新着記事
更新日: 2021-06-01

バックドアを深層学習モデルへ仕掛けるOSS『TrojAI』解説
本記事では米国ジョンズ・ホプキンズ大学のApplied Physics Laboratory (APL) が公開した深層学習モデルへバックドアを仕掛けるOSS TrojAIについて紹介します。本OSSの開発を目的としたプ...
更新日: 2021-03-25
第8話 〜 セキュアなAIを開発するには? – 国内外のガイドライン – 〜
本コラムは第8回「セキュアなAIを開発するには? – 国内外のガイドライン –」です。 第1回から第7回までは、AIを取り巻くセキュリティの環境や、AIに対する具体的な攻撃手法を紹介してきました。AIを攻撃から守るため...
更新日: 2021-02-24

顔認識システムに対する敵対的攻撃の脅威調査
本記事の要点 顔認識システムに対する敵対的攻撃手法及び防御手法の網羅的なサーベイを行った。 手法の特性に基づき深層学習モデルを誤識別させる攻擊手法は4種類に大別し、対応する防御手法は3種類に分類した。 標的モデルの精度へ...
更新日: 2021-02-16

第7話 〜 AIの身辺調査 – AIに対するOSINT – 〜
本コラムは第7回「AIの身辺調査 - AIに対するOSINT -」です。 本コラムでは、攻撃者が攻撃対象のAI(以下、標的AI)を効率的に攻撃するために、合法的に入手可能な情報を基に、標的AIに関する内部情報(データセ...
更新日: 2020-12-14

Argot: Generating Adversarial Readable Chinese Tex...
概要 自然言語処理における中国語と英語のAdversarial Exampleの違いについて分析し、中国語に対するblack-boxの攻撃手法の「Argot」を提案。Argotは中国語の特徴に基づき、効率的かつ人間にも読...
更新日: 2020-12-10

第6話 〜AIシステムへの侵入 – 機械学習フレームワークの悪用 -〜
本連載は「AI*セキュリティ超入門」と題し、AIセキュリティに関する話題を幅広く・分かり易く取り上げていきます。本連載を読むことで、AIセキュリティの全体像が俯瞰できるようになるでしょう。 *本コラムにおける【AI】の定...
更新日: 2020-11-04

第7回:信頼スコアのフィルタリング -メンバーシップ推論の対策-
Adversarial Robustness Toolbox(ART)は、AI*1セキュリティのためのPythonライブラリです。ARTを使用することで、AIに対する攻撃手法(敵対的サンプル攻撃、データ汚染攻撃、モデル抽...
更新日: 2020-10-28

第6回:メンバーシップ推論 -抽出攻撃-
Adversarial Robustness Toolbox(ART)は、AI*1セキュリティのためのPythonライブラリです。ARTを使用することで、AIに対する攻撃手法(敵対的サンプル攻撃、データ汚染攻撃、モデル抽...
更新日: 2020-10-19

第5話 ~ AIの推論ロジックを改ざんする攻撃 – ノード注入 – ~
本連載は「AI*1セキュリティ超入門」と題し、AIセキュリティに関する話題を幅広く・分かり易く取り上げていきます。本連載を読むことで、AIセキュリティの全体像が俯瞰できるようになるでしょう。 *1:本コラムにおける【AI...
更新日: 2020-10-18
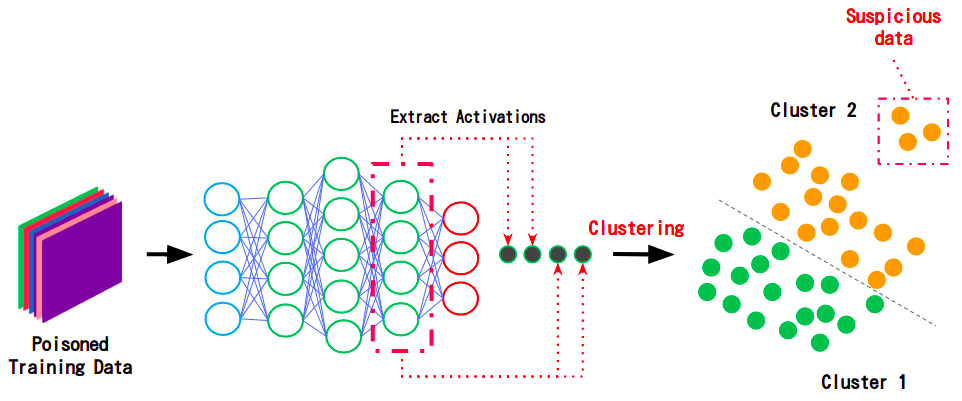
第5回:Activation Clustering -学習データ汚染攻撃の対策-
Adversarial Robustness Toolbox(ART)は、AI*1セキュリティのためのPythonライブラリです。ARTを使用することで、AIに対する攻撃手法(敵対的サンプル攻撃、データ汚染攻撃、モデル抽...
更新日: 2020-10-12

第4回 ~ AIのプライバシー侵害 – メンバーシップ推論 – ~
本連載は「AI*1セキュリティ超入門」と題し、AIセキュリティに関する話題を幅広く・分かり易く取り上げていきます。本連載を読むことで、AIセキュリティの全体像が俯瞰できるようになるでしょう。 *1:本コラムにおける【AI...
更新日: 2020-10-07
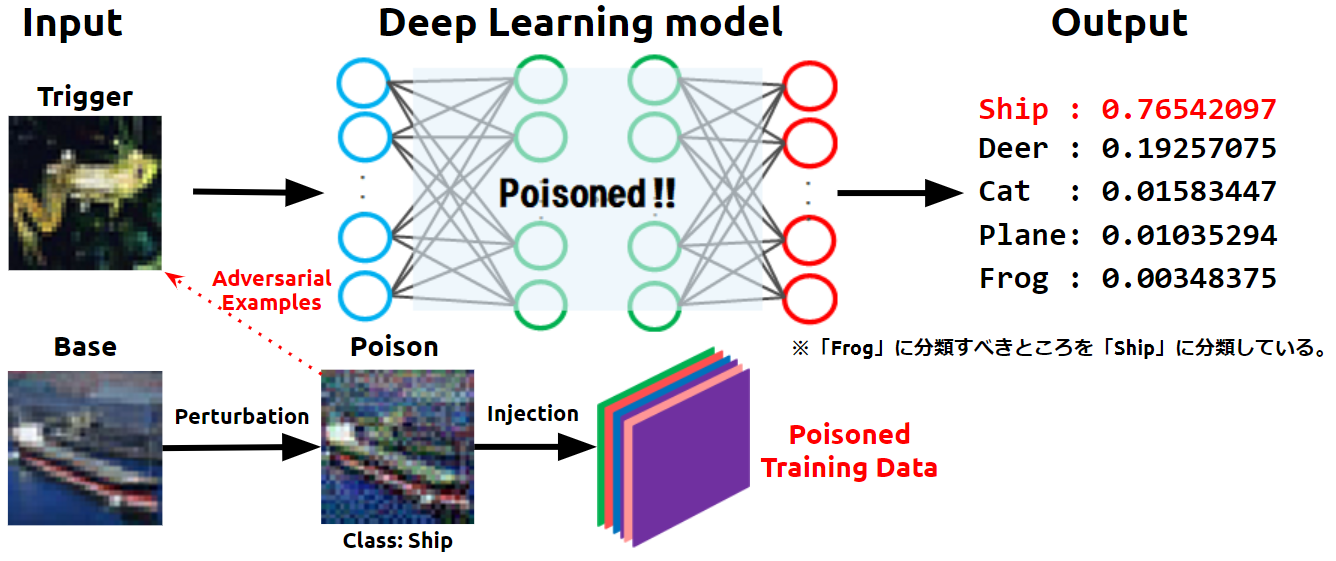
第4回:Feature Collition Attack -学習データ汚染攻撃-
Adversarial Robustness Toolbox(ART)は、AI*1セキュリティのためのPythonライブラリです。ARTを使用することで、AIに対する攻撃手法(敵対的サンプル攻撃、データ汚染攻撃、モデル抽...