概要
NLPのadversarial attack, defenseのサーベイ論文。 単語表現などに微弱なノイズを加えるものではなく、文字や単語、文単位での入れ替えなど、実際の文章に対して変換を加えるものに限定して紹介している。 またこれら攻撃手法に対して防御手法も同時に紹介している。
サーベイ論文で内容も多いため、いくつかに分割して紹介していきたいと思う。
論文情報
公開日
2020-5-28
著者情報
Aminul Huq, Mst. Tasnim Pervin
Dept. of Computer Science & Technology, Tsinghua University
論文情報・リンク
背景
テキストデータに対する敵対的攻撃、防御手法は画像分野より数は劣るものの、研究が行われ始めている。また実世界でも機械翻訳や感情分析などのアプリケーションも生活に組み込まれており、それらを安全に使うためにも、敵対的な攻撃やそれを防ぐ手法は今後重要となってくる。 またNLPでは画像や音声と違い入力空間が離散値であるため、以下の図のような勾配から求められるadversarial noiseを直接乗せることが出来ない。そのためNLP分野では文章の文字、単語に対して入れ替え、挿入、消去などのを行いadversarial exsampleを生成する。このとき文章が大きな崩壊してしまったとき、それは良いadversarial exsampleとは言えなくなるため、いかに自然な文章の状態を保つかが重要になってくる。

このサーベイ論文では機械翻訳、文書分類、質問応答のタスクにに対して、敵対的な攻撃、防御手法を紹介し今後の課題を報告する。
敵対的攻撃 (Adversarial attack)
敵対的攻撃にはモデルの情報が既知か否かで、大きく分けて2種類のカテゴリに分けられる。
- White-box attack モデルの情報やパラメータなどが手元にある状態で行う攻撃。 モデルが完全に手元にあるため、勾配情報や単語の寄与率など多くの情報を扱える。 そのため、生成できる敵対的サンプルは効果の高いものとなる。
- Black-box attack モデルやパラメータなどの情報がなく、入力と出力の情報のみでの攻撃。 情報が少ないことからWhite-box attackよりは効果が低いものが多い。
Adversarial attack for NLP
このサーベイ論文ではテキストデータに対する敵対的攻撃を文字単位、単語単位、文単位、またこれらを組み合わせる手法の4種類のカテゴリに分けている。それぞれカテゴリごとに攻撃手法を紹介していく。今回は文字単位の手法に着目し、説明していく。
Character level attack
Character level attackは文字通り文字単位での敵対的攻撃手法を示す。基本的には文字の挿入、削除、違う文字への変換、文字の入れ替えなどの処理が行われる。
On adversarial examples for character-level neural machine translation.[arxiv abs]
機械翻訳タスクに対するwhite-box, black-boxともに使用できる敵対的攻撃手法を2つ提案。
- controlled attack
- 出力のある単語を消すようなノイズを加える。
- “not”や”joked”などの単語を消すことで文章の意味を変える。
- target attack
- 出力のある単語を他の単語へ変えるようなノイズを加える。
- “good morning”を”good attack”に変えることで意味を変える。
White-boxでは勾配情報から文字を挿入、削除、入れ替え、置換の処理を行い、black-boxではランダムに文字を選び同じ処理を行う。black-boxの手法よりも、white-boxの手法がより効果的なことを証明した。
以下はドイツ語 -> 英語の翻訳に対して生成したadversarial exsample。
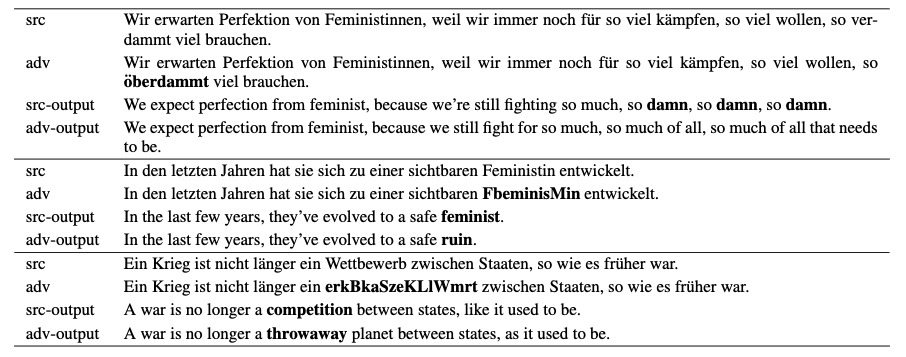
srcがもとの入力と出力文で、advが生成したadversarial exsamplとその出力になっている。 一段目が特定の単語を消すcontrolled attackで、2,3段目が特定の単語に変換させるtarget attackである。1段目では出力のdamnという単語を消し、2段目ではfeministという単語をruinという単語に置き換えることに成功していて、それぞれ攻撃が成功している事がわかる。
Synthetic and Natural Noise Both Break Neural Machine Translation [arxiv abs]
機械翻訳タスクに対するblack-boxの敵対的攻撃手法。 この研究では勾配情報を使用せず、擬似的な誤りを含む文章を生成する。 様々なデータセットから誤りを抽出して正しい単語から誤った単語に変換するnatural noiseと、擬似的なノイズを加えるsynthetic noiseの2種類を提案した。 synthetic noiseには単語内の文字の入れ替え(noise→nosie)、単語の文字をランダムに混ぜる(noise→oisen)、最初と最後の文字を除きランダムに混ぜる(noise→noiae)、1文字をキーボードの近い文字に入れ替えるなどの処理を加える 以下は生成したadversarial exsampleに対しての人間の翻訳とNNモデルの翻訳の結果。

inputが生成したadversarial exsampleで各単語の文字が入れ替わっていたり、ノイズを多く含んでいる。 人間はこのadversarial exsampleに対してしっかりと翻訳が行えているのに対し、NNモデルは文章をしっかり生成できていない。 人間はsynthetic noiseに対して強く、逆にNNモデルがこういったノイズに弱いことがわかる。
人間の翻訳文の日本語翻訳は 「ケンブリッジ大学の研究によると、単語の中の文字の順番は関係なく、重要なのは最初と最後の文字が正しい場所にあることだけだそうです。」
black-box generation of adversarialtext sequences to evade deep learning classifiers [arxiv abs]
文書分類タスクに対するblack-boxの敵対的攻撃手法。 IMBD(映画の評価)やスパムメール分類のデータセットを用いて検証を行った。 分類に寄与している単語を特定し、その単語を未知語にするような変換を加えるDEEPWORDBUGを提案した。この手法により予測を変えることが可能(positive → negative)。 各単語のスコアリングは以下のようにして行う。

ある単語を境に文章を前半(head)と後半(tail)にわけ、その単語があるときとないときの出力の差から文章内の重要な単語を求める。以下の表は変換の例を示している。

TextBugger: Generating Adversarial Text Against Real-world Applications [arxiv abs]
文書分類タスクに対するwhite-box, black-boxともに使用できる敵対的攻撃であるTEXTBUGGERを提案した。TEXTBUGGERは前に紹介したDEEPWORDBUGと同じように分類する際に重要となる単語を推定し、その単語に5種の変換の中から最も分類精度を下げる変換を行う。 以下の表は5つの変換を表す。
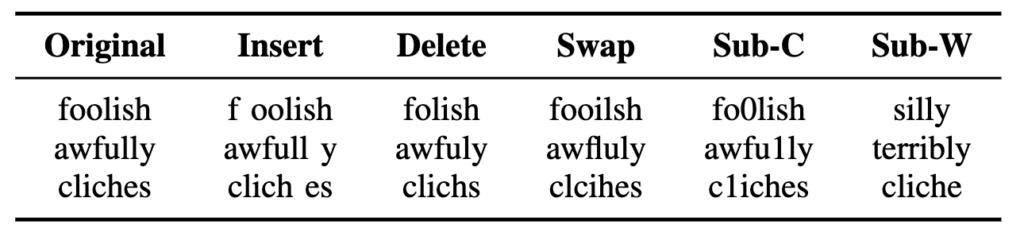
Sub-Cは視覚的に似ている文字へ置換、sub-Wはword vecterの近傍の上位k個から選択している。以下はTEXTBUGGERによって生成されたadversarial exsampleを示す。

赤文字が修正した部分。2段目では否定的な単語に対して変化を加えることが出来ている。
評価にはAmazon AWSとMicrosoft Azureのプラットフォームを用いて、100%攻撃が成功していることを示した。
White-to-Black: Efficient Distillation of Black-Box Adversarial Attacks [arxiv abs]
文書分類タスクに対するblack-boxの敵対的攻撃手法。 White-boxの攻撃手法であるHotflip(単語内の文字入れ替えなど、multi-levelで説明)から敵対的な文章を作成し、その機構を模倣する小さいネットワークを作成した。この蒸留されたネットワークをDISTFLIPとよび、black-boxの攻撃手法として使用した。 大まかな機構は以下の図の様になっている。

Hotflipを用いてadversarial exsampleを生成し、通常の文(GT)とadversarial exsampleのペアを用意する。そのペアを用いて以下のモデルで学習を行う。
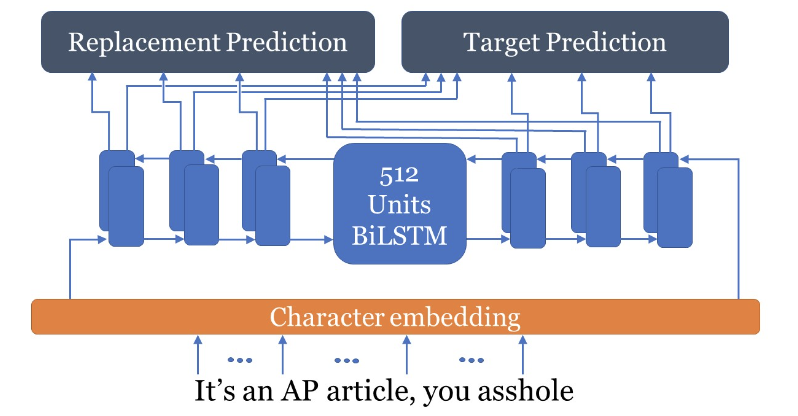
GTを文字単位で入力し、その文字が置換するかどうかの予測と置換する文字を予測するように学習する。このときのラベルはadversarial exsampleを用いる。
評価にはThe Google Perspective APIを用いて、毒性コメントの検出率が低下することを確認。既存の手法より、adversarial exsampleの高速な生成を実現した。
Deceiving Google’s Perspective API Built for Detecting Toxic Comments [arxiv abs]
文書分類タスクに対するblack-boxの敵対的攻撃手法。 上記の論文の評価にも使用されたPerspectiveという毒性のコメントを検出するAPIに対して、毒性の高い単語の間にスペースやドット(.)を入れたり、文字を入れ替えることで毒性のスコアが低下することを示した。 以下の表は加えた変換と毒性スコアの推移を表している。

議論
今回は言語処理タスクにおける文字レベルの敵対的攻撃手法について説明した。基本的に文字を入れ替えたり、消したりするだけで予測を変えることが出来ることがわかった。 近年ではSNSの復旧により、悪性なコメントの検出は重要な課題となってくるが、本ブログで紹介した攻撃手法は誰でも簡単に(機械学習の知識がなくても)実践できる。今後は言語処理における敵対的攻撃の防御手法に注力していくことが必要だと感じた。(今後defence編も更新します)
紹介した手法のいくつかは予測に寄与する単語を選択し、その単語に対して変換を行うものであった。 Attention機構のように解釈性を提示するモデル(XAI)が流行しているが、これらの攻撃手法の手助けになることも考えられる。
日本語や中国語は英語と比べ1文字の情報量が高いと言われているので、そういった部分の確認をしてみたい。 また漢字は1つ文字を2つに分割といったこともできる(神 → ネ 申)。こういった言語の特徴的な部分に着目したadversarial attackもサーベイしたいと考えている。
次回はword-levelの攻撃手法を紹介する。