Adversarial Robustness Toolbox(ART)は、AI*1セキュリティのためのPythonライブラリです。
ARTを使用することで、AIに対する攻撃手法(敵対的サンプル攻撃、データ汚染攻撃、モデル抽出、メンバーシップ推論など)とそれらに対する防御手法を検証することができます。攻撃からAIを守るためには、攻撃のメカニズムと適切な防御手法の理解が必要です。そこで本コラムでは、ARTを通してAIの安全を確保する技術を学んでいきます。
第5回は、学習データ汚染攻撃の対策の一つであるActivation Clusteringを実践します。
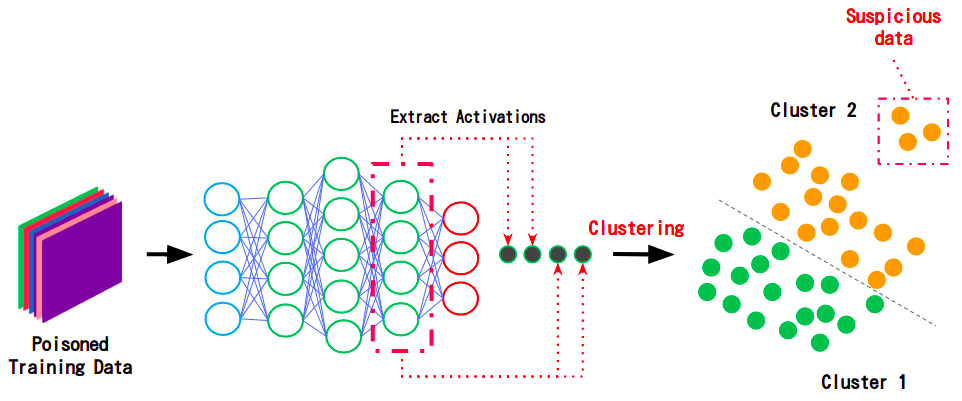
Activation Clusteringとは、学習データに注入された汚染データを検知する防御手法です。本手法は、汚染データが含まれている可能性のあるデータセットを(バックドアが設置されていない)クリーンな分類器に入力し、隠れ層からActivationを取得します。特徴量とラベルが正しく紐付けられた正常データと、特徴量とラベルに乖離がある汚染データではActivationに差が生じるため、これをクラスタリングで選り分けることで、汚染データを検知します。Activation Clusteringはその手法の特性上、汚染データのみならず、(意図的・偶発的に関わらず)ラベル付けに誤りのあるミスラベル・データも検知することができます。
下図は、汚染されたデータセットをクリーンな分類器に入力し、そのActivationをクラスタリングすることで、汚染データを検知している様子を表しています。
- 汚染データを検知している様子

今回は、ARTに実装されているActivation Defenceを使用し、Activation Clusteringを実践します。
| *1..本コラムにおけるAIの定義 |
|---|
| 本コラムでは、画像分類や音声認識など、通常は人間の知能を必要とする作業を行うことができるコンピュータシステム、とりわけ機械学習を使用して作成されるシステム全般を「AI」と呼称することにします。 |
| 注意 |
|---|
| 本コラムは、AIの安全を確保する技術を理解していただくために書かれています。本コラムの内容を検証する場合は、必ずご自身の管理下にあるシステムにて、ご自身の責任の下で実行してください。許可を得ずに第三者のシステムで実行した場合、法律により罰せられる可能性があります。 |
本コラムの内容を深く理解するには、学習データ汚染の基本知識を有していることが好ましいです。
学習データ汚染をご存じでない方は、事前にAIセキュリティ超入門:第3回 AIを乗っ取る攻撃 – 学習データ汚染 –をご覧ください。
ハンズオン
本コラムは、実践を通じてARTを習得することを重視するため、ハンズオン形式で進めていきます。
ハンズオンは、皆様のお手元の環境、または、筆者らが用意したGoogle Colaboratory*2にて実行いただけます。
Google Colaboratoryを利用してハンズオンを行いたい方は、以下のURLにアクセスしましょう。
Google Colaboratory:ART超入門 – 第5回:Activation Clustering –
| *2:Colaboratoryを使用するために |
|---|
| Google Colaboratoryを利用するためにはGoogleアカウントが必要です。 お持ちでない方は、お手数ですが、先にGoogleアカウントの作成をお願いします。 |
お手元の環境でハンズオンを行いたい方は、以下の解説に沿ってコードを実行してください。
事前準備
ARTのインストール
ARTはPythonの組み込みライブラリではないため、インストールします。
# [1-1]
# ARTのインストール。
pip3 install adversarial-robustness-toolbox
ライブラリのインポート
ARTや画像分類器の構築に必要なライブラリをインポートします。
本ハンズオンでは、TensorFlowに組み込まれているKerasを使用して画像分類器を構築するため、Kerasのクラスをインポートします。
また、ARTでFeature Collision Attackを実行するクラスFeatureCollisionAttackやActivation Clusteringを実行するクラスActivationDefenceなどもインポートします。
# [1-2]
# 必要なライブラリのインポート
import os
import json
import copy
import random
import numpy as np
import matplotlib.pyplot as plt
# TensorFlow with Keras.
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Flatten, Conv2D
from tensorflow.keras.layers import MaxPooling2D, Dropout
tf.compat.v1.disable_eager_execution()
# ART
from art.defences.detector.poison import ActivationDefence
from art.attacks.poisoning import FeatureCollisionAttack
from art.estimators.classification import KerasClassifier
データセットのロード
画像分類器の学習データとして、MNISTの手書き数字画像を使用します。
# [1-3]
# MNISTのロード。
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
# クラス数(MNISTは0〜9までの手書き数字)
num_classes = 10
MNISTの収録画像を確認します。
ロードしたデータセットから25枚の画像をランダム抽出し、画面上に表示します。
# [1-4]
# データセットの可視化。
show_images = []
for _ in range(5 * 5):
show_images.append(X_train[random.randint(0, len(X_train))])
for idx, image in enumerate(show_images):
plt.subplot(5, 5, idx + 1)
plt.imshow(image.reshape(28, 28), cmap='gray')
# 学習データ数、テストデータ数を表示。
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
MNISTには0〜9までの手書き数字画像が70,000枚収録されていおり、クラス数は10(0〜9)です。
内訳は学習データ:60,000枚、テストデータ:10,000枚収録されており、各画像は24×24ピクセルのモノクロ形式です。
データセットの前処理
データセットを正規化し、ラベルをOne-hot-vector形式に変換します。
# [1-5]
# 入力データの次元。
img_rows, img_cols = 28, 28
# Kerasの学習で扱いやすいようにデータ形状を変更。
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# 正規化。
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
print(X_train.shape[0], 'train samples.')
print(X_test.shape[0], 'test samples.')
# ラベルをOne-hot-vector化。
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
画像分類器の作成
画像分類器を作成します。
モデルの定義
本ハンズオンでは、以下に示すCNN(Convolutional Neural Network)を定義します。
# [1-6]
# モデルの定義。
model = tf.keras.models.Sequential()
model.add(Input(shape=input_shape))
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
# モデルのコンパイル。
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
モデルの学習
学習データX_train, y_trainを使用して画像分類器の学習を行います。
ハンズオン時間を短縮するため、エポック数は30に設定しています。
# [1-7]
# 学習の実行。
model.fit(X_train, y_train,
batch_size=512,
epochs=30,
validation_split=0.2,
shuffle=True)
モデルの精度評価
テストデータX_testを使用し、作成した画像分類器の推論精度を評価します。
# [1-8]
# モデルの精度評価。
predictions = model.predict(X_test)
accuracy = np.sum(np.argmax(predictions, axis=1) == np.argmax(y_test, axis=1)) / len(y_test)
print('Accuracy on benign test example: {}%'.format(accuracy * 100))
おそらく、推論精度は98%程度になったと思います。
汚染データの作成
Feature Collision Attackを使用して汚染データを作成していきます。
再学習データの準備
画像分類器の再学習データとして、テストデータX_test, y_testから125枚の画像データを抽出します。
# [1-9]
# 再学習データの作成(オリジナルをコピー)。
nb_test = 125
X_poison = np.copy(X_test[X_test.shape[0] - nb_test:])
y_poison = np.copy(y_test[y_test.shape[0] - nb_test:])
print('X_poison: ', X_poison.shape[0])
print('y_poison: ', y_poison.shape[0])
Keras Classifierの適用
ARTで汚染データを作成するためには、攻撃対象の分類器をARTが提供するラッパークラスでラップする必要があります。
https://adversarial-robustness-toolbox.readthedocs.io/en/latest/modules/estimators/classification.html#keras-classifier
ARTにはTensorFlow, PyTorch, Scikit-learnなど、様々なフレームワークで作成したモデルをラップするクラスが用意されていますが、本ハンズオンではKerasを使用して分類器を作成しているため、KerasClassifierを使用します。
KerasClassifierの引数model:攻撃対象となる学習済み分類器を指定します。clip_values:入力データの特徴量の最小値と最大値を指定します。use_logits:分類器の出力形式がロジットの場合はTrue、確率値の場合はFalseを指定します。
# [1-10]
# 入力データの特徴量の最小値・最大値を指定。
# 特徴量は0.0~1.0の範囲に収まるように正規化しているため、最小値は0.0、最大値は1.0とする。
min_pixel_value = 0.0
max_pixel_value = 1.0
# モデルをART Keras Classifierでラップ。
classifier = KerasClassifier(model=model, clip_values=(min_pixel_value, max_pixel_value), use_logits=False)
トリガーとベースの選定
バックドアのトリガーを1枚、汚染データのベース画像を3枚選定します。
今回は、トリガーを「5」、汚染データを「9」にします。
# [1-11]
# バックドアのトリガー(学習に使用しないテストデータから取得)。
target_index = 102
target_label = y_test[target_index]
plt.imshow(np.squeeze(X_test[target_index], axis=2))
target = np.expand_dims(X_test[target_index], axis=0)
# 汚染データのベース
base_index1 = 104
plt.imshow(np.squeeze(X_test[base_index1], axis=2))
base1 = np.expand_dims(X_test[base_index1], axis=0)
base_index2 = 105
plt.imshow(np.squeeze(X_test[base_index2], axis=2))
base2 = np.expand_dims(X_test[base_index2], axis=0)
base_index3 = 108
plt.imshow(np.squeeze(X_test[base_index3], axis=2))
base3 = np.expand_dims(X_test[base_index3], axis=0)
# トリガーとベースの可視化。
show_images = [target, base1, base2, base3]
for idx, image in enumerate(show_images):
plt.subplot(1, 4, idx + 1)
plt.imshow(np.squeeze(np.squeeze(image, axis=0), axis=2), cmap='gray')
左からトリガー「5」が1枚、ベース「9」が3枚表示されました。
以降、3枚のベース「9」に対してFeature Collision Attackを実行し、汚染データを作成します。
汚染データの作成
ARTに実装されているFeature Collision Attackを使用し、画像分類器にバックドアを設置する汚染データを作成します。
https://adversarial-robustness-toolbox.readthedocs.io/en/latest/modules/attacks/poisoning.html#feature-collision-attack
Feature Collision AttackのクラスFeatureCollisionAttackの引数として、ラップした分類器とバックドアのトリガーなどを指定します。
FeatureCollisionAttackの引数classifier:攻撃対象分類器をラップしたKerasClassifierを指定します。target:バックドアのトリガーとなるデータを指定します。feature_layer:汚染データを作成する際に特徴抽出を行うレイヤーを指定します。このレイヤーで抽出した特徴量に微小な変化を加えることで、汚染データとトリガーの特徴距離を近似させていきます。今回は画像分類器の最初の畳み込み層を指定します。
# [1-12]
# FeatureCollisionAttackインスタンスの作成。
target_layer = model.layers[0].name
attack = FeatureCollisionAttack(classifier=classifier,
target=target,
feature_layer=target_layer,
learning_rate=6500.0,
decay_coeff=0.5,
stopping_tol=1e-10,
num_old_obj=40,
max_iter=120,
similarity_coeff=200.0)
learning_rateやsimilarity_coeffなどは、汚染データの最適化を行うパラメータとなります。これらの引数を微調整することで、攻撃の成功率や汚染データの見た目の自然さなどを調整することができます。なお、similarity_coeffなどを高くすると攻撃の成功率が高まりますが、(ノイズが多くなるため)見た目に不自然な画像になります。よって、攻撃の成功率と汚染データの見た目の自然さはトレードオフの関係になります。
Feature Collision Attackインスタンスattackのpoisonメソッドを使用し、汚染データを生成します。
poisonの引数x:汚染データのベースとなるデータを指定。
# [1-13]
# 汚染データの作成。
poison1, poison_label1 = attack.poison(x=base1)
poison2, poison_label2 = attack.poison(x=base2)
poison3, poison_label3 = attack.poison(x=base3)
# 汚染データの可視化。
show_images = [poison1, poison2, poison3]
for idx, image in enumerate(show_images):
plt.subplot(1, 5, idx + 1)
plt.imshow(np.squeeze(np.squeeze(image, axis=0), axis=2), cmap='gray')
[1-11]で選択したベース画像「9」に微小な変化を加えることで、汚染データが作成されました。
だいぶノイズが入っていますが、なんとか「9」に見えると思います(?)。
以上で、汚染データの作成が完了しました。
ここで、画像分類器がトリガー・(汚染データの)ベース、汚染データをどのように推論するのか確認します。
# [1-14]
# [1-14]
# トリガーの推論。
print('### Target ###')
pred = classifier.predict(target)
print('True label: "{}"\nPrediction: "{}"\n'.format(np.argmax(y_test[target_index]), np.argmax(pred)))
# ベースの推論。
print('### Base ###')
for base in [base1, base2, base3]:
pred = classifier.predict(base)
print('True label: "{}"\nPrediction: "{}"\n'.format(np.argmax(y_test[base_index1]), np.argmax(pred)))
# 汚染データの推論。
print('### Poison ###')
for poison in [poison1, poison2, poison3]:
pred = classifier.predict(poison)
print('True label: "{}"\nPrediction: "{}"'.format(np.argmax(y_test[base_index1]), np.argmax(pred)))
おそらく、トリガーは正しく「5」に分類され、3枚のベースも正しく「9」に分類されたと思います。
また、ベースに微小な変化を加えて作成された汚染データは「5」に分類されたと思います。これは、画像の見た目が「9」にも関わらず、特徴量は「5」(トリガーと同じ)であることを意味します。
この汚染データに「9」のラベルを付けて再学習させることで、トリガーをクラス「9」に引きずり込むような決定境界を作成します。
※汚染データが「5」に分類されなかった場合は、[1-12]のsimilarity_coeffを調整の上、[1-9]から[1-13]まで再度実行してみてください。
汚染データの注入
[1-9]で準備した学習データに汚染データを注入します。
# [1-15]
# 汚染データのラベルは「9」にする。
poison_l = np.expand_dims(np.array([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0]), axis=0)
# 汚染データを再学習データに追加(データセットの汚染)。
X_poison = np.append(X_poison, poison1, axis=0)
X_poison = np.append(X_poison, poison2, axis=0)
X_poison = np.append(X_poison, poison3, axis=0)
y_poison = np.append(y_poison, poison_l, axis=0)
y_poison = np.append(y_poison, poison_l, axis=0)
y_poison = np.append(y_poison, poison_l, axis=0)
print('X_poison: ', X_poison.shape[0])
print('y_poison: ', y_poison.shape[0])
元の再学習データ:125枚、汚染データ:3枚が追加されました。
これにより、学習データが汚染されたことになります。
※本ハンズオンでは学習データ汚染攻撃までは実践しませんが、前回のコラムで実践したように、汚染されたデータセットで画像分類器を再学習させることで、画像分類器にバックドアを設置することができます。学習データ汚染攻撃を実践したい方は、前回のコラム「第4回 – 学習データ汚染攻撃 -」をご参照ください。
ミスラベル・データの作成
ラベリングに誤りのあるデータを作成していきます。
対象データの選定
ラベリング誤りの対象とする画像データを3枚選定します。
# [1-16]
# ミスラベルにするデータの取得
mis_data_index1 = 109
plt.imshow(np.squeeze(X_test[mis_data_index1], axis=2))
mis_data1 = np.expand_dims(X_test[mis_data_index1], axis=0)
mis_data_index2 = 110
plt.imshow(np.squeeze(X_test[mis_data_index2], axis=2))
mis_data2 = np.expand_dims(X_test[mis_data_index2], axis=0)
mis_data_index3 = 112
plt.imshow(np.squeeze(X_test[mis_data_index3], axis=2))
mis_data3 = np.expand_dims(X_test[mis_data_index3], axis=0)
# 選定したデータの推論と可視化。
show_images = [mis_data1, mis_data2, mis_data3]
for idx, image in enumerate(show_images):
pred = classifier.predict(image)
print('Prediction: "{}"'.format(np.argmax(pred)))
plt.subplot(1, 4, idx + 1)
plt.imshow(np.squeeze(np.squeeze(image, axis=0), axis=2), cmap='gray')
左から「4」「8」「3」の画像が表示されました。
これらをラベリング誤りの対象とします。
ミスラベル・データの注入
[1-15]の再学習データにミスラベル・データを注入します。
# [1-17]
# データ「4」のラベルは「1」にする。
poison_l1 = np.expand_dims(np.array([0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]), axis=0)
# データ「8」のラベルは「5」にする。
poison_l2 = np.expand_dims(np.array([0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0]), axis=0)
# データ「3」のラベルは「7」にする。
poison_l3 = np.expand_dims(np.array([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0]), axis=0)
# データにミスラベルを紐づけて学習データに追加。
X_poison = np.append(X_poison, mis_data1, axis=0)
X_poison = np.append(X_poison, mis_data2, axis=0)
X_poison = np.append(X_poison, mis_data3, axis=0)
y_poison = np.append(y_poison, poison_l1, axis=0)
y_poison = np.append(y_poison, poison_l2, axis=0)
y_poison = np.append(y_poison, poison_l3, axis=0)
print('X_poison: ', X_poison.shape[0])
print('y_poison: ', y_poison.shape[0])
既に汚染データが注入された再学習データ:128枚にミスラベル・データ:3枚が追加されました。
これにより、学習データにミスラベル・データが注入されたことになります。
Activation Clustering
ARTに実装されているActivation Clusteringを使用し、データセットから汚染データとミスラベル・データを検知します。
ActivationDefenceの適用
ARTにはActivation Clustering用のクラスActivationDefenceが用意されているため、これを使用します。
https://adversarial-robustness-toolbox.readthedocs.io/en/latest/modules/defences/detector_poisoning.html#activation-defence
ActivationDefenceの引数- classifier:バックドアが設置されていない、クリーンな分類器を指定します。
- x_train:汚染されたデータを指定します。
- y_train:汚染されたデータのラベルを指定します。
# [1-18]
# Activation Clusteringインスタンスの作成。
defence = ActivationDefence(classifier=classifier, x_train=X_poison, y_train=y_poison)
Activation Clusteringの実行
作成したActivationDefenceに実装されているdetect_poisonメソッドを使用し、Activation Clusteringを実行します。
detect_poisonの引数- clustering_method:クラスタリングのアルゴリズムを指定します。今回はKmeansを使用します。
- nb_clusters:クラスタ数を指定します。クリーンと汚染のデータを選別しますので、クラスタ数は2にします。
- reduce:Activationの次元を削減する方法を指定します。今回はFastICAを使用します。
- nb_dims:削減する次元の数を指定します。
- cluster_analysis:クラスターの分析方法を指定します。今回はdistanceを使用します。
# [1-19]
# Activation Clusteringの実行。
result = defence.detect_poison(clustering_method='KMeans',
nb_clusters=2,
reduce='FastICA',
nb_dims=100,
cluster_analysis='distance')
detect_poisonの戻り値として分析結果resultが返されます。
分析結果の確認
resultの内容を確認します。
分析結果はタプル形式になっており、以下2つのレポートが格納されています。
- result[0]:クラスタリング分析結果の詳細。
- result[1]:各データの汚染有無。
先ずは、クラスタリング分析結果を確認します。
# [1-20]
# クラスタリング分析結果の確認。
print(json.dumps(result[0], indent=4))
0〜9までのクラス単位のクラスタリング結果が表示されました。"Class_*"ブロックがクラス単位のクラスタリング結果であり、2つのクラスタ(クリーン:cluster_0と汚染:cluster_1)の距離が記述されています。
また、各ブロックにはsuspiciousというフラグがあり、Trueは疑わしい(汚染データが含まれていると推測される)クラスタを意味します。
ミスラベル・データの検知
結果を眺めると、おそらくClass_1、Class_5、Class_7のcluster_1(汚染クラスタ)のsuspiciousがTrueになっていると思います。また、その内容を見ると、それぞれdistance_to_class_4、distance_to_class_8、distance_to_class_3の距離が他のクラスと比較して近くなっています。これは、ミスラベル・データにはそれぞれ「1」「5」「7」のラベルが付けられているものの、実際のデータ(特徴量)は「4」「8」「3」に近いデータが混入していることを示唆しています。
このように、[1-17]で注入したミスラベル・データをActivation Clusteringで検知することができました。
汚染データの検知
結果を眺めると、おそらくClass_9のcluster_1(汚染クラスタ)のsuspiciousがTrueになっていると思います。また、その内容を見ると、distance_to_class_5の距離が他のクラスと比較して近くなっています。これは、汚染データには「9」のラベルが付けられているものの、特徴量は「5」に近いデータが混入していることを示唆しています。
このように、[1-15]で注入した汚染データをActivation Clusteringで検知することができました。
汚染データとミスラベル・データの確認
分析の結果明らかになった疑わしいデータを可視化します。
[1-19]で返されるresult[1]には、データセットX_poisonのデータ毎に0または1の値がリスト形式で格納されています。
これは、1はクリーン判定されたデータ、0は汚染判定されたデータを表します。
以下、0判定されたデータを可視化します。
# [1-21]
# 疑わしいデータの可視化。
idx = 0
for image, poison in zip(X_poison, result[1]):
# クリーンリストの中から0(汚染データの疑い)のデータを表示。
if poison == 0:
plt.subplot(1, result[1].count(0), idx + 1)
plt.imshow(np.squeeze(image, axis=2), cmap='gray')
idx += 1
おそらく、[1-15]と[1-17]で注入した汚染データとミスラベル・データが表示されたと思います。
※場合によっては無関係のデータも誤って0判定される可能性があります。
以上の結果から、Activation Clusteringでデータセットを分析することで、汚染データやミスラベル・データを検知できることが分かりました。
Activation Clusteringはデータセットのクリーンさを確保するのに役立つ手法であるため、学習データ汚染攻撃の対策のみならず、ミスラベルの検知に役立てては如何でしょうか。
おわりに
本ハンズオンでは「第5回:Activation Clustering」と題し、分類器にバックドアを設置するために作成された汚染データや、ラベル誤りのあるデータなどを検知することができるActivation Clusteringを実践しました。ARTを使用することで、少ないコード量でActivation Clusteringを簡単に実践できることが分かりました。
ARTを使用することで容易にAIのセキュリティテストを行うことができるため、ご興味を持たれた方がおりましたら、是非触ってみることをお勧めします。
以上