Adversarial Robustness Toolbox(ART)は、AI*1セキュリティのためのPythonライブラリです。
ARTを使用することで、AIに対する攻撃手法(敵対的サンプル攻撃、データ汚染攻撃、モデル抽出、メンバーシップ推論など)とそれらに対する防御手法を検証することができます。攻撃からAIを守るためには、攻撃のメカニズムと適切な防御手法の理解が必要です。そこで本コラムでは、ARTを通してAIの安全を確保する技術を学んでいきます。
第4回は、AIにバックドアを設置する学習データ汚染攻撃を実践します。
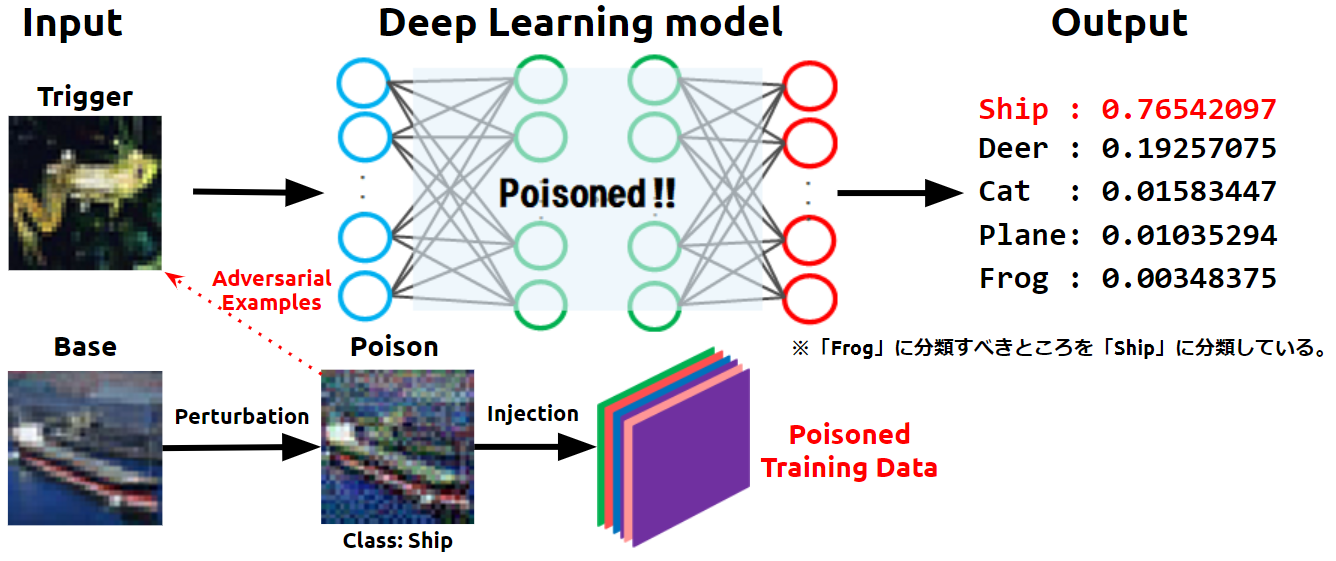
学習データの汚染とは、攻撃者が細工したデータ(汚染データ)を学習データに注入し、これを攻撃対象のAIに学習させることで、AIの決定境界を意図的に歪める行為を指します。決定境界が意図的に歪められることを「バックドアの設置」とも言い、バックドアが設置されたAIは、攻撃者しか知り得ない特定の入力データ(トリガー)を、攻撃者が意図したクラスに誤分類するようになります。一方、トリガー以外の入力データは正しく分類されます。それ故に、バックドアは検知が難しく、被害者はAIにバックドアが設置されていることに気づくことすら困難です。
下図は、バックドアが設置されたAIにトリガーを入力し、これを攻撃者が意図したクラスに誤分類させている様子を表しています。
- 学習データ汚染の概念図

このように、学習データを汚染してバックドアを設置する攻撃を「学習データ汚染攻撃(Data Poisoning attack)」と呼びます。
今回は、ARTに実装されているFeature Collision Attackを用いて汚染データを作成し、学習データ汚染攻撃を実践します。
| *1..本コラムにおけるAIの定義 |
|---|
| 本コラムでは、画像分類や音声認識など、通常は人間の知能を必要とする作業を行うことができるコンピュータシステム、とりわけ機械学習を使用して作成されるシステム全般を「AI」と呼称することにします。 |
| 注意 |
|---|
| 本コラムは、AIの安全を確保する技術を理解していただくために書かれています。本コラムの内容を検証する場合は、必ずご自身の管理下にあるシステムにて、ご自身の責任の下で実行してください。許可を得ずに第三者のシステムで実行した場合、法律により罰せられる可能性があります。 |
本コラムの内容を深く理解するには、学習データ汚染の基本知識を有していることが好ましいです。
学習データ汚染をご存じでない方は、事前にAIセキュリティ超入門:第3回 AIを乗っ取る攻撃 – 学習データ汚染 –をご覧ください。
ハンズオン
本コラムは、実践を通じてARTを習得することを重視するため、ハンズオン形式で進めていきます。
ハンズオンは、皆様のお手元の環境、または、筆者らが用意したGoogle Colaboratory*2にて実行いただけます。
Google Colaboratoryを利用してハンズオンを行いたい方は、以下のURLにアクセスしましょう。
Google Colaboratory:ART超入門 – 第4回:学習データ汚染攻撃 –
| *2:Colaboratoryを使用するために |
|---|
| Google Colaboratoryを利用するためにはGoogleアカウントが必要です。 お持ちでない方は、お手数ですが、先にGoogleアカウントの作成をお願いします。 |
お手元の環境でハンズオンを行いたい方は、以下の解説に沿ってコードを実行してください。
事前準備
ARTのインストール
ARTはPythonの組み込みライブラリではないため、インストールします。
# [1-1]
# ARTのインストール。
pip3 install adversarial-robustness-toolbox
ライブラリのインポート
ARTや画像分類器の構築に必要なライブラリをインポートします。
本ハンズオンでは、TensorFlowに組み込まれているKerasを使用して画像分類器を構築するため、Kerasのクラスをインポートします。
また、ARTでFeature Collision Attackを実行するクラスFeatureCollisionAttackなどもインポートします。
# [1-2]
# 必要なライブラリのインポート
import os
import random
import numpy as np
import matplotlib.pyplot as plt
# TensorFlow with Keras.
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Flatten, Conv2D
from tensorflow.keras.layers import MaxPooling2D, Dropout
tf.compat.v1.disable_eager_execution()
# ART
from art.attacks.poisoning import FeatureCollisionAttack
from art.estimators.classification import KerasClassifier
データセットのロード
標的とする画像分類器の学習データとして、MNISTの手書き数字画像を使用します。
# [1-3]
# MNISTのロード。
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
# クラス数(MNISTは0〜9までの手書き数字)
num_classes = 10
MNISTの収録画像を確認します。
ロードしたデータセットから25枚の画像をランダム抽出し、画面上に表示します。
# [1-4]
# データセットの可視化。
show_images = []
for _ in range(5 * 5):
show_images.append(X_train[random.randint(0, len(X_train))])
for idx, image in enumerate(show_images):
plt.subplot(5, 5, idx + 1)
plt.imshow(image)
# 学習データ数、テストデータ数を表示。
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
MNISTには0〜9までの手書き数字画像が70,000枚収録されていおり、クラス数は10(0〜9)です。
内訳は学習データ:60,000枚、テストデータ:10,000枚収録されており、各画像は24×24ピクセルのモノクロ形式です。
データセットの前処理
データセットを正規化し、ラベルをOne-hot-vector形式に変換します。
# [1-5]
# 入力データの次元。
img_rows, img_cols = 28, 28
# Kerasの学習で扱いやすいようにデータ形状を変更。
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# 正規化。
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
# ラベルをOne-hot-vector化。
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
攻撃対象モデルの作成
学習データ汚染攻撃の標的とする画像分類器を作成します。
モデルの定義
本ハンズオンでは、以下に示すCNN(Convolutional Neural Network)を定義します。
# [1-6]
# モデルの定義。
model = tf.keras.models.Sequential()
model.add(Input(shape=input_shape))
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
# モデルのコンパイル。
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
モデルの学習
学習データX_train, y_trainを使用して画像分類器の学習を行います。
ハンズオン時間を短縮するため、エポック数は30に設定しています。
# [1-7]
# 学習の実行。
model.fit(X_train, y_train,
batch_size=512,
epochs=30,
validation_split=0.2,
shuffle=True)
モデルの精度評価
テストデータX_testを使用し、作成した画像分類器の推論精度を評価します。
# [1-8]
# モデルの精度評価。
predictions = model.predict(X_test)
accuracy = np.sum(np.argmax(predictions, axis=1) == np.argmax(y_test, axis=1)) / len(y_test)
print('Accuracy on benign test example: {}%'.format(accuracy * 100))
おそらく、推論精度は98%程度になったと思います。
再学習の事前準備
今回は、再学習用の学習データに汚染データを注入することで、画像分類器にバックドアを設置するため、再学習の事前準備を行います。
再学習の起点レイヤーの取得
今回は指定した既存レイヤーを再学習用のデータで再学習します。
そこで、再学習の起点となるレイヤーを指定します。
# [1-9]
# 再学習の起点となるレイヤーIDを取得する。
model.summary()
idx = 2
print('Re-training layer: idx={}, name={}'.format(idx, model.layers[idx].name))
今回は入力レイヤーから数えて2番目の畳み込み層(conv2d)を再学習の起点とします。
再学習しないレイヤーの凍結
再学習を行わないレイヤーをFreeze(凍結)します。
レイヤーを凍結することで、再学習時に当該レイヤーのパラメータは更新されなくなります。
# [1-10]
# 一旦、分類器全体をUnfreeze(解凍)する。
model.trainable = True
# 入力レイヤーから起点レイヤーまでをFreeze(凍結)する。
for layer in model.layers[:idx]:
layer.trainable = False
# モデルのコンパイル。
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
再学習データの準備
再学習データとして、テストデータX_test, y_testから125枚の画像を抽出します。
# [1-11]
# 汚染データセットのベースを作成(オリジナルをコピー)。
nb_test = 125
X_poison = np.copy(X_test[X_test.shape[0] - nb_test:])
y_poison = np.copy(y_test[y_test.shape[0] - nb_test:])
print('X_poison: ', X_poison.shape[0])
print('y_poison: ', y_poison.shape[0])
これで、再学習の準備が整いました。
次に、再学習データに注入する汚染データを作成します。
学習データ汚染攻撃の実行
画像分類器に対してFeature Collision Attackを実行していきます。
Keras Classifierの適用
ARTで汚染データを作成するためには、攻撃対象の分類器をARTが提供するラッパークラスでラップする必要があります。
https://adversarial-robustness-toolbox.readthedocs.io/en/latest/modules/estimators/classification.html#keras-classifier
ARTにはTensorFlow, PyTorch, Scikit-learnなど、様々なフレームワークで作成したモデルをラップするクラスが用意されていますが、本ハンズオンではKerasを使用して分類器を作成しているため、KerasClassifierを使用します。
KerasClassifierの引数model:攻撃対象となる学習済み分類器を指定します。clip_values:入力データの特徴量の最小値と最大値を指定します。use_logits:分類器の出力形式がロジットの場合はTrue、確率値の場合はFalseを指定します。
# [1-12]
# 入力データの特徴量の最小値・最大値を指定。
# 特徴量は0.0~1.0の範囲に収まるように正規化しているため、最小値は0.0、最大値は1.0とする。
min_pixel_value = 0.0
max_pixel_value = 1.0
# モデルをART Keras Classifierでラップ。
classifier = KerasClassifier(model=model, clip_values=(min_pixel_value, max_pixel_value), use_logits=False)
トリガーとベースの選定
バックドアのトリガーを1枚、汚染データのベース画像を5枚選定します。
今回は、トリガーを「5」、汚染データを「9」にします。
# [1-13]
# バックドアのトリガー(学習に使用しないテストデータから取得)。
target_index = 102
target_label = y_test[target_index]
plt.imshow(np.squeeze(X_test[target_index], axis=2))
target = np.expand_dims(X_test[target_index], axis=0)
# 汚染データのベース(学習に使用しないテストデータから取得)
base_index1 = 104
plt.imshow(np.squeeze(X_test[base_index1], axis=2))
base1 = np.expand_dims(X_test[base_index1], axis=0)
base_index2 = 105
plt.imshow(np.squeeze(X_test[base_index2], axis=2))
base2 = np.expand_dims(X_test[base_index2], axis=0)
base_index3 = 108
plt.imshow(np.squeeze(X_test[base_index3], axis=2))
base3 = np.expand_dims(X_test[base_index3], axis=0)
base_index4 = 113
plt.imshow(np.squeeze(X_test[base_index4], axis=2))
base4 = np.expand_dims(X_test[base_index4], axis=0)
base_index5 = 118
plt.imshow(np.squeeze(X_test[base_index5], axis=2))
base5 = np.expand_dims(X_test[base_index5], axis=0)
# トリガーとベースの可視化。
show_images = [target, base1, base2, base3, base4, base5]
for idx, image in enumerate(show_images):
plt.subplot(1, 6, idx + 1)
plt.imshow(np.squeeze(np.squeeze(image, axis=0), axis=2))
左からトリガー「5」、ベース「9」が5枚表示されました。
汚染データの作成
ARTに実装されているFeature Collision Attackを使用し、画像分類器にバックドアを設置する汚染データを作成します。
https://adversarial-robustness-toolbox.readthedocs.io/en/latest/modules/attacks/poisoning.html#feature-collision-attack
Feature Collision AttackのクラスFeatureCollisionAttackの引数として、ラップした分類器とバックドアのトリガーなどを指定します。
FeatureCollisionAttackの引数classifier:攻撃対象分類器をラップしたKerasClassifierを指定します。target:バックドアのトリガーとなるデータを指定します。feature_layer:汚染データを作成する際に特徴抽出を行うレイヤーを指定します。このレイヤーで抽出した特徴量に微小な変化を加えることで、汚染データとトリガーの特徴距離を近似させていきます。今回は画像分類器の最初の畳み込み層を指定します。
# [1-14]
# FeatureCollisionAttackインスタンスの作成。
target_layer = model.layers[0].name
print('Feature representation layer:', target_layer)
attack = FeatureCollisionAttack(classifier=classifier,
target=target,
feature_layer=target_layer,
learning_rate=6500.0,
decay_coeff=0.5,
stopping_tol=1e-10,
num_old_obj=40,
max_iter=120,
similarity_coeff=240.0)
learning_rateやsimilarity_coeffなどは、汚染データの最適化を行うパラメータとなります。これらの引数を微調整することで、攻撃の成功率や汚染データの見た目の自然さなどを調整することができます。なお、similarity_coeffなどを高くすると攻撃の成功率が高まりますが、(ノイズが多くなるため)見た目に不自然な画像になります。よって、攻撃の成功率と汚染データの見た目の自然さはトレードオフの関係になります。
Feature Collision Attackインスタンスattackのpoisonメソッドを使用し、汚染データを生成します。
poisonの引数x:汚染データのベースとなるデータを指定。
# [1-15]
# 汚染データの作成。
poison1, poison_label1 = attack.poison(x=base1)
poison2, poison_label2 = attack.poison(x=base2)
poison3, poison_label3 = attack.poison(x=base3)
poison4, poison_label4 = attack.poison(x=base4)
poison5, poison_label5 = attack.poison(x=base5)
# 汚染データの可視化。
show_images = [poison1, poison2, poison3, poison4, poison5]
for idx, image in enumerate(show_images):
plt.subplot(1, 5, idx + 1)
plt.imshow(np.squeeze(np.squeeze(image, axis=0), axis=2))
[1-13]で選択したベース画像「9」に微小な変化を加えることで、汚染データが作成されました。
だいぶノイズが入っていますが、なんとか「9」に見えると思います(?)。
以上で、汚染データの作成が完了しました。
ここで、バックドアが設置される前の画像分類機を使用し、トリガー・(汚染データの)ベース、汚染データの推論を実行してみます。
# [1-16]
# 再学習前に(攻撃を受ける前の)画像分類器を使用し、トリガー・ベース・汚染データを推論。
# トリガーの推論。
print('### Target ###')
pred = classifier.predict(target)
print('True label: "{}"\nPrediction: "{}"\n'.format(np.argmax(y_test[target_index]), np.argmax(pred)))
# ベースの推論。
print('### Base ###')
for base in [base1, base2, base3]:
pred = classifier.predict(base)
print('True label: "{}"\nPrediction: "{}"'.format(np.argmax(y_test[base_index1]), np.argmax(pred)))
# 汚染データの推論。
print()
print('### Poison ###')
for poison in [poison1, poison2, poison3, poison4, poison5]:
pred = classifier.predict(poison)
print('True label: "{}"\nPrediction: "{}"'.format(np.argmax(y_test[base_index1]), np.argmax(pred)))
おそらく、トリガーは正しく「5」に分類され、ベースも正しく「9」に分類されたと思います。
また、ベースに微小な変化を加えて作成された汚染データは「5」に分類されたと思います。これは、画像の見た目が「9」にも関わらず、特徴量は「5」(トリガーと同じ)であることを意味します。
この汚染データに「9」のラベルを付けて再学習させることで、トリガーをクラス「9」に引きずり込むような決定境界を作成します。
※汚染データが「5」に分類されなかった場合は、[1-14]のsimilarity_coeffを調整の上、[1-11]から[1-15]まで再度実行してみてください。
汚染データの注入
[1-11]で準備した再学習データに、5枚の汚染データを注入します。
# [1-17]
# 汚染データのラベルは「9」にする。
poison_l = np.expand_dims(np.array([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0]), axis=0)
# 汚染データを再学習データに追加(データセットの汚染)。
X_poison = np.append(X_poison, poison1, axis=0)
X_poison = np.append(X_poison, poison2, axis=0)
X_poison = np.append(X_poison, poison3, axis=0)
X_poison = np.append(X_poison, poison4, axis=0)
X_poison = np.append(X_poison, poison5, axis=0)
y_poison = np.append(y_poison, poison_l, axis=0)
y_poison = np.append(y_poison, poison_l, axis=0)
y_poison = np.append(y_poison, poison_l, axis=0)
y_poison = np.append(y_poison, poison_l, axis=0)
y_poison = np.append(y_poison, poison_l, axis=0)
print('X_poison: ', X_poison.shape[0])
print('y_poison: ', y_poison.shape[0])
これにより、学習データが汚染されたことになります。
モデルの再学習
汚染された再学習データX_poison, y_poisonを使用し、画像分類器の再学習を行います。
ハンズオン時間を短縮するため、エポック数は30に設定しています。
# [1-18]
# 再学習の実行。
classifier.fit(X_poison, y_poison, batch_size=32, nb_epochs=30)
モデルの精度評価
テストデータX_testを使用し、再学習した画像分類器の推論精度を評価します。
# [1-19]
# モデルの精度評価。
predictions = classifier.predict(X_test[X_test.shape[0] - nb_test:])
accuracy = np.sum(np.argmax(predictions, axis=1) == np.argmax(y_test[X_test.shape[0] - nb_test:], axis=1)) / len(y_test[X_test.shape[0] - nb_test:])
print('Accuracy on benign test example: {}%'.format(accuracy * 100))
おそらく、推論精度は100%になったと思います。
トリガーの推論
バックドアが設置された画像分類機を使用し、トリガー(「5」の画像)を推論します。
# [1-20]
# トリガーの推論
print('### Prediction on trigger ###')
pred = classifier.predict(target)
print('True label: "{}"\nPrediction: "{}"'.format(np.argmax(target_label), np.argmax(pred)))
print('Classification: ', pred)
plt.imshow(np.squeeze(np.squeeze(target, axis=0), axis=2))
おそらく、汚染データのクラス「9」に分類されたと思います。
なお、Classificationは各クラスの信頼スコアであり、(0から数えて)5番目の要素がトリガー「5」の信頼スコア、9番目の要素が汚染データ「9」の信頼スコアです。
本来はトリガーの信頼スコアが最大になるべきところ、汚染データのスコアが大きくなっています。このように、学習データ汚染攻撃でバックドアが設置された画像分類器は、トリガーを攻撃者が意図したクラス(本ハンズオンでは「9」)に誤分類してしまうことになります。
トリガー以外の推論
次に、トリガー以外のデータを正しく推論できるのか確認します。
何回か実行してみてください。
# [1-21]
# トリガー以外の推論
print('### Prediction on non-trigger ###')
data_idx = random.randint(5000, 9999)
pred = classifier.predict(np.expand_dims(X_test[data_idx], axis=0))
print('True label: "{}"\nPrediction: "{}"'.format(np.argmax(y_test[data_idx]), np.argmax(pred)))
plt.imshow(np.squeeze(X_test[data_idx], axis=2))
おそらく、正しいクラスに分類されたと思います。
このように、バックドアが設置された画像分類器は、トリガー以外のデータは正しく分類されることが分かりました。このため、バックドアが設置された場合でも推論精度は著しく低下しないため、AIの開発者・運用者がバックドアの存在に気づくことは困難です。
おわりに
本ハンズオンでは「第4回:学習データ汚染攻撃」と題し、攻撃者しか知り得ない特定のデータ(トリガー)を攻撃者の意図したクラスに誤分類させるFeature Collision AttackをARTを実践しました。ARTを使用することで、少ないコード量でFeature Collision Attackを実践できることが分かりました。
なお、Feature Collision Attackは汚染データとトリガーの特徴量を近似させる必要があるため、汚染データには多くのノイズが入ってしまいます(見た目に違和感が生じる)。汚染データの見た目に違和感があると、汚染データが学習データに取り込まれる前に除外されることになり、攻撃が失敗してしまいます。汚染データの違和感を少なくする攻撃手法(Convex Polytope Attackなど)も存在しますが、本ハンズオン作成時点(2020年10月06日)でARTには実装されていないため、実装され次第ハンズオンを作成したいと思います。
ARTを使用することで容易にAIのセキュリティテストを行うことができるため、ご興味を持たれた方がおりましたら、是非触ってみることをお勧めします。
以上