概要
「Draft NISTIR 8269: A Taxonomy and Terminology of Adversarial Machine Learning」は、米国のNIST(National Institute of Standards and Technology)が策定を進めている機械学習セキュリティに関するベストプラクティスのドラフトであり、機械学習システムの安全確保を目的として、機械学習にまつわるセキュリティを「攻撃」「防御」「影響」の3つの視点で分類している。
NISTIR8269はブログ執筆時点(2020年7月9日)でドラフト版であるが、「NIST SP800-30:Guide for Conducting Risk Assessments(日本語版:リスクアセスメントの実施の手引き)」への反映を計画しているとの事であり、NISTIR8269の内容が機械学習セキュリティのベストプラクティスになる可能性がある。
そこで本ブログでは、筆者らの知見を交えながらNISTIR8269を解説していく。
本ブログが、セキュアな機械学習システム開発の一助になれば幸いである。
論文情報
公開日
2019-10
著者情報
Elham Tabassi1, Kevin J. Burns2, Michael Hadjimichael2, Andres D. Molina-Markham2, Julian T. Sexton2
- 1..National Institute of Standards and Technology Information Technology Laboratory
- 2..National Cybersecurity Center of Excellence The MITRE Corporation
論文情報・リンク
https://nvlpubs.nist.gov/nistpubs/ir/2019/NIST.IR.8269-draft.pdf
新規性・差分
機械学習セキュリティを「攻撃」「防御」「影響」の視点で分類した文書は殆ど存在しない。
1. はじめに
NISTIR8269は機械学習システムの安全確保を目的とし、機械学習セキュリティを攻撃・防御・影響の視点で分類した文書である。なお、NISTIR8269にはArtificial Intelligence (以下、AI)という言葉が登場するが、これを画像分類や音声認識など、通常は人間の知能を必要とする作業を行うことができるコンピュータシステムとして定義している。本ブログでもこれに倣い、機械学習を使用して作成されるシステム全般を「AI」と呼ぶことにする。
ところで、NISTは何故わざわざ機械学習セキュリティに焦点を当てた文書(NISTIR8269)を作成する必要があったのだろうか?
従来の防御技術でAIの安全は確保できないのだろうか?
AIには「データ」「モデル」「学習」「テスト(推論)」などの様々な要素が絡み合っており、機械学習特有のセキュリティリスクが存在する。それゆえに、従来の防御技術のみでAIを守ることは困難である。幾つか具体例を挙げてみる。
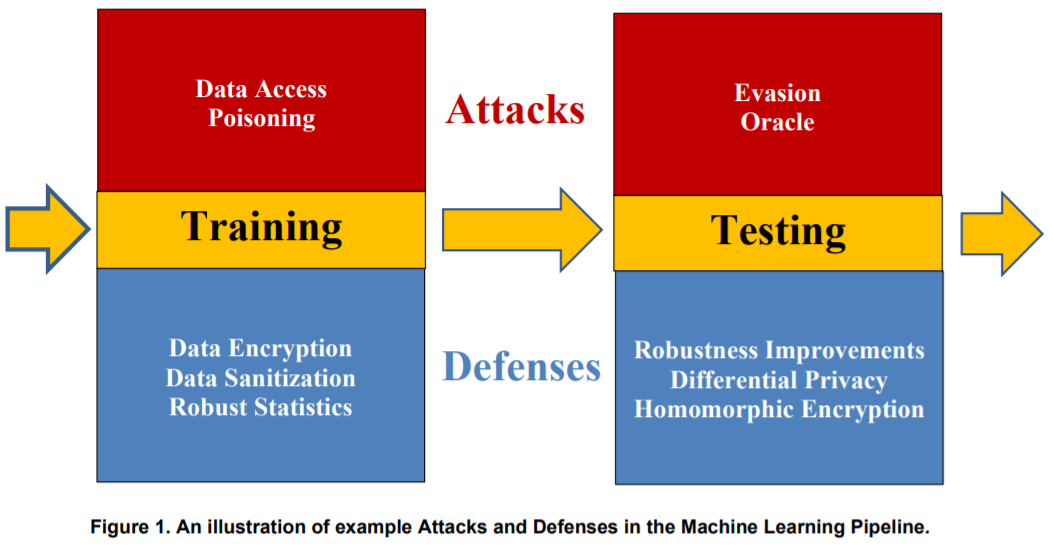
以下の図は、AI開発における「学習(Training)」工程と「テスト(Testing)」工程で起こり得る攻撃と、それに対する防御手法を例示している。
学習(Training)工程では、学習データ汚染攻撃[1](Poisoning)を受ける可能性がある。
学習データ汚染攻撃はAIにバックドア(Trojanとも呼ばれる)を設置する攻撃であり、攻撃者が細工データを標的AIの学習データに注入して汚染するところから攻撃が始まる。AIの開発者が学習データ汚染に気付かずにAIの学習を行った場合、特定の入力データ(以下、トリガー)を攻撃者が意図したクラスに誤分類するように決定境界が歪められることになる。
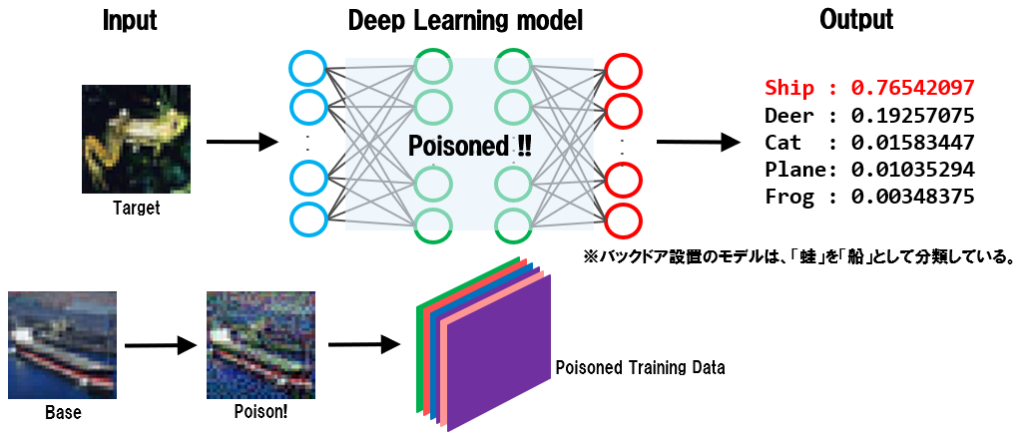
バックドアを活性化するトリガーはノーマルなデータであるため、入力値の検証機構で異常を検知することは困難であり、また、バックドアが設置されたAIはトリガー以外の入力データを正しく分類するため、推論精度が著しく低下することもない(性能低下による異常検知も困難)。なお、学習データを汚染する細工データには摂動が加えられているが、摂動は微細であるため、人間がラベリング工程で細工データを検知・除外することも困難である。学習データ汚染攻撃を防ぐためには、トリガーを検知するSTRIP[2]と呼ばれる機械学習に基づいた技術や、汚染されていないデータで再学習することで決定境界の歪みを解消するなど、AI特有の防御策が必要となる。
次に、テスト(Testing)工程では、細工した入力データを用いて誤分類を誘発[3]する攻撃を受ける可能性がある。
誤分類を誘発する攻撃は、攻撃者がAIへの入力データに微細な摂動を加えることから始まる。この摂動が加えられたデータを敵対的サンプル(Adversarial Examples)と呼び、敵対的サンプルを受け取ったAIは、このデータを攻撃者が意図したクラスに分類してしまうことになる。

引用:セキュアAI研究所, Adversarial Attacks and Defense on Texts: A Survey character-level編
上図は敵対的サンプルを例示している。
左がオリジナルのデータ(画像と音声)、真ん中が摂動、右が敵対的サンプルである。見てわかる通り、オリジナルと敵対的サンプルには殆ど違いが見られないため、敵対的サンプルを検知・除外することは非常に困難である。なお、敵対的サンプルは画像や音声以外にも、文書やテーブルデータ[4]など、様々なデータで作成することができる。誤分類を誘発する攻撃を防ぐためには、後述する敵対的学習(Adversarial Training)や防御のための蒸留(Defensive Distillation)、アンサンブル・メソッド(Ensemble Method)などの機械学習に基づいた対策を行い、AIの頑健性を向上させる必要がある。
このように、AIには特有の攻撃手法と防御手法が存在する。
なお、上記以外にも多くの攻撃手法と防御手法が存在するが、これらはベストプラクティスとして体系化されていないのが現状である。それゆえにAIの開発者は、どのようにしてAIの安全を確保するのか、その指針となる情報にアクセスすることが困難である。
そこでNISTIR8269では、機械学習セキュリティに関する論文をサーベイし、機械学習にまつわるセキュリティを攻撃(Attacks)、防御(Defenses)、影響(Consequences)の3つの視点で分類している。以下に各視点の要点を示す。
| 視点 | 定義 |
|---|---|
| 攻撃(Attacks) | AIへの攻撃経路や攻撃手法など、攻撃にまつわるあらゆる情報を定義。 |
| 防御(Defenses) | AIへの攻撃に対するあらゆる防御の観点・手法を定義。 |
| 影響(Consequences) | AIが攻撃を受けた際に生じる影響を定義。 NISTIR8269では「Consequences」であるが、本ブログでは「(攻撃の結果として生じる)影響」とする。 |
なお、NISTIR8269で取り扱うセキュリティの問題は、上述したような学習データ汚染や敵対的サンプルなどの意図的な攻撃であり、設計の不備や学習データの偏りで生じる(意図しない)問題は対象外とする。また、機械学習セキュリティの研究は盛んに行われており、日々新たな攻撃手法・防御手法が生まれていることを鑑み、NISTIR8269は網羅性を保証しないことに注意されたい。
2. 機械学習セキュリティの分類
NISTIR8269では機械学習セキュリティを分類するにあたり、以下の論文をサーベイしている。
※各論文の詳細は、巻末の「参考文献」を参照のこと。
- Huang, “Adversarial Machine Learning”(2011)[5]
- Akhtar, “Threat of adversarial attacks on deep learning in computer vision: A survey”(2018)[6]
- Biggio, “Wild patterns: Ten years after the rise of adversarial machine learning”(2018)[7]
- Chakraborty, “Adversarial Attacks and Defences: A Survey”(2018)[8]
- Liu, “A survey on security threats and defensive techniques of machine learning: A data driven view”(2018)[9]
- Papernot, “SoK: Security and privacy in machine learning”(2018)[10]
- Kuznetsov, “Adversarial Machine Learning”(2019)[11]
- Goodfellow, “Making machine learning robust against adversarial inputs”(2018)[12]
- Yuan, “Adversarial examples: Attacks and defenses for deep learning”(2019)[13]
- Papernot, “Practical black-box attacks against machine learning”(2017)[14]
- Papernot, “The limitations of deep learning in adversarial settings”(2016)[15]
- Barreno, “The security of machine learning”(2010)[16]
- Barreno, “Can machine learning be secure?”(2006)[17]
これらの論文は、機械学習セキュリティに関する様々なトピックを扱っている。
例えば、Akhtar[6]らはコンピュータビジョン・アプリケーションに対する攻撃手法と防御手法を深堀している。一方、Biggio[7]らは機械学習セキュリティの進化の歴史を紐解き、コンピュータビジョンに関するセキュリティ課題を幅広く調査している。また、Charkraborty[8]、 Liu[9]、Papernot(2018)[10]らは特定の分野に焦点を当てず、様々な分野に跨る攻撃手法と防御手法の分類を試みている。
NISTIR8269では、上記の論文で扱われている攻撃手法・防御手法などを整理し、これらを攻撃(Attacks)、防御(Defenses)、影響(Consequences)の視点で以下のように分類している。

以下、各分類について解説していく。
2.1. 攻撃(Attacks)
攻撃(Attacks)の視点では、攻撃対象、攻撃手法、そして、攻撃に必要な前提知識など、攻撃に関連するあらゆる事柄を定義している。
NISTIR8269では攻撃の視点を更に以下3つに分類している。
- 攻撃(Attacks)
- 前提知識(Knowledge)
- 攻撃対象(Targets)
- 攻撃手法(Techniques)
2.1.1. 前提知識(Knowledge)
前提知識(Knowledge)とは、攻撃者が有している標的AIに関する知識である。
攻撃の成否は前提知識に左右されるが、NISTIR8269では前提知識(Knowledge)を以下3つに分類している。
- 前提知識(Knowledge)
- ブラックボックス(Black Box)
- サンプル(Samples)
- シャドウモデル(Oracle)
- グレーボックス(Gray Box)
- アーキテクチャ(Model Architecture)
- ハイパーパラメータ(Parameters Values)
- 学習方法:損失関数(Training Method (Loss Function))
- 学習データ(Training Data)
- ホワイトボックス(White Box)
- ブラックボックス(Black Box)
ブラックボックス(Black Box)
ブラックボックスは、攻撃者が標的AIの内部情報を一切有していない状態である。
すなわち、攻撃者は標的AIのサンプル(Samples:AIへの入力データとAIから応答される出力データ)以外の情報は有していないことになる。
グレーボックス(Gray Box)
グレーボックスは、攻撃者が標的AIの内部情報を部分的に有している状態である。
すなわち、攻撃者は標的AIのアーキテクチャ(Model Architecture)、ハイパーパラメータ(Parameters Values)、学習方法(損失関数:Loss Function)、そして、学習データ(Training Data)に関する知識を断片的に有していることになる。
ホワイトボックス(White Box)
ホワイトボックスは、攻撃者は標的AIの内部情報を完全に有している状態である。
すなわち、アーキテクチャ、ハイパーパラメータ、学習方法(損失関数)、そして、学習データに関する知識を全て有していることになる。
上記3つを比べてみると、(内部犯行やソーシャルエンジニアリングなどで情報が窃取された場合を除き)現実的な攻撃はブラックボックスの状態で行われることが多いと思われる。しかし、ブラックボックスでは標的AIの知識を殆ど持たない状態で攻撃を行う必要があるため、攻撃は不可能のように思われるかもしれない。しかし、シャドウモデル(代替モデルとも言う)を使用することで効果的に攻撃を行うことができる。シャドウモデルを少し補足する。
シャドウモデル
シャドウモデルとは、攻撃者が効率よくブラックボックスな状態で攻撃を行うために使用するモデルであり、標的AIを様々な角度から観察して情報を収集し、標的AIを模倣して作成される。敵対的サンプルを例にとると、通常、敵対的サンプルを作成するには、標的AIに関する情報(特徴抽出器など)が必要である。しかし、ブラックボックスではそれを知る由がない。そこで、攻撃者は標的AIの学習データ分布などを推測し、標的AIに似せたシャドウモデルを手元に作成する。そして、これを使用して(ホワイトボックスの状態で)敵対的サンプルを作成する。
ところで、シャドウモデルと標的AIは学習データ分布やアーキテクチャなどが一致するとは限らない。ゆえに、シャドウモデルで作成した敵対的サンプルは標的AIに効かないのでは?と疑問に思うかもしれない。しかし、敵対的サンプルについて書かれた著名な論文「Intriguing properties of neural networks[28]」には次のように書かれている。
- とある学習データを学習したモデルの敵対的サンプルは、異なるデータで学習したモデルにも有効である。
- とあるモデルの敵対的サンプルは、異なるアーキテクチャのモデルにも有効である。
つまり、攻撃者はシャドウモデルで作成した敵対的サンプルを用いて標的AIを攻撃することができる(※)。このような特性を、敵対的サンプルの転移性(Adversarial example transferability)と呼ぶ。この転移性ゆえに、攻撃者はブラックボックスの状態でも効率よく攻撃を行うことができるのである。
※シャドウモデルと標的AIのアーキテクチャの組み合わせや、(後述する)敵対的サンプルの作成方法などによっては、効果が無い場合もある。
2.1.2. 攻撃対象(Targets)
攻撃対象(Targets)とは、攻撃の対象となり得るモデルの種類や攻撃を実行するドメインなどである。
NISTIR8269では攻撃対象(Targets)を以下3つに分類している。
- 攻撃対象(Targets)
- 物理ドメイン(Physical Domain)
- デジタル表現(Digital Representation)
- 機械学習モデル(Machine Learning Models)
- 教師あり学習(Supervised Learning)
- 教師なし学習(Unsupervised Learning)
- 強化学習(Reinforcement Learning)
物理ドメイン(Physical Domain)
物理ドメイン(Physical Domain)は、実世界の景色や音などの情報がカメラやマイクで取り込まれてデジタル化される前の状態を指す。
物理ドメインにおける攻撃は、実世界のオブジェクト(道路標識など)や身の回りの音(声やBGMなど)に細工を施すことで実行される。
具体例を幾つか示す。
以下は、特殊なパッチ柄をプリントした紙を使用し、物体認識モデルによる人物検知を回避する例を示している。
ノーマルな人物は「person」として認識されている一方で、パッチ柄を持った人物は一切検知されていないことが分かる。パッチ柄はファッションアイテムにプリントすることもできるため、周囲から怪しまれずに物体認識を回避することができる。

以下は、道路標識に(シールを貼るなどの)細工を施すことで、高度ドライバー支援システム(ADAS)の道路標識認識を騙す例を示している。
人間の目には道路標識の細工は認識できないが、ADASの道路標識認識モデルは本来35mph(マイル毎時)制限として認識すべきところを、85mphとして誤認識していることが分かる。

上記の例はカメラに映るオブジェクトを細工する手法だが、音声を細工して音声認識モデルを騙すこともできる。
以下は、細工した音楽をBGMとして流すことで、スマートスピーカーなどに内蔵されている音声認識モデルを騙す例を示している。人間がスマートスピーカーに発した音声コマンドを、細工したBGMによって全く異なる音声コマンドに変更することができる。
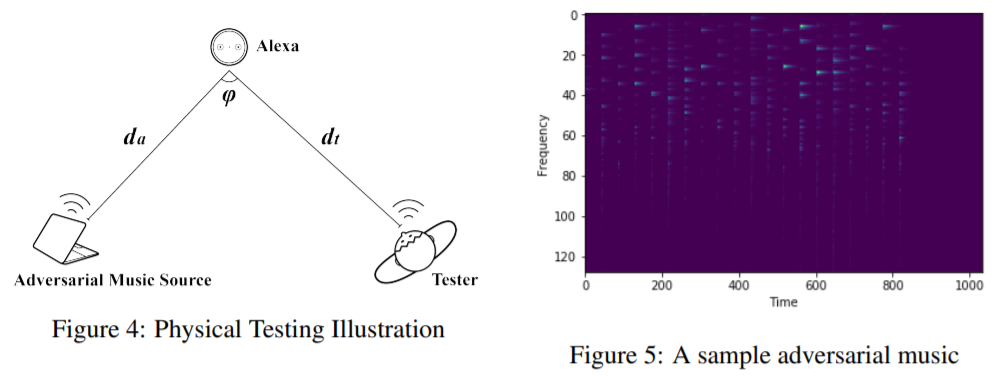
ここでは3つの例を紹介した。
物理ドメインにおける攻撃は、ライティングや周囲のノイズなどに影響を受けるため攻撃のハードルは高く、それゆえに論文や検証事例は少ない。しかし、上記で示したように、細工の仕方を工夫することで現実的に攻撃を行うことは可能である。
デジタル表現(Digital Representation)
デジタル表現(Digital Representation)は、実世界の景色や音などの情報がカメラやマイクで取り込まれてデジタル化された後の状態を指す。
デジタル表現における攻撃は、画像データや音声データなどのデジタルなデータに直接細工を施すことで実行される。
具体例を幾つか示す。
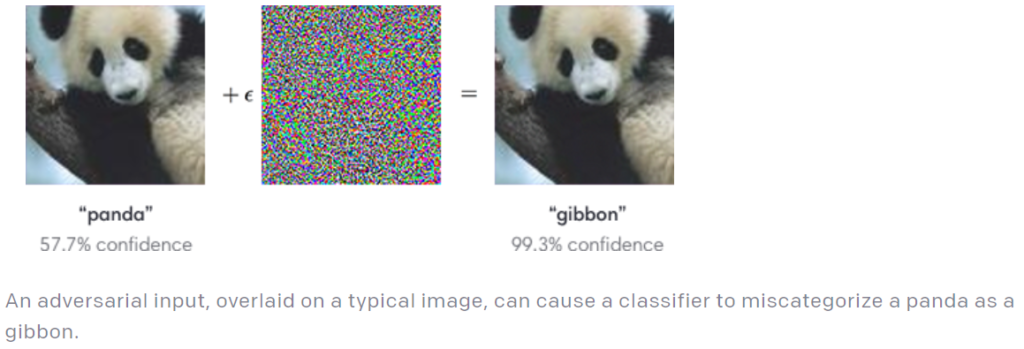
以下は、パンダ画像に摂動を加えて敵対的サンプルを作成し、画像分類器を騙す例を示している。
人間の目にはパンダに見えるが、画像分類器はテナガザル(gibbon)として認識していることが分かる。
以下は、デジタル文章の単語を巧みに置換することで、文書分類器を騙す例を示している。
文章内の単語を(文脈を壊さないように)別単語に置き換えることで、文書分類器のネガポジ判定結果が反転していることが分かる。なお、置換された単語はスペル誤りなどが散見されるものの、ただのTYPOとして許容されるものが多いため、人間が細工に気付くことは困難である。

ここでは2つの例を紹介したが、その他にもテーブルデータや音声データを細工する手法も存在する。
デジタル表現における攻撃は、物理ドメインの攻撃と比較して攻撃のハードルが低いため、多くの論文や検証事例が発表されている。
機械学習モデル(Machine Learning Model)
機械学習モデル(Machine Learning Model)は、攻撃対象となり得るモデルの種類(作成アプローチ)を指す。
NISTIR8269では以下3つのモデルを定義している。
- 機械学習モデル(Machine Learning Models)
- 教師あり学習(Supervised Learning)
- 教師なし学習(Unsupervised Learning)
- 強化学習(Reinforcement Learning)
機械学習セキュリティの研究の多くは、画像分類器に多く利用されている教師あり学習で作成されたモデルに焦点が当てられている。
しかし、教師あり学習と比べて論文や検証事例は少ないものの、強化学習モデルに対する攻撃手法も存在する。以下に一例を示す。
- 強化学習に対する攻撃手法
- Policy Teaching via Environment Poisoning: Training-time Adversarial Attacks against Reinforcement Learning[23]
- Adaptive Reward-Poisoning Attacks against Reinforcement Learning[24]
- Data Poisoning Attacks on Stochastic Bandits[25]
- Data Poisoning Attacks in Contextual Bandits[26]
- Gradient Band-based Adversarial Training for Generalized Attack Immunity of A3C Path Finding[27]
報酬や環境の汚染など、強化学習特有の構成要素を対象とした攻撃手法が提案されている。
2.1.3. 攻撃手法(Techniques)
攻撃手法(Techniques)とは、標的AIに対する具体的な攻撃手法である。
NISTIR8269では、攻撃を実行するタイミングを以下2つに分類し、工程毎に攻撃手法を定義している。
- 攻撃手法(Techniques)
- 学習工程(Training)
- テスト工程(Inference)
学習工程(Training)
学習工程(Training)は、学習データの収集や前処理、そして、モデルの学習などを実施する工程である。
本工程では、シャドウモデルを作成するための探索行為や、バックドアを設置するための学習データ汚染やモデル(アーキテクチャ)汚染が行われる可能性がある。
- 学習工程(Training)
- 探索行為(Data Access)
- 汚染(Poisoning)
探索行為(Data Access)は、攻撃者がシャドウモデルを作成するために標的AIに関する情報を収集する行為である。
攻撃者の前提知識がグレーボックスやホワイトボックスの状態では、攻撃者は直接学習データやパラメータにアクセスして情報を収集する。一方、ブラックボックスの状態では、標的AIへのクエリアクセスとそれに対する応答を複数観察することで、標的AIの内部情報を推測する(メンバーシップ推論など。詳細は後述)。
汚染(Poisoning)は、間接的(Indirect Poisoning)または直接的(Direct Poisoning)に学習データやモデルを細工(汚染)し、標的AIにバックドアを設置したり、標的AIの推論性能を低下(サービス拒否)させる行為である。NISTIR8269では、汚染を間接的・直接的の2つに分類している。
- 汚染(Poisoning)
- 間接的な汚染(Indirect Poisoning)
- 直接的な汚染(Direct Poisoning)
- データ注入(Data Injection)
- データ操作(Data Manipulation)
- ラベル操作(Label Manipulation)
- 入力データ操作(Input Manipulation)
- ロジック改変(Logic Corruption)
なお、NISTIR8269では、汚染(Poisoning)には「標的型汚染(Error-specific poisoning)」と「非標的型汚染(Error-generic poisoning)」の2つが存在するとしており、標的型汚染はバックドアを設置する行為(トリガーを特定のクラスに誤分類させる)、非標的型汚染は可能な限り多くのデータを汚染してサービス拒否を引き起こさせる行為として定義している。
間接的な汚染(Indirect Poisoning)
攻撃者が標的AIの学習データやモデルに直接アクセスできない場合でも、間接的に汚染を実行することが可能である。
例えば、上述した学習データ汚染によってAIにバックドアを設置する攻撃では、下図のように細工したデータをインターネット上にばら撒いておき、細工データが標的AIの学習データに取り込まれるのを待つ方法がある(細工データは標的AIの決定境界を歪ませる役割を持つ)。クローラーを使用してインターネット上から学習データを自動収集している場合は、間接的に学習データが汚染され、バックドアが設置される可能性がある。

また、学習データの作成を信頼できない外部業者に委託している場合、意図的・偶発的に関わらず学習データが汚染される可能性もある。例えば、ナイフ画像に”鉛筆”ラベルが付けられることで、AIの推論精度の低下(サービス拒否)や誤分類が引き起こされる可能性も考えられる。
間接的な汚染は学習データのみならず、モデルを汚染することも可能である。
以下は、特定の入力データ(トリガー)で活性化するバックドアを事前学習モデルに埋め込む様子を示している。攻撃者はバックドアを設置した事前学習モデルを作成・配布して攻撃を行う。(推論精度の高さに釣られて)インターネットなどの信頼できないドメインから入手した事前学習モデルを使用してAIを作成した場合、AIにバックドアが設置されることになる。

上記の例は機械学習アルゴリズムに起因する汚染であるが、AI開発時に使用される機械学習プラットフォームの機能を悪用した汚染も存在する。
以下は、TensorFlowのLambdaレイヤーを悪用し、推論の実行時にAIが稼働するシステム上で任意のシステムコマンドを実行する様子を示している。TensorFlowのLambdaレイヤーは任意の関数を定義することが可能であるが、攻撃者はLambdaレイヤーに悪意のあるシステムコマンドを実行する関数を定義し、このレイヤーを含んだ事前学習モデルを作成・配布して攻撃を行う。被害者が細工に気付かずにこのモデルを基にAIを作成した場合、AIが稼働する被害者のシステム上で任意のコマンドが実行されることになる。その結果、データの破壊やシステムの乗っ取り、機微情報の窃取などが発生する。

ここでは3つの間接的な汚染例を紹介した。
なお、バックドアが設置されたAIはトリガー以外のデータは正しく分類するため、AIの推論精度が低下することはない。また、3番目に紹介した例では、AIの推論に影響を与えないようにLambdaレイヤーを事前学習モデルに埋め込むことが可能である。それゆえに、被害者がバックドアに気付くことは困難である。
直接的な汚染(Direct Poisoning)
攻撃者が標的AIの学習データやモデルに直接アクセスできる場合は、細工データを学習データに直接注入(Data Injection)したり、学習データのラベルやデータを直接改ざん(Data Manipulation)することで、標的AIにバックドアを設置することが可能である。また、標的AIのアーキテクチャやパラメータを操作してロジック改変(Logic Corruption)を行うことも可能である。
以下は、システムに侵入した攻撃者が、メモリ上に展開された標的AIのハイパーパラメータ(本例では重み)の値を改ざんすることで、稼働中の標的AIにバックドアを設置する例を示している。バックドアが設置された標的AIは、トリガーとなるスタンプ(図中では4つのドットで表現)が刻まれたデータを受け取ると、これを攻撃者が意図したクラスに分類してしまう。トリガー以外のデータは正常に分類されるため、標的AIにバックドアが設置されたことを検知するのは困難である。

なお、ロジック改変は間接的に実行することも可能である。
以下は、オープンソースソフトウェア(以下、OSS)の損失関数コードを細工し、このOSSを標的AIの開発に使用させることでバックドアを設置する例を示している。損失関数のコードは大規模かつ複雑であるため、コードレビューで細工を検知することは困難である(そもそも、OSSを過信してコードレビューしないケースも考えられる)。
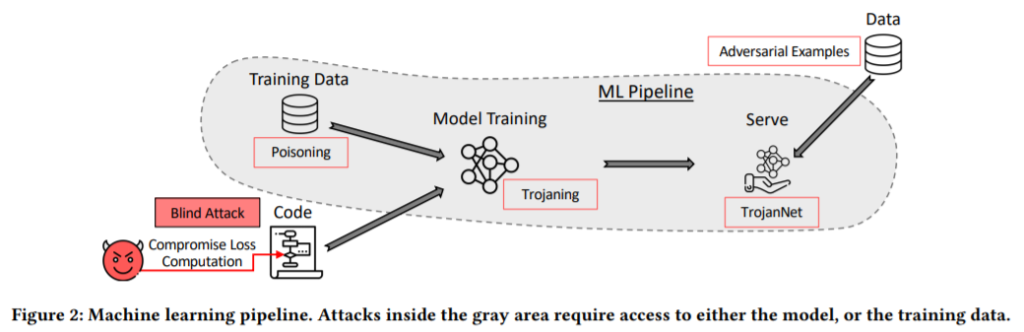
このように、直接的な汚染は間接的な汚染と比べて攻撃の自由度が高く、より確実にバックドアを設置することが可能である。しかし、(内部犯行や何らかの脆弱性を利用してシステムに侵入した場合を除き)そもそも直接データにアクセスすること自体が困難であるため、その分の攻撃のハードルは上がる。
テスト工程(Testing:Inference)
テスト(推論)工程(Testing)は、学習したAIをデプロイし、本番運用する工程である。
本工程では、標的AIへのクエリアクセスを通じて、誤分類を誘発する回避攻撃(Evasion)や、標的AIの決定境界や学習データを窃取する攻撃が行われる可能性がある。
- テスト工程(Testing)
- 回避(Evasion)
- 勾配ベース(Gradient-based)
- シングルステップ(Single Step)
- 反復(Iterative)
- 勾配フリー(Gradient-free)
- 勾配ベース(Gradient-based)
- オラクル(Oracle)
- 抽出(Extraction)
- 反転(Inversion)
- メンバーシップ推論(Membership Inference)
- 回避(Evasion)
なお、NISTIR8269では、回避(Evasion)には「標的型回避(Error-specific evasion)」と「非標的型回避(Error-generic evasion)」の2つが存在するとしており、標的型回避は敵対的サンプルを特定のクラスに誤分類させる行為、非標的型回避は敵対的サンプルを任意のクラスに誤分類させる行為(クラスに関係なく、誤分類させれば良い)として定義している。
回避(Evasion)
回避攻撃は標的AIの誤分類を誘発することを目的としており、敵対的サンプル(Adversarial Examples)を標的AIに入力することで実行される。
ところで、敵対的サンプルはどのようにして作成するのだろうか?作成手法は数多く提案されているが、本ブログでは代表的なアルゴリズムである以下3つを紹介する。
- Limited memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS)
- Fast Gradient Sign Method (FGSM)
- Jacobian-based Saliency Map Attack (JSMA)
上記は何れも勾配ベース(Gradient-based)の摂動探索アルゴリズムが採用されている。
L-BFGSは、敵対的サンプルを生成するために考案された最初のアルゴリズムである。通常のニューラルネットワーク(以下、NN)の学習では、(学習データから取り出した)NNへの入力データを固定し、入力データに対するNNの出力値とラベル(答え)の差分を求める。そして、この差分を基に勾配降下法で重みを更新する処理を何度も反復(Iterative)することで、徐々に入力データに対する正しい答えを導き出せるようになる(NNの学習)。L-BFGSでは、NNの学習とは逆に、重みを固定し、NNへの入力データを変化させていく。
このように、入力データに対する勾配を見ることで、入力データにどのような摂動を加えていけば誤分類を引き起こせるのか分かる。
以下にL-BFGSで作成された敵対的サンプルを例示する。

この例では、オリジナル画像(左列)に摂動(真ん中)を加えて敵対的サンプル(右列)を作成している。
人間の目に敵対的サンプルはトラックや犬、カマキリなどに見えるが、これを標的AIに入力すると、全てダチョウとして誤分類される。
FGSMは、(誤分類を引き起こす)摂動を得るための反復処理を排除したシングルステップ(Single Step)のアプローチであり、敵対的サンプルの作成効率を飛躍的に向上させたものである。一方、JSMAは反復(Iterative)を前提としたアプローチであり、FGSMと比較して作成効率は劣るものの、(より人間に検知され難い)細かい摂動を作成することができる。
なお、敵対的サンプルはデジタル表現は勿論のこと、物理ドメインにおいても作成することは可能である。
以下は3Dプリンターで作成した(特殊柄の甲羅を持つ)亀オブジェクトを、ライフルとして誤分類させる敵対的サンプルを示している。

ところで、上述した敵対的サンプルの作成アルゴリズムは勾配ベースであるため、攻撃者の前提知識がグレーボックスまたはホワイトボックスでないと敵対的サンプルは作成できないと思われるかもしれない。しかし、シャドウモデルを使用することで、ブラックボックスな状態でも敵対的サンプルを作成することは可能である。以下は、ブラックボックスで敵対的サンプルを作成する例を示している。
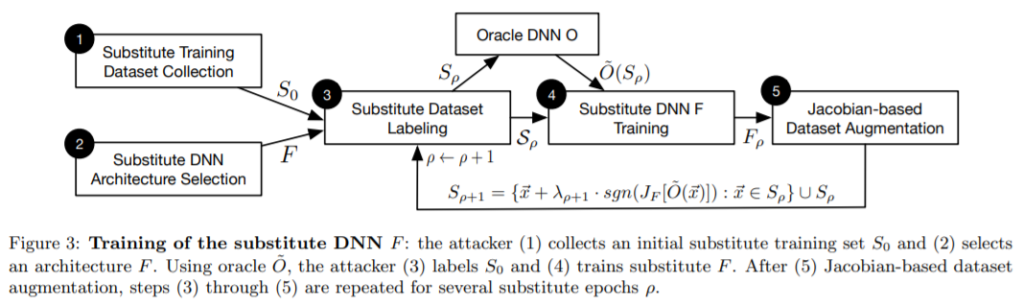
以下に作成手順を簡単に示す。
- シャドウモデル用のデータセット「S0」を収集する。
シャドウモデルのデータセットは標的AIのデータセットと完全に一致させる必要はなく、標的AIの分類目的に合っていれば良い。
例えば、標的AIが道路標識を識別するのであれば、道路標識の画像を集める。 - シャドウモデル「F」を作成する。
シャドウモデル「F」と標的AI「O」は入力と出力の形が同じであれば、アーキテクチャを一致させる必要はない。
例えば、MNISTのような情報量の少ない画像を対象にするならば2層のCNN、もう少し情報量の多い画像ならばResNetなど。 - シャドウモデル「F」を学習する。
以下のプロセスを反復する。- データセット「S0」を標的AI「O」に入力し、分類クラスを得る。
得られたクラスをデータセット「S0」のラベルとする。 - ラベルが付いた「S0」を用いてシャドウモデル「F」を学習する。
- Jacobian-based Dataset Augmentationなどを使用してデータセット「S0」を水増しする。
- 水増ししたデータセット「S0」を用いて1に戻る。
- データセット「S0」を標的AI「O」に入力し、分類クラスを得る。
- 学習済みのシャドウモデル「F」を用いて敵対的サンプルを作成する。
以上の手順により、シャドウモデルを使用することでブラックボックスな状態でも敵対的サンプルを作成することができる。
なお、上述した敵対的サンプルの転移性により、シャドウモデルと標的AIの学習データ分布やアーキテクチャが異なっている場合でも、作成した敵対的サンプルを用いて標的AIに回避攻撃を行うことは可能である。
以上で回避攻撃の解説は終わるが、本節の最後に敵対的サンプルを作成するツールを幾つか紹介する。
上記のツールにはL-BFGSやFGSMなどは勿論のこと、数多くの敵対的サンプルを作成するアルゴリズムが実装されており、様々な種類の敵対的サンプルを用いた回避攻撃の耐性テストを行うことができる。また、TensorFlowやKeras、PyTorchなど、主要な機械学習プラットフォームで作成されたAIにも対応しているため、ご興味を持たれた方は試されることを推奨する。
オラクル(Oracle)
Oracleは標的AIから情報を収集・窃取することを目的としており、手法や目的の違いにより、抽出(Extraction)、反転(Inversion)、そしてメンバーシップ推論(Membership Inference)に分類される。
- オラクル(Oracle)
- 抽出(Extraction)
- 反転(Inversion)
- メンバーシップ推論(Membership Inference)
抽出は、標的AIへのクエリアクセスにより得られた情報を基に、標的AIの決定境界を復元する行為である。
AIはクエリアクセスに対して分類クラスや信頼スコアを応答する場合がある。この時、攻撃者は複数回のクエリアクセスで得られた入出力情報(入力データや信頼スコア)を収集して分析することで、標的AIの決定境界を復元することができる。以下は、標的AIに複数回のクエリアクセスを行い、その際に得られた出力値を手掛かりに標的AIの決定境界を復元(抽出)する例を示している。
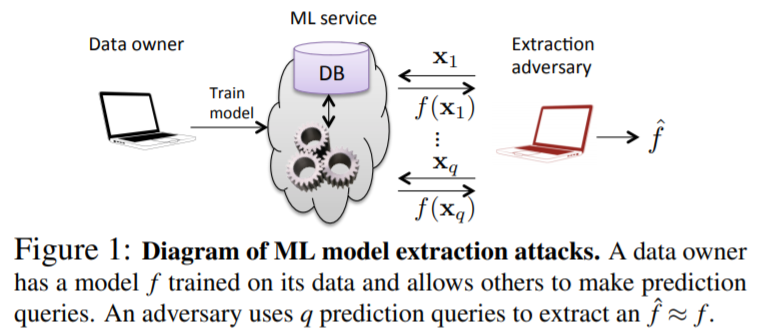
反転は、標的AIが学習したデータを再構築する行為である。
上述したように、AIの学習では(学習データから取り出した)入力データを固定し、入力データに対するAIの出力値とラベル(答え)の差分を基に勾配降下法で重みを更新する処理を何度も反復する。反転攻撃ではこの仕組みを悪用するために、攻撃者はランダムノイズで生成されたデータをAIに入力する。この時、重みは固定し、入力データを更新する(学習とは逆)。これを何度も繰り返すと、ランダムノイズに紐づく可能性が最も高いクラスの特徴がデータに表れていき、最終的に標的AIの学習データが再構築される。以下は、CIFAR10を学習したAIの学習データを反転攻撃で再構築した例を示している。

メンバーシップ推論は、標的AIが応答する信頼スコアを利用し、特定の入力データが標的AIの学習データに属しているかを推論する行為である。
AIの学習において特定のデータを過剰に学習した場合、過学習が引き起こされる。過学習は分類精度の低下を引き起こすことが知られているが、メンバーシップ推論攻撃に対しても脆弱になる。過学習したAIに学習データに含まれるデータを入力すると、該当するクラスに過剰に反応した結果が応答される(例:[0.97, 0.01, 0.01, 0.01])。一方、学習データに含まれていないデータを入力すると、分類確率が平準化された結果が応答される(例:[0.58, 0.31, 0.07, 0.04])。このように、学習データに含まれている、または、含まれていないデータに対する挙動の違いを観察することで、攻撃者は標的AIの学習データを推論することが可能となる。

2.2. 防御(Defenses)
防御(Defenses)の視点では、上述した攻撃に対するあらゆる防御手法を定義している。
NISTIR8269では防御の視点を学習工程とテスト工程の2つに分類している。
- 防御(Defenses)
- 学習工程における防御(Defenses Against Training Attacks)
- テスト工程における防御(Defenses Against Testing (Inference) Attacks)
2.2.1. 学習工程における防御(Defenses Against Training Attacks)
学習工程における防御(Defenses Against Training Attacks)では、探索行為(Data Access)と汚染(Poisoning)に対して以下3つの防御手法を定義している。
- 学習工程における防御(Defenses Against Training Attacks)
- データ暗号化(Data Encryption)
- データ無害化(Data Sanitization (Reject on Negative Impact))
- ロバスト統計(Robust Statistics)
データ暗号化(Data Encryption)
探索行為(Data Access)に対しては、データ暗号化(Data Encryption)が有効である。
探索行為は攻撃者が標的AIの学習データやパラメータにアクセスして情報収集する行為であるが、データを暗号化することでこれを防ぐ。なお、近年データを暗号化したままAIの学習を行うことが可能な技術も登場している[37]。
データ無害化(Data Sanitization)とロバスト統計(Robust Statistics)
汚染(Poisoning)に対しては、データ無害化(Data Sanitization)とロバスト統計(Robust Statistics)が有効である。
データ無害化では、学習データに注入された細工データ(敵対的サンプル)がAIの推論性能に与える影響を評価することで細工データを検知する。推論で高いエラー率を示すデータは細工データである可能性が高いため、これをデータセットから除外する。一方、ロバスト統計では、細工データを検知するのではなく、制約と正則化技術を使用し、細工データ(敵対的サンプル)によって引き起こされる決定境界の歪みを軽減する。
NISTIR8269で紹介されている防御手法以外にも、以下の対策も有効であると考えられる。
- 信頼できる提供元から学習データや事前学習モデルを入手する。
インターネットなどの信頼できないドメインから入手したデータは細工されていると考えるべきである。
学習データ全体における細工データの割合が1%程度であっても、バックドアを設置できる攻撃手法は存在する[1]。よって、学習データや事前学習モデルは信頼できる提供元から入手するようにする。 - STRong Intentional Perturbation(STRIP)を使用する。
STRIP[2]と呼ばれる技術を使用することで、バックドアを活性化するトリガーを検知することが可能である。
しかし、STRIPによる検知を回避する手法の研究が進んでいるため、本手法は陳腐化する可能性があることに注意されたい。
2.2.2. テスト工程における防御(Defenses Against Testing (Inference) Attacks)
テスト工程における防御(Defenses Against Testing (Inference) Attacks)では、回避(Evasion)とオラクル(Oracle)に対して以下3つの防御手法を定義している。
- テスト工程における防御(Defenses Against Testing (Inference) Attacks)
- 頑健性の向上(Robustness Improvements)
- 敵対的学習(Adversarial Training)
- 勾配マスキング(Gradient Masking)
- 防御のための蒸留(Defensive Distillation)
- アンサンブル・メソッド(Ensemble Method)
- 特徴量の絞り込み(Feature Squeezing)
- Reformers/Autoencoders
- 差分プライバシー(Differential Privacy)
- 同相暗号化(Homomorphic Encryption)
- 頑健性の向上(Robustness Improvements)
頑健性の向上(Robustness Improvements)
回避(Evasion)に対しては、AIの頑健性向上(Robustness Improvements)が有効である。
頑健性を向上させる方法として、敵対的学習(Adversarial Training)、勾配マスキング(Gradient Masking)、防御のための蒸留(Defensive Distillation)、アンサンブル・メソッド(Ensemble Method)、特徴量の絞り込み(Feature Squeezing)、そして、Reformers/Autoencodersが挙げられる。これらの手法は、テスト工程における攻撃に対する防御手法であるが、防御の実施自体は学習工程で行われる。
敵対的学習は、正しいラベルと紐づけた敵対的サンプルを学習データに加えて学習を行う防御手法である。敵対的サンプル自体を学習することで、敵対的サンプルが標的AIに入力された場合でも、(誤分類せずに)正しいクラスに分類する効果が期待できる。ただし、敵対的学習を施したAIを騙す敵対的サンプルが作成されることも考えられるため、本防御手法は単純な敵対的サンプルでしか効果を発揮しない可能性もある。
勾配マスキングは、学習時に入力データに対する微分値を最小化(難読化)することで、敵対的サンプルの効果を低減させる防御手法である。同様の考え方は、学習済みAIの入力と出力をよりシンプルなアーキテクチャを持ったAIに学習させる防御のための蒸留や、複数の(アーキテクチャの異なる)AIを一緒に学習し、組み合わせることで頑健性を向上させるアンサンブル・メソッドにも取り入れられている。ただし、勾配マスキングを回避する手法[42]も研究されているため、本防御手法は陳腐化する可能性もあることに注意が必要である。
特徴量の絞り込みは、入力データ(主に画像)のカラービット深度を減らしたり、(画像処理における)空間フィルタを利用して入力画像の平滑化を行うことで、攻撃者が利用可能な摂動の探索空間を削減する防御手法である。以下は、特徴量の絞り込みによって平滑化された画像の一例を示している。
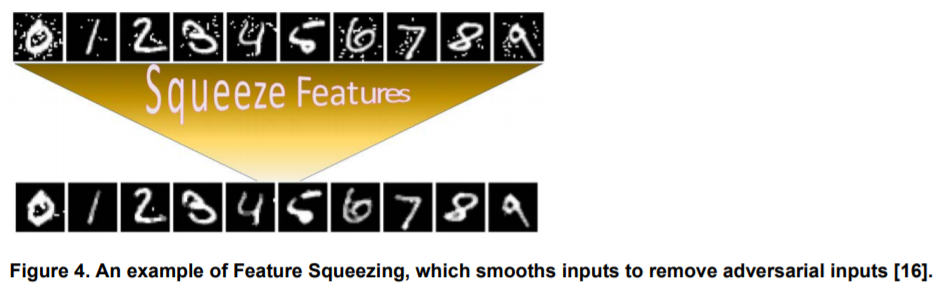
上図の上段は敵対的サンプル、下段は特徴量の絞り込みによって平滑化された画像である。
平滑化された入力画像と平滑化前の入力画像をそれぞれAIに推論させ、その結果の差異が閾値を超えた場合、当該入力画像を敵対的サンプルと判断して除外する。

Reformers/Autoencoderは、オートエンコーダを敵対的サンプルの検知器として使用する防御手法である。
本手法では、事前に(防御するAIの)学習データセットを使用してオートエンコーダ/デコーダを学習しておく。そして、AIに入力データが与えられた場合、当該データを学習済みのオートエンコーダ/デコーダに入力し、正常データのManifold(下図の黒い曲線)との再構成誤差を求める。この再構成誤差が大きい場合、当該データを敵対的サンプルと見なして除外する。
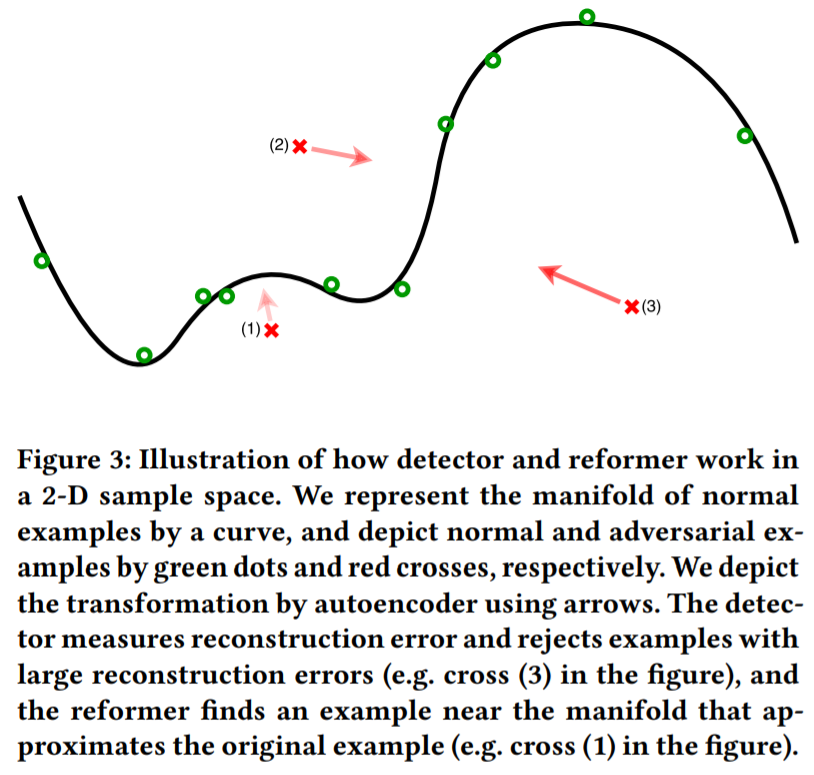
なお、正常と異常の閾値によって検知精度が変わるため、適切な閾値を設定する必要があることに注意が必要である。
差分プライバシー(Differential Privacy)と同相暗号化(Homomorphic Encryption)
個人情報などのセンシティブなデータを学習したAIに対して反転(Inversion)やメンバーシップ推論(Membership inference)が行われた場合、情報漏えいと共に重大なプライバシー侵害が引き起こされる。そこで、差分プライバシー(Defferential Privacy)や同相暗号化(Homomorphic Encryption)と呼ばれる技術を用いてデータを保護する。
差分プライバシー(Defferential Privacy)は、AIの学習データに含まれる機密情報が漏えいしないようにする防御の考え方である。これを実現する方法は複数存在するが、ここではAIの学習工程で実施される差分プライバシーの代表的な手法であるDPSGD(Differentially Private Stochastic Gradient Descent)を紹介する。

通常のSGDでは、現在のパラメータ(重み)に対する損失関数の勾配を計算し、現在のパラメータ値から学習率を乗じた勾配を差し引くことで、パラメータ値を更新する(これを、損失関数の最適値に到達するまで繰り返す)。一方、DPSGDでは、パラメータを更新する前に、勾配を一定のノルムでクリッピングする。これは、AIが学習データ内のデータセットを過学習しないようにするための措置である。その上で、差分プライバシーを確保するために、(ガウシアンノイズなどの)ノイズをクリッピングした勾配に追加し、これを基にパラメータの更新を行う。この仕組みにより、学習データ内の隣接するデータセットに対するAIの出力に大きな差が出ないことを保証し、メンバーシップ推論攻撃に対して頑健になる。
しかし、DPSGDを施したAIは推論精度が低下する場合があるため、プライバシーの確保と推論性能にはトレードオフの関係があることに注意が必要である。これに対する代替アプローチとして、同相暗号化(Homomorphic Encryption)がある。これは、データを暗号化したまま学習することで学習データに含まれる機微情報を保護する技術であり、推論精度を落とさずにプライバシーを保護することができる。しかし、その反面、計算コストが増加することに注意が必要である。
2.3. 影響(Consequences)
影響(Consequences)の視点では、AIへの攻撃によってもたらされる影響を定義している。
NISTIR8269では影響の視点を完全性、可用性、そして機密性の3つに分類している。
- 影響(Consequences)
- 完全性の侵害(Integrity Violation)
- 可用性の侵害(Availability Violation)
- 機密性の侵害(Confidentiality Violation)
完全性の侵害(Integrity Violation)は、攻撃によってAIの推論処理が損なわれ、AIの信頼性の低下や誤分類が誘発される事象を指している。
具体的には、敵対的サンプルを用いた回避攻撃によって、AIへの入力データを攻撃者が意図したクラスに誤分類させられることなどである。なお、NISTIR8269では教師あり学習モデルについて大きく取り上げているが、教師なし学習モデルにおける完全性の侵害では、対象データを意味のないクラスタに分割することなどが考えられる。また、強化学習モデルにおける完全性の侵害では、エージェントが環境内で意味のない行動を学習したり、性能が低下したりすることなどが考えられる。
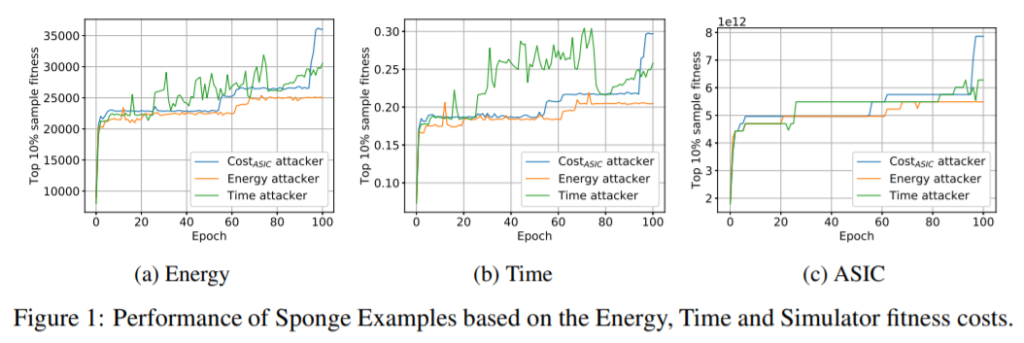
可用性の侵害(Availability Violation)は、AIの推論速度の低下やアクセシビリティの低下(サービス拒否)が引き起こされ、利用者がAIを利用できなくなる事象を指している。
可用性の侵害においても、完全性の侵害で述べたような信頼性の低下や誤分類を伴う場合があるが、AIを利用できないような処理速度低下やサービス拒否などが引き起こされる点で異なる。以下は、AIへの入力データを細工し、AIの推論時間やエネルギー消費の増大を図る攻撃の例を示している。本論文では、エネルギー消費が10倍から最大200倍に増加するケースを確認したとのことであり、自動走行車のように推論遅延が許容されないケースでは、深刻な問題になる可能性がある。
機密性の侵害(Confidentiality Violation)は、攻撃者がAIの決定境界や学習データに関する情報を窃取・推論することで、機密情報漏えいやプライバシー侵害が引き起こされる事象を指している。
具体的には、AIの決定境界やパラメータを窃取する抽出や、(シャドウモデルを作成するための)Oracleに関する攻撃などである。また、学習データに含まれる機密情報を窃取する反転やメンバーシップ推論も機密性の侵害に含まれる。
3. おわりに
本ブログでは、米国のNISTが作成した「Draft NISTIR 8269: A Taxonomy and Terminology of Adversarial Machine Learning」を解説した。
冒頭でも記述したように、NISTIR8269は網羅性を保証するものではないが、主要な攻撃手法と防御手法が定義されており、AIの安全確保には一定の貢献をするものと考えている。なお、NISTIR8269にも記述されているように、本ドラフトは加筆修正を繰り返しながらNISTのSP800シリーズに反映される可能性があり、今後、機械学習セキュリティのベストプラクティスになる可能性もある。筆者らは今後もNISTの機械学習セキュリティに関する取り組みをウォッチし、有用な情報があれば本ブログで紹介していく予定である。
なお、NISTIR8269は機械学習セキュリティの体系化に焦点を当てているため、各攻撃手法・防御手法の深堀は行っていないが、本ブログでは可能な限り各手法に関連する論文やブログを引用した。もし、各手法の詳細を知りたい方は「参考文献」記載の論文・ブログを参照していただけると幸いである。
参考文献
- セキュアAI研究所, “Transferable Clean-Label Poisoning Attacks on Deep Neural Nets“
- Yansong Gao, Chang Xu, Derui Wang, Shiping Chen, Damith C.Ranasinghe, Surya Nepal, “STRIP: A Defence Against Trojan Attacks on Deep Neural Networks,” arXiv:1902.06531
- セキュアAI研究所, “Adversarial Attacks and Defense on Texts: A Survey character-level編“
- Vincent Ballet, Xavier Renard, Jonathan Aigrain, Thibault Laugel, Pascal Frossard, Marcin Detyniecki, “Imperceptible Adversarial Attacks on Tabular Data ,” arXiv:1911.03274
- L. Huang, A. D. Joseph, B. Nelson, B. I. P. Rubinstein and J. D. Tygar, “Adversarial Machine Learning,” Proceedings of the 4th ACM Workshop on Security and Artificial Intelligence, New York, NY, USA, 2011.
- N. Akhtar and A. Mian, “Threat of adversarial attacks on deep learning in computer vision: A survey,” IEEE Access, vol. 6, pp. 14410-14430, 2018.
- B. Biggio and F. Roli, “Wild patterns: Ten years after the rise of adversarial machine learning,” Pattern Recognition, vol. 84, pp. 317-331, 2018.
- A. Chakraborty, M. Alam, V. Dey, A. Chattopadhyay and D. Mukhopadhyay, “Adversarial Attacks and Defences: A Survey,” 28 9 2018.
- Q. Liu, P. Li, W. Zhao, W. Cai, S. Yu and V. C. M. Leung, “A survey on security threats and defensive techniques of machine learning: A data driven view,” IEEE access, vol. 6, pp. 12103-12117, 2018.
- N. Papernot, P. McDaniel, A. Sinha and M. P. Wellman, “SoK: Security and privacy in machine learning,” 2018 IEEE European Symposium on Security and Privacy (EuroS&P), 2018.
- P. Kuznetsov, R. Edmunds, T. Xiao, H. Iqbal, R. Puri, N. Golmant and S. Shih, “Adversarial Machine Learning,” Artificial Intelligence Safety and Security, Chapman and Hall/CRC, 2018, pp. 235-248.
- I. Goodfellow, P. McDaniel and N. Papernot, “Making machine learning robust against adversarial inputs,” Communications of the ACM, vol. 61, pp. 56-66, 2018.
- X. Yuan, P. He, Q. Zhu and X. Li, “Adversarial examples: Attacks and defenses for deep learning,” IEEE transactions on neural networks and learning systems, 2019.
- N. Papernot, P. McDaniel, I. Goodfellow, S. Jha, Z. B. Celik and A. Swami, “Practical black-box attacks against machine learning,” Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, 2017.
- N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z. B. Celik and A. Swami, “The limitations of deep learning in adversarial settings,” Security and Privacy (EuroS&P), 2016 IEEE European Symposium on, 2016.
- M. Barreno, B. Nelson, A. D. Joseph and J. D. Tygar, “The security of machine learning,” Machine Learning, vol. 81, pp. 121-148, 2010.
- M. Barreno, B. Nelson, R. Sears, A. D. Joseph and J. D. Tygar, “Can machine learning be secure?,” Proceedings of the 2006 ACM Symposium on Information, computer and communications security, 2006.
- Simen Thys, Wiebe Van Ranst, Toon Goedemé, “Fooling automated surveillance cameras: adversarial patches to attack person detection,” arXiv:1904.08653
- Steve Povolny, Shivangee Trivedi, “Model Hacking ADAS to Pave Safer Roads for Autonomous Vehicles,” https://www.mcafee.com/blogs/other-blogs/mcafee-labs/model-hacking-adas-to-pave-safer-roads-for-autonomous-vehicles/
- Juncheng B. Li, Shuhui Qu, Xinjian Li, Joseph Szurley, J. Zico Kolter, Florian Metze, “Adversarial Music: Real World Audio Adversary Against Wake-word Detection System,” arXiv:1911.00126
- “Attacking Machine Learning with Adversarial Examples,” https://openai.com/blog/adversarial-example-research/
- Suranjana Samanta, Sameep Mehta, “Towards Crafting Text Adversarial Samples,” arXiv:1707.02812
- Amin Rakhsha, Goran Radanovic, Rati Devidze, Xiaojin Zhu, Adish Singla, “Policy Teaching via Environment Poisoning: Training-time Adversarial Attacks against Reinforcement Learning,” arXiv:2003.12909
- Xuezhou Zhang, Yuzhe Ma, Adish Singla, Xiaojin Zhu, “Adaptive Reward-Poisoning Attacks against Reinforcement Learning,” arXiv:2003.12613
- Fang Liu, Ness Shroff, “Data Poisoning Attacks on Stochastic Bandits,” arXiv:1905.06494
- Yuzhe Ma, Kwang-Sung Jun, Lihong Li, Xiaojin Zhu, “Data Poisoning Attacks in Contextual Bandits,” arXiv:1808.05760
- Tong Chen, Wenjia Niu, Yingxiao Xiang, Xiaoxuan Bai, Jiqiang Liu, Zhen Han, Gang Li, “Gradient Band-based Adversarial Training for Generalized Attack Immunity of A3C Path Finding,” arXiv:1807.06752
- Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, Rob Fergus, “Intriguing properties of neural networks,” arXiv:1312.6199
- Ruixiang Tang, Mengnan Du, Ninghao Liu, Fan Yang, Xia Hu, “An Embarrassingly Simple Approach for Trojan Attack in Deep Neural Networks,” arXiv:2006.08131
- セキュアAI研究所, “MNISTの手書き数字を分類したらシステムが乗っ取られる話“
- Robby Costales, Chengzhi Mao, Raphael Norwitz, Bryan Kim, Junfeng Yang, “Live Trojan Attacks on Deep Neural Networks,” arXiv:2004.11370
- Eugene Bagdasaryan, Vitaly Shmatikov, “Blind Backdoors in Deep Learning Models,” arXiv:2005.03823
- Anish Athalye, Logan Engstrom, Andrew Ilyas, Kevin Kwok, “Synthesizing Robust Adversarial Examples,” arXiv:1707.07397
- Florian Tramèr, Fan Zhang, Ari Juels, Michael K. Reiter, Thomas Ristenpart, “Stealing Machine Learning Models via Prediction APIs,” arXiv:1609.02943
- Felipe A. Mejia, Paul Gamble, Zigfried Hampel-Arias, Michael Lomnitz, Nina Lopatina, Lucas Tindall, Maria Alejandra Barrios, “Robust or Private? Adversarial Training Makes Models More Vulnerable to Privacy Attacks,” arXiv:1906.06449
- セキュアAI研究所, “Membership Inference Attacks On Neural Networks“
- 日本電信電話株式会社, “ニュースリリース:暗号化したままディープラーニングの標準的な学習処理ができる秘密計算技術を世界で初めて実現
- Hannah Chen, Mainuddin Ahmad Jonas, Fnu Suya, Xiao Zhang, David Evans, Yanjun Qi, Yuan Tian, “Is Robust Machine Learning Possible?“
- Dongyu Meng, Hao Chen, “MagNet: a Two-Pronged Defense against Adversarial Examples,” arXiv:1705.09064
- Md Atiqur Rahman, Tanzila Rahman, Robert Lagani`ere, Noman Mohammed, Yang Wang, “Membership Inference Attack against Differentially Private Deep Learning Model,” Transactions on Data Privacy 11:1 (2018) 61 – 79
- Ilia Shumailov, Yiren Zhao, Daniel Bates, Nicolas Papernot, Robert Mullins, Ross Anderson, “Sponge Examples: Energy-Latency Attacks on Neural Networks,” arXiv:2006.03463
- Anish Athalye, Nicholas Carlini, David Wagner, “Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples,” arXiv:1802.00420