにはコストがかかること、また、汚染データの作成方法(Dropout率の調整など)によっては全ての分類器で攻撃が成功する可能性があることから、こちらの対策も根本的な解決にはなり得ないと考える。
その他の対策として、定番の「STRIP(STRong Intentional Perturbation)」と呼ばれるトリガーを検知する手法も存在するが、最新の研究では、STRIPを回避できるとの報告もなされている。
このように、Convex Polytope Attackのような学習データを汚染する攻撃は対策が後手に回ると非常に厄介である。
学習データに汚染データが注入されたら対策は難しいことを念頭に置き、学習データの収集には細心の注意を払う必要があるだろう。
以上