
本連載は「AIセキュリティ超入門」と題し、AIセキュリティに関する話題を幅広く・分かり易く取り上げ、連載形式でお伝えしていきます。なお、本コラムでは、単にAIに対する攻撃手法や想定されるリスクのみを取り上げるのではなく、AIを攻撃から守る方法や気を付けるべきAI開発のポイントなども取り上げていきます。
AIセキュリティ超入門のコラム一覧
本コラムは全8回の連載形式になっています。
今後、以下のタイトルで順次掲載していく予定*1です。
- 第1回:イントロダクション – AIをとりまく環境とセキュリティ –
- 第2回:AIを騙す攻撃 – 敵対的サンプル –
- 第3回:AIを乗っ取る攻撃 – 学習データ汚染 –
- 第4回:AIのプライバシー侵害 – メンバーシップ推論 –
- 第5回:AIの推論ロジックを改ざんする攻撃 – ノード注入 –
- 第6回:AIシステムへの侵入 – 機械学習フレームワークの悪用 –
- 第7回:AIの身辺調査 – AIに対するOSINT –
- 第8回:セキュアなAIを開発するには? – 国内外のガイドライン –
| *1..順次掲載していく予定 |
|---|
| 予告なしにタイトルは変更される可能性もあります。ご了承ください。 |
本記事の概要
第1回では、イントロダクションとして、AIを取り巻く環境とセキュリティについて全体像を解説いたしました。
本記事は連載第2回目として、「AIを騙す攻撃 -敵対的サンプル-」と題し、映像や音声などAIへの入力データに対して細工をすることによって、意図的にAIを誤認識させる攻撃手法と防御手法の現状についてまとめています。
「AIを騙す」攻撃
ここでは、データを分類するAIを想定します。
いわゆるAI技術と呼ばれるものには、様々な機械学習、ディープラーニングの技術がありますが、何かを分類するAIは基本的にデータの特徴を抽出し、何に分類されるか決定する境界線(以降決定境界とします)を作成します。
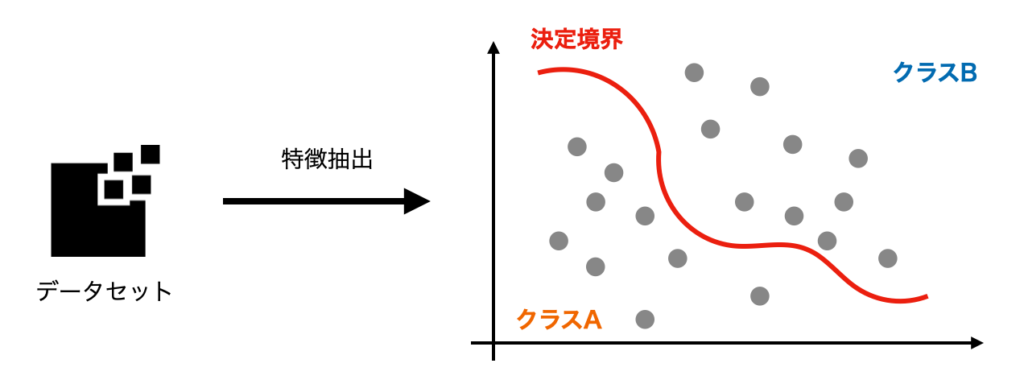
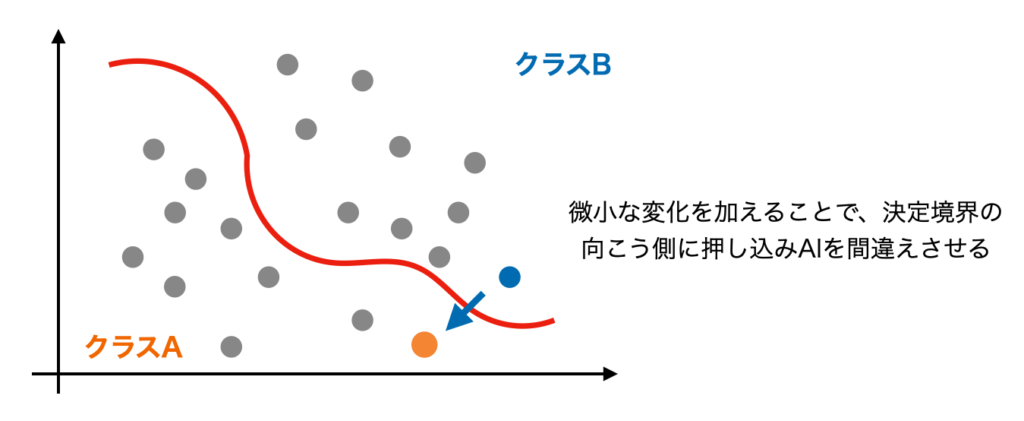
データがこの決定境界を超えて本来と異なる分類をすると、AIは「間違えた」ことになります。
このAIが「間違える」入力データを、人間にはほとんど分からない小さな変化を与えることにより意図的に作る手法を”Adversarial Examples”、日本語で「敵対的サンプル」と呼びます。また、このAdversarial Examplesを用いてAIを騙す攻撃手法を”Adversarial Attacks”と呼ぶこともあります。
基本的な仕組みについて
AIを学習させる際、まず実際に学習データを用いて識別を行い、正解ラベルとの誤差が小さくなるようにパラメータを更新していきます。
この時、誤差が大きくなる変化を計算し、データに加えることによりAIが間違える入力データが作成されます。
様々なAdversarial Examples
Adversarial Patch(敵対的パッチ)
参考文献:
・Fooling automated surveillance cameras: adversarial patches to attack person detection
・Model Hacking ADAS to Pave Safer Roads for Autonomous Vehicles
Adversarial Patchは、映像や画像の中で特定の模様(以降パッチ)を加えることで、AIを騙す手法です。
以下の画像は、人間を検出できるAIに対して、パッチを持った人間が写った時の実験結果になります。

出典:Fooling automated surveillance cameras: adversarial patches to attack person detection
パッチのない人は正しく検出されているのに対し、パッチを持っている人は人間と認識できていません。
このように、入力値の一部分だけに特定のパッチを入れるだけでAIを騙すことに成功しています。
この人物検出AIはYOLOv2と呼ばれる非常に有名な物体検出AIで、このAIを利用した製品は同じパッチで騙すことができ、防犯カメラや自動運転など様々な分野で被害が想定されます。
特に自動運転では、人間以外にも道路標識を誤認識してしまうと大事故につながってしまいます。
既にドライバーサポート機能に対して、速度標識にノイズを載せることで35mph(マイル毎時)制限として認識すべきところを、85mphとして誤認識させることに成功している例もあります。

出典:Model Hacking ADAS to Pave Safer Roads for Autonomous Vehicles
Audio Adversarial Examples(音声の敵対的サンプル)
参考文献:
Audio Adversarial Examplesは、音声に対する敵対的サンプルを作成する手法です。
スマートスピーカーをはじめとする音声認識AIでは、私たちの音声を文字におこす speech-to-text モデルを通じて理解し、動作しています。その音声に対して微小な変化を追加することにより、人間には聞き分けられない変化で全く異なる命令をスマートスピーカーに与えることができるようになります。

出典:Audio Adversarial Examples
これにより、悪意のある命令をスマートスピーカーに与え、鍵を解錠するなどの物理的な被害から、悪質なサイトへのアクセスを行う被害などを人が気づかないまま行われる危険性があります。
言語のAdversarial Examples
参考文献:
自然言語に対するAdversarial Examplesも存在します。文字レベル、単語レベル、文章レベルでそれぞれ攻撃手法が存在しており、英語や日本語などの言語毎の特徴に対しても攻撃手法が別々に存在しています。
自然言語に関しては、大きく2つの攻撃に分けられます。
1. AIと人間両方を騙す攻撃
例としてスパムメールが挙げられます。
スパムメールフィルタを騙した上で、人間も騙してリンクをクリックさせる、返信をさせるなどの行動を起こす目的で利用されます。
2. AIを騙し、人間には理解させる攻撃
例として誹謗中傷コメントが挙げられます。
誹謗中傷などの言葉をフィルタリングするAIを騙した上で、目的の相手に誹謗中傷を投げかける目的で利用されます。
日本語では、例えば「バカ」を「バ力(”ちから”の漢字)」と置き換えると、人間は理解できますがAI上では全く意味のない言葉として通ってしまうケースが多いです。
より現実的な攻撃シナリオ -Black Box Attacks-
参考文献:
必要な事前情報が一切いらず、AIへの入出力データのみでAdversarial Examplesを生成し攻撃を成立させるBlack Boxな攻撃手法も存在します。
例えば、攻撃対象のAIに近いコピーを手元に作成し、コピーしたAIに対するAdversarial Examplesを作成することで、元の攻撃対象のAIも騙せるようになるような手法が存在します。

出典:Practical Black-Box Attacks against Machine Learning
他にも、そもそもコピーを作る作業なしでBlack Box Attacksを成功させる手法などもあります。
このように、事前情報を必要とせず、少量のデータを攻撃対象のAIに通すだけで攻撃が成立してしまうシナリオもあるため、Adversarial AttacksからAIを守る意識は非常に大切になります。
守るための手法
参考文献:
ここまで紹介した様々なAdversarial AttacksからAIを守るための防御手法を幾つか例示します。
注意点として、これから例示する防御手法を破る攻撃手法も研究が進んでいるため、複数の防御手法を組み合わせていくことが重要になります。
Adversarial Training(敵対的学習)
参考文献:
Adversarial Examplesを学習データとして用いることで、AI自身のAdversarial Examplesに対する耐性を上げることができます。
ただ、通常のAdversarial Trainingで堅牢性を高めていくと、ある程度精度の低下や計算コストがかかってしまう場合があります。最近の研究では、通常のAdversarial Trainingと比較して精度の低下や計算コストの増加のない、Smooth Adversarial Trainingと呼ばれる手法などが提案されています。(参考文献参照)
特徴量の絞り込み
参考文献:
画像をぼかして必要最低限の情報のみにするなどの対策を行うことによって、攻撃者がAdversarial Examplesをある程度作成しづらいAIを作成することができます。

出典:Detecting Adversarial Examples in Deep Neural Networks
ネットワークの蒸留
参考文献:
Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks
蒸留は、巨大なネットワークなどをなるべく精度を落とさずに小さいネットワークにする手法ですが、それをAdversarial Examplesから守る手法として用いることができます。
アンサンブルメソッド
複数の(異なるアーキテクチャの)AIを組み合わせて学習することで、頑健性を上げるアンサンブルメソッドが防御手法として有効なケースがあります。
Autoencoderによる検出
参考文献:
PuVAE: A Variational Autoencoder to Purify Adversarial Examples
Autoencoderと呼ばれる、データを圧縮して復元するディープラーニングモデルを用いて、入力されたデータがAdversarial Examplesかどうか検出してしまおうという防御手法が提案されています。
まとめ
本記事では、様々なAdversarial Examplesについて紹介いたしました。
Adversarial Examplesを用いた攻撃は被害がとても大きくなる場合が多く、多様な攻撃手法に対処するため、AIの設計や開発を行う段階で適切な防御手法を取り入れ慎重に運用する必要があります。
AIに対するサイバー攻撃から製品を保護する防御手法をハンズオンで習得するトレーニングをセキュアAI研究所では提供しています。詳細は下記よりご覧ください。
https://jpsec.ai
次回は、第3回「AIを乗っ取る攻撃 – 学習データ汚染 -」について投稿いたします。