Adversarial Robustness Toolbox(ART)は、AI*1セキュリティのためのPythonライブラリです。
ARTを使用することで、AIに対する攻撃手法(敵対的サンプル攻撃、データ汚染攻撃、モデル抽出、メンバーシップ推論など)とそれらに対する防御手法を検証することができます。攻撃からAIを守るためには、攻撃のメカニズムと適切な防御手法の理解が必要です。そこで本コラムでは、ARTを通してAIの安全を確保する技術を学んでいきます。
第3回は、回避攻撃の対策の一つであるAdversarial Trainingを実践します。
Adversarial Training(敵対的学習)とはAIの頑健性を高める防御手法であり、学習時に敵対的サンプルの特徴を学習することで、敵対的サンプルによる誤分類を抑制します。
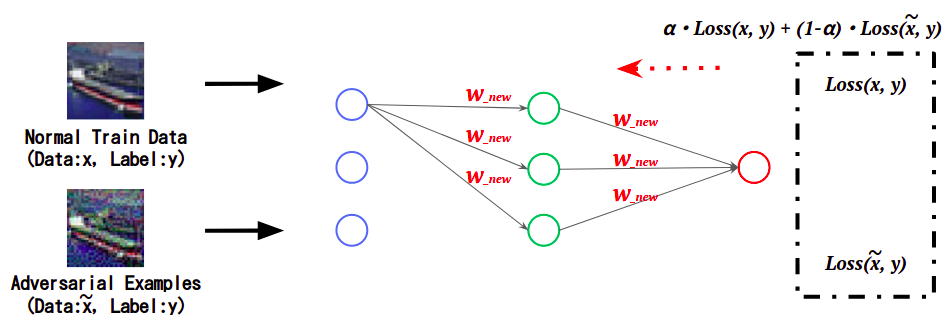
下図は、AIの学習時において、正常データと敵対的サンプルに対する誤差(Loss)をそれぞれ計算し、これを足し合わせた値を基にAIの重みを更新することで、敵対的サンプルの特徴を学習している様子を表しています。
- Adversarial Trainingの概念図

このように、敵対的サンプルの特徴を学習したAIは、敵対的サンプルを正しい(本来の)クラスに分類します。
今回は、ARTに実装されているEnsemble Adversarial Trainingを使用し、Adversarial Trainingを実践します。
| *1..本コラムにおけるAIの定義 |
|---|
| 本コラムでは、画像分類や音声認識など、通常は人間の知能を必要とする作業を行うことができるコンピュータシステム、とりわけ機械学習を使用して作成されるシステム全般を「AI」と呼称することにします。 |
| 注意 |
|---|
| 本コラムは、AIの安全を確保する技術を理解していただくために書かれています。本コラムの内容を検証する場合は、必ずご自身の管理下にあるシステムにて、ご自身の責任の下で実行してください。許可を得ずに第三者のシステムで実行した場合、法律により罰せられる可能性があります。 |
本コラムの内容を深く理解するには、敵対的サンプルの基本知識を有していることが好ましいです。
敵対的サンプルをご存じでない方は、事前にAIセキュリティ超入門:第2回 AIを騙す攻撃 – 敵対的サンプル –をご覧ください。
ハンズオン
本コラムは、実践を通じてARTを習得することを重視するため、ハンズオン形式で進めていきます。
ハンズオンは、皆様のお手元の環境、または、筆者らが用意したGoogle Colaboratory*2にて実行いただけます。
Google Colaboratoryを利用してハンズオンを行いたい方は、以下のURLにアクセスしましょう。
Google Colaboratory:ART超入門 – 第3回:回避攻撃の対策 Adversarial Training 編 –
| *2:Colaboratoryを使用するために |
|---|
| Google Colaboratoryを利用するためにはGoogleアカウントが必要です。 お持ちでない方は、お手数ですが、先にGoogleアカウントの作成をお願いします。 |
お手元の環境でハンズオンを行いたい方は、以下の解説に沿ってコードを実行してください。
事前準備
ARTのインストール
ARTはPythonの組み込みライブラリではないため、インストールします。
# [1-1]
# ARTのインストール。
pip3 install adversarial-robustness-toolbox
ライブラリのインポート
ARTや画像分類器の構築に必要なライブラリをインポートします。
本ハンズオンでは、TensorFlowに組み込まれているKerasを使用して画像分類器を構築するため、Kerasのクラスをインポートします。
また、ARTでAdversarial Trainingを実行するクラスAdversarialTrainerなどもインポートします。
# [1-2]
# 必要なライブラリのインポート
import random
import numpy as np
import matplotlib.pyplot as plt
# TensorFlow with Keras.
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Conv2D
from tensorflow.keras.layers import MaxPooling2D, GlobalAveragePooling2D, Dropout
tf.compat.v1.disable_eager_execution()
# ART
from art.defences.trainer import AdversarialTrainer
from art.attacks.evasion import FastGradientMethod
from art.estimators.classification import KerasClassifier
データセットのロード
標的とする画像分類器の学習データとして、CIFAR10を使用します。
# [1-3]
# CIFAR10のロード。
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
# CIFAR10のラベル。
classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
num_classes = len(classes)
CIFAR10の収録画像を確認します。
ロードしたデータセットから25枚の画像をランダム抽出し、画面上に表示します。
# [1-4]
# データセットの可視化。
show_images = []
for _ in range(5 * 5):
show_images.append(X_train[random.randint(0, len(X_train))])
for idx, image in enumerate(show_images):
plt.subplot(5, 5, idx + 1)
plt.imshow(image)
# 学習データ数、テストデータ数を表示。
print(X_train.shape, y_train.shape)
CIFAR10には'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'の10クラスの画像が60,000枚収録されています。
内訳は学習データ:50,000枚、テストデータ:10,000枚収録されており、各画像は32×32ピクセルのRGB形式です。
データセットの前処理
データセットを正規化し、ラベルをOne-hot-vector形式に変換します。
# [1-5]
# 正規化。
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
# ラベルをOne-hot-vector化。
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
攻撃対象モデルの作成
回避攻撃の標的とする画像分類器を作成します。
モデルの定義
本ハンズオンでは、以下に示すCNN(Convolutional Neural Network)を定義します。
# [1-6]
# モデルの定義。
def define_model():
inputs = Input(shape=(32, 32, 3))
x = Conv2D(64, (3, 3), padding='SAME', activation='relu')(inputs)
x = Conv2D(64, (3, 3), padding='SAME', activation='relu')(x)
x = Dropout(0.25)(x)
x = MaxPooling2D()(x)
x = Conv2D(128, (3,3), padding='SAME', activation='relu')(x)
x = Conv2D(128, (3,3), padding='SAME', activation='relu')(x)
x = Dropout(0.25)(x)
x = MaxPooling2D()(x)
x = Conv2D(256, (3,3), padding='SAME', activation='relu')(x)
x = Conv2D(256, (3,3), padding='SAME', activation='relu')(x)
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
x = Dropout(0.25)(x)
y = Dense(10, activation='softmax')(x)
model = Model(inputs, y)
# モデルのコンパイル。
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()
return model
model = define_model()
Keras Classifierの適用
ARTでAdversarial Trainingを行うためには、ARTが提供するラッパークラスで保護対象の画像分類器をラップする必要があります。
https://adversarial-robustness-toolbox.readthedocs.io/en/latest/modules/estimators/classification.html#keras-classifier
ARTにはTensorFlow, PyTorch, Scikit-learnなど、様々なフレームワークで作成したモデルをラップするクラスが用意されていますが、本ハンズオンではKerasを使用して分類器を作成しているため、KerasClassifierを使用します。
- KerasClassifierの引数
model:攻撃対象となる学習済み分類器を指定します。clip_values:入力データの特徴量の最小値と最大値を指定します。use_logits:分類器の出力形式がロジットの場合はTrue、確率値の場合はFalseを指定します。
# [1-7]
# 入力データの特徴量の最小値・最大値を指定。
# 特徴量は0.0~1.0の範囲に収まるように正規化しているため、最小値は0.0、最大値は1.0とする。
min_pixel_value = 0.0
max_pixel_value = 1.0
# モデルをART Keras Classifierでラップ。
classifier = KerasClassifier(model=model, clip_values=(min_pixel_value, max_pixel_value), use_logits=False)
モデルの学習
学習データX_train, y_trainを使用して画像分類器の学習を行います。
ハンズオン時間を短縮するため、エポック数は30に設定しています。
# [1-8]
# 学習の実行。
classifier.fit(X_train, y_train,
batch_size=512,
nb_epochs=30,
validation_data=(X_test, y_test),
shuffle=True)
モデルの精度評価
テストデータX_testを使用し、作成した画像分類器の推論精度を評価します。
# [1-9]
# モデルの精度評価。
predictions = classifier.predict(X_test)
accuracy = np.sum(np.argmax(predictions, axis=1) == np.argmax(y_test, axis=1)) / len(y_test)
print('Accuracy on benign test example: {}%'.format(accuracy * 100))
おそらく、推論精度は80%程度になったと思います。
敵対的サンプルの作成
ARTを使用し、回避攻撃を行う敵対的サンプルを作成します。
FGSMの実行
ARTに実装されているFGSMを使用し、敵対的サンプルを作成します。
https://adversarial-robustness-toolbox.readthedocs.io/en/latest/modules/attacks/evasion.html#fast-gradient-method-fgm
FGSMのクラスFastGradientMethodの引数として、ラップした分類器と摂動(微小な変化)の量を指定します。
FastGradientMethodの引数estimator:攻撃対象分類器をラップしたKerasClassifierを指定します。eps:敵対的サンプルに加える摂動の量を指定します。
# [1-10]
# FGSMインスタンスの作成。
attack = FastGradientMethod(estimator=classifier, eps=0.1)
上記のように、FastGradientMethodの引数に必要な引数を指定するのみで、敵対的サンプルを作成することができます。
なお、第2引数に指定されたepsの値に比例して攻撃の成功率(誤分類が誘発される確率)が高まりますが、(ノイズが多くなるため)見た目に不自然な画像になります。
よって、攻撃の成功率と敵対的サンプルの見た目の自然さはトレードオフの関係になります。
次に、FGSMインスタンスのgenerateメソッドを使用し、敵対的サンプルを生成します。
generateの引数x:敵対的サンプルのベースとなる正常データ(画像)を指定。
# [1-11]
# 敵対的サンプルの生成(ベース画像はテストデータとする)。
X_test_adv = attack.generate(x=X_test)
推論の実行
生成した敵対的サンプルを画像分類器に入力し、推論精度を評価します。
# [1-12]
# 敵対的サンプルを使用して画像分類器の推論精度を評価。
all_preds = classifier.predict(X_test_adv)
accuracy = np.sum(np.argmax(all_preds, axis=1) == np.argmax(y_test, axis=1)) / len(y_test)
print('Accuracy on Adversarial Exmaples: {}%'.format(accuracy * 100))
正常なテストデータの場合と比較して、著しく推論精度が下がっていることが分かります。
この結果から、敵対的サンプルによって誤分類が誘発されていると推察されます。
次に、正常データと敵対的サンプルの推論結果を視覚的に確認します。
先ずは正常データを推論します。
# [1-13]
# 正常なデータ(摂動が加えられる前のデータ)。
target_index = 2
plt.imshow(X_test[target_index])
# 正常データの推論
pred = classifier.predict(X_test[target_index][np.newaxis, ...])
# 推論結果の表示。
print('True label: "{}"\nPrediction: "{}"'.format(classes[np.argmax(y_test[target_index])], classes[np.argmax(pred)]))
表示された画像が、画像分類器に入力された正常データです。
おそらく、実際のラベルTrue labelと画像分類器の予測ラベルPredictionは一致していると思います。
次に敵対的サンプルを推論します。
# [1-14]
# 敵対的サンプル。
plt.imshow(X_test_adv[target_index])
# 敵対的サンプルの推論。
pred_adv = classifier.predict(X_test_adv[target_index][np.newaxis, ...])
# 推論結果の表示。
print('True label: "{}"\nPrediction: "{}"'.format(classes[np.argmax(y_test[target_index])], classes[np.argmax(pred_adv)]))
表示された画像が、画像分類器に入力された敵対的サンプルです。
摂動の影響によりノイズが乗っていますが、見た目にはTrue labelで示された画像に見えると思います。
しかし、実際のラベルTrue labelと画像分類器の予測ラベルPredictionは一致していないと思います。
このように、FGSMで摂動を加えることで、人間の見た目とは異なるクラスに誤分類されていることが分かります。
※攻撃が上手くいかなかった方は、[1-13]のtarget_indexや[1-10]のepsを変えるなどして試行錯誤してみてください。
Adversarial Training
ARTを使用し、Adversarial Trainingを実行します。
AdversarialTrainerの適用
ARTにはAdversarial Training用のクラスAdversarialTrainerが用意されているため、これを使用します。
https://adversarial-robustness-toolbox.readthedocs.io/en/latest/modules/defences/trainer.html#adversarial-training
AdversarialTrainerの引数- classifier:保護対象のモデルを指定します。
本ハンズオンでは、新たな分類器robustness_classifierを作成し、Adversarial Trainingを適用します。 - attacks:敵対的サンプルを作成するためのインスタンスを指定します。
本ハンズオンでは、[1-10]で作成したFastGradientMethodのインスタンスを指定します。 - ratio:学習データに対する敵対的サンプルの作成に使用するデータの割合を指定します。
例)ratio=0.5の場合、学習データの半分を敵対的サンプルの作成およびAdversarial Trainingに使用します。
- classifier:保護対象のモデルを指定します。
# [1-15]
# Adversarial Trainingインスタンスの作成。
robustness_classifier = KerasClassifier(model=define_model(), clip_values=(min_pixel_value, max_pixel_value), use_logits=False)
defense = AdversarialTrainer(classifier=robustness_classifier, attacks=attack, ratio=0.5)
Adversarial Trainingの実行
学習データX_train, y_trainを使用し、画像分類器のAdversarial Trainingを実行します。
なお、Adversarial Trainingには1時間以上かかる可能性があります。
実行中にGoogle Colabのセッション切れが発生する場合は、エポック数を減らして実行時間を短縮してみてください(ただし、敵対的サンプルへの耐性は下がってしまいます)。
# [1-16]
# Adversarial Trainingの実行。
defense.fit(X_train, y_train,
batch_size=512,
nb_epochs=30,
validation_data=(X_test, y_test),
shuffle=True)
モデルの精度評価
テストデータX_testと敵対的サンプルX_test_advを使用し、画像分類器の精度を評価します。
比較の為に、Adversarial Trainingを適用していない画像分類器classifierの精度も評価します。
# [1-17]
# Adversarial Trainingを適用していない分類器「classifier」。
# テストデータの推論精度を評価。
all_preds = classifier.predict(X_test)
accuracy = np.sum(np.argmax(all_preds, axis=1) == np.argmax(y_test, axis=1)) / len(y_test)
print('Vulnerable classifier: Accuracy on test example: {}%'.format(accuracy * 100))
# 敵対的サンプルの推論精度を評価。
all_preds = classifier.predict(X_test_adv)
accuracy = np.sum(np.argmax(all_preds, axis=1) == np.argmax(y_test, axis=1)) / len(y_test)
print('Vulnerable classifier: Accuracy on Adversarial Exmaples: {}%'.format(accuracy * 100))
# Adversarial Trainingを適用した分類器「defense」。
# テストデータの推論精度を評価。
all_preds = defense.predict(X_test)
accuracy = np.sum(np.argmax(all_preds, axis=1) == np.argmax(y_test, axis=1)) / len(y_test)
print('Robustness classifier: Accuracy on test example: {}%'.format(accuracy * 100))
# 敵対的サンプルの推論精度を評価。
all_preds = defense.predict(X_test_adv)
accuracy = np.sum(np.argmax(all_preds, axis=1) == np.argmax(y_test, axis=1)) / len(y_test)
print('Robustness classifier: Accuracy on Adversarial Exmaples: {}%'.format(accuracy * 100))
Vulnerable classifier~で示された箇所が、Adversarial Trainingを適用していない画像分類器の推論精度です。
正常データの推論精度は80%程度、敵対的サンプルの推論精度は著しく低くなっていることが分かります(おそらく10%程度)。
一方、Robustness classifier~で示された箇所が、Adversarial Trainingを適用した画像分類器の推論精度です。
正常データの推論精度は80%程度、敵対的サンプルの推論精度も70〜80%程度になっていることが分かります(※)。Vulnerable classifier~と比較すると大幅に推論精度が改善しています。
※本ハンズオンでは時間短縮のためにエポック数を少なくしていますが、Adversarial Trainingのエポック数を増やすことや、[1-15]のratioを調整することで、更に推論精度を上げることができます。
また、今回は実践しませんが、ARTには学習データを増強しながらAdversarial Trainingを実行するメソッドも用意されています。
このメソッドを使用することで、更に推論精度を高めることができると思われます。
https://adversarial-robustness-toolbox.readthedocs.io/en/latest/modules/defences/trainer.html#art.defences.trainer.AdversarialTrainer.fit_generator
おわりに
本ハンズオンでは「第3回 – 回避攻撃の対策 Adversarial Training編 -」と題し、学習データに敵対的サンプルを混ぜることで、回避攻撃の耐性を高める防御手法を実践しました。
その結果、敵対的サンプルの推論精度を大幅に改善できることが分かりました。
このように、ARTを使用することで容易にAIのセキュリティテストを行うことができるため、ご興味を持たれた方がおりましたら、是非触ってみることをお勧めします。
以上