
概要
NLPのadversarial attack, defenseのサーベイ論文。 画像や音声など入力に微弱なノイズを加えるわけではなく、文字や単語、文単位での入れ替えなど、実際の文章に対して変換を加えるものに限定している。
前回の記事では文字レベルの敵対的攻撃手法を紹介をした。 基本的な背景などは前回の記事に書いてある。 今回は単語レベルの敵対的攻撃手法を紹介していく。
論文情報
公開日
2020-5-28
著者情報
Aminul Huq, Mst. Tasnim Pervin
Dept. of Computer Science & Technology, Tsinghua University
論文情報・リンク
Adversarial attack for NLP
このサーベイ論文ではテキストデータに対する敵対的攻撃を文字単位、単語単位、文単位、またこれらを組み合わせる手法の4種類のカテゴリに分けている。 それぞれカテゴリごとに攻撃手法を紹介していく。今回は単語単位の手法に着目し、説明していく。
Word level attack
文字通り単語に対して行われる敵対的な攻撃。 主に同義語や反義語に変換されたり、単語そのものを認識されなくしたり削除するような処理が行われる。 今回紹介する手法は全て文書分類に対する手法である。
Crafting Adversarial Input Sequences for Recurrent Neural Networks [arxiv abs]
RNNベースの分類手法に対して、white-boxの敵対的攻撃手法を提案した。 勾配情報を用いて予測を任意のクラスに変える事ができる。 各単語の勾配情報を確認し、単語空間上で勾配の方向にある単語に置換する。これを予測クラスが変わるまで繰り返す。 IMDBのデータセットに対して平均9単語変換することで、全ての予測を変更することが出来た。 しかしこの手法では置換先の単語をランダムに選ぶため、文法が壊滅したり文章が意味を持たないこともある。
Towards Crafting Text Adversarial Samples [arxiv abs]
より少ない文章が誤分類されるような修正を加える、white-boxの敵対的攻撃手法を提案した。 この修正とは分類に寄与している単語や文章を特徴づけるような単語に対して、消去や置換、新しい単語の挿入の3つの処理を行う。 この手法の動作は以下のようになる。

単語の寄与度は各単語がない状態でのクラスの変化量から求める。(変化量が大きいほど寄与率が高い) 候補単語は各単語の同義語や意味のあるタイプミス(good → god)、各サブカテゴリ固有を含む単語集合から最も現在のクラスへの寄与度の低いものを選択していく。
最初に各単語の分類に対する寄与度を計算してソートする。 その後各単語に対して、以下の処理を出力クラスが変わるまで行う。
- 対象単語の寄与率が高く、副詞(adverb)だった場合
- その単語を消去
- 対象単語が形容詞(adjective)かつ候補単語が副詞の場合
- 候補単語を挿入
- 品詞が同じだった場合
- 候補単語に置換
- いずれでもない場合
- 候補単語を変更してもう1度
以下の表は生成したadversarial exsampleを示す。
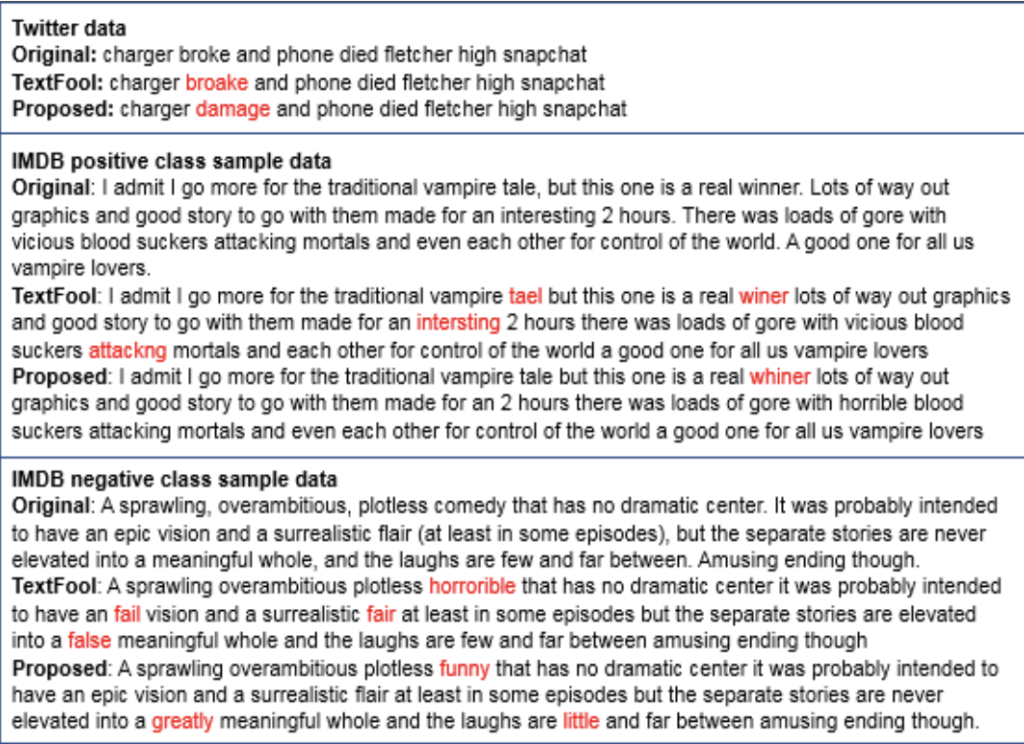
表中のTextFoolは先行研究である。二段目を見ると先行研究の手法よりも少ない変換でadevrsarial exsampleを生成出来ている。
評価にはIMDBデータセット(映画のレビュー)とtwitterの感情分析データセットを用いた。
Deep Text Classification Can be Fooled [arxiv abs]
挿入、消去、修正に基づく、white-boxとblack-boxの敵対的攻撃手法を提案した。 分類に寄与する単語やフレーズを検出する際にHTP(Hot training phrase)とHSP(Hot sample phrase)という概念も提案した。 HTPとHSPは、それぞれwhite-boxなモデルに対して作成される。 HTPはadversarial exsample生成の際に挿入する単語の候補で、HSPはHTPの単語を挿入したり、削除、置換する際に有効な単語の位置の候補である。 HSPの作成手順は以下のようになっている。
- 各サンプルごとに分類モデルの勾配情報から分類に寄与する単語を特定し、その単語をホットワードと呼ぶ。
- また隣接している単語がホットワードだった場合はそのフレーズを、隣接している単語にホットワードがない場合はその単語を集めてホットフレーズを作る。
- 各ラベルごとに最も頻度の高いホットフレーズを集め、HTPを作成する。 HSPはホットフレーズの集合である。
以下にbuildingクラスのHTPを示す。

buildingやhouseなどの特徴語がよく現れている。
black-boxでは単語を一個ずつ削除してモデルに入力し、出力の変化を確認して最大の偏差を持つ入力をHSPとする。HTPはwhite-boxと同様に各サンプルごとの頻度の高いホットフレーズの集合である。 以下にwhite-boxとblack-boxのHSPの上位TOP10を表に示す。
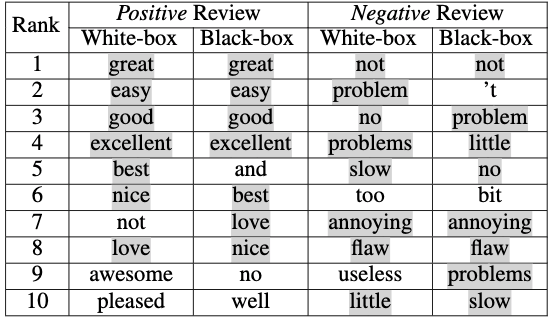
White-boxとblack-boxの両方に含まれる単語は色付けされており、black-boxでもwhite-boxと同等の重要語の特定が出来ている事がわかる。
Adversarial Examples for Natural Language Classification Problems [openreview]
White-boxの敵対的攻撃手法を提案した。 NLPのadversarial exampleはいくつか論文があるものの、良いadversarial exapmleの定義やそれを図る評価手法は存在していない。 また画像や音声と違い、離散空間で単純な勾配ベースの手法が適応できないなど問題点が存在する。 この論文ではNLPでの良いadversarial exampleとは意味の変化がなく、文法的にも間違いがないものと定義した。 これらを定量的に測る指標として、文章の意味の変化を評価するために「ノイズを加える前と後の文章ベクトルの距離」を、文法の変化を評価するために「言語モデルの出力の差」を用いた。
モデルの予測を間違えさせることができ、かつこの二つの値がそれぞれ閾値以下となるadversarial exampleを生成する。 生成のアルゴリズムは以下のようになる。

もととなる文章をから単語をとりだし、glove vectorの近傍N単語を取得する。その中から文法評価値が閾値以上のものを消し、それの中で最も予測が外れるような単語に置換する。この処理を予測値が設定した閾値を超えるまで行う。 明示的に文章ベクトルの制約は加えていないが単語ベクトル空間上で近いものとなっているため、文章ベクトルは近くなっている。
Generating Natural Language Adversarial Examples [arxiv abs]
遺伝的アルゴリズムを使用したblack-boxの敵対的攻撃手法を提案した。 意味的にも構文的にも元の文章と類似したadversarial exampleの生成を目指す。 最初にランダムに文章を選択し、文章中の各単語の置換単語候補を準備する。置換単語候補はglove vectorのユークリッド距離がある閾値以下であり、googleの10憶個の単語からなる言語モデルを使用しコンテキストに問題のないものを候補とする。その候補の中から最も予測を間違えるような単語を選択する。 この際、候補の多いものから置換する単語を選び、前置詞や助詞などは置換されないようにする。 置換する単語が少なくなるように遺伝的アルゴリズムで学習を行う。
以下に生成したadversarial exampleを示す。

例文でわかる通り文章の意味を大きく変えずにnegativeだった文章の予測をpositiveに変えることができている。
生成したadversarial exampleに対して分類器は誤った予測をしつつ、アノテーターが元のラベルと判断するようなものもあった。
Natural Language Adversarial Attacks and Defenses in Word Level [arxiv abs]
この論文では上記の攻撃手法を改良し、遺伝的アルゴリズム最適化の途中で同じ単語に対して複数回置換可能にすることで、多様性を増すことに成功した。
Word-level Textual Adversarial Attacking as Combinatorial Optimization [arxiv abs]
上記の攻撃手法をさらに改良し、候補の検索を単語ベクトルベースからsememe(意義素)ベースに、最適化手法を遺伝的アルゴリズムから粒子群最適化に変更した。 sememeとは人間の言語の最小単位で、「男」 = 「人間、オス、成体」のような単語の構成要素を指す。 従来の単語ベクトルベースでは多くの置換単語を見つけることができるが、その中には反意語や意味的に関連はするが類似していない単語を含むことが多い。これに対し、sememeベースやsynonym(同義語)ベースの手法はこれらの問題を含むことがない。またsynonymベースでは単語の候補が少なくなってしまうため、sememeベースを用いる。その際文法のミスを起こさないため、置換候補には置換先と同じ品詞タグのものに限定する。
議論
今回は言語処理タスクにおける単語レベルの敵対的攻撃手法にについて紹介した。 単語レベルの処理は基本的に文章の構成(意味的、構文的)を保ったadversarial exampleの生成を目指している。 そのため単語ベクトルや意義素などを用いた意味的に近い単語候補の検索などが多く見られた。 また構文的な構成を保つために、言語モデルや品詞など自然言語の情報を用いた。
実際に論文中では人間が見分けをつけることの出来ないadversarial exampleも生成できている。 これらのことから、より汎化性能の高いモデルを作ることが課題となってくる。
次回は文章レベルの敵対的攻撃手法を紹介していく。