
概要
NLPのadversarial attack, defenseのサーベイ論文。 画像や音声など入力に微弱なノイズを加えるわけではなく、文字や単語、文単位での入れ替えなど、実際の文章に対して変換を加えるものに限定している。
今までの記事
基本的な背景などは初回のcharacter-levelの記事に書いてある。 今回は文章レベルの敵対的攻撃手法を紹介していく。
論文情報
公開日
2020-5-28
著者情報
Aminul Huq, Mst. Tasnim Pervin
Dept. of Computer Science & Technology, Tsinghua University
論文情報・リンク
Adversarial attack for NLP
このサーベイ論文ではテキストデータに対する敵対的攻撃を文字単位、単語単位、文単位、またこれらを組み合わせる手法の4種類のカテゴリに分けている。それぞれカテゴリごとに攻撃手法を紹介していく。今回は文章単位の手法に着目し、説明していく。
Sentence level attack
文字通り文章単位の処理を行う敵対的攻撃。 文章単位ではモデルの注目する部分をそらすような文章や単語列を挿入する。
Adversarial Examples for Evaluating Reading Comprehension Systems [arxiv abs]
質疑応答タスクに対し、black-boxとwhite-boxの敵対的攻撃手法であるADDSENTとADDANYを提案した。ADDSENTとADDANYの例を以下に示す。
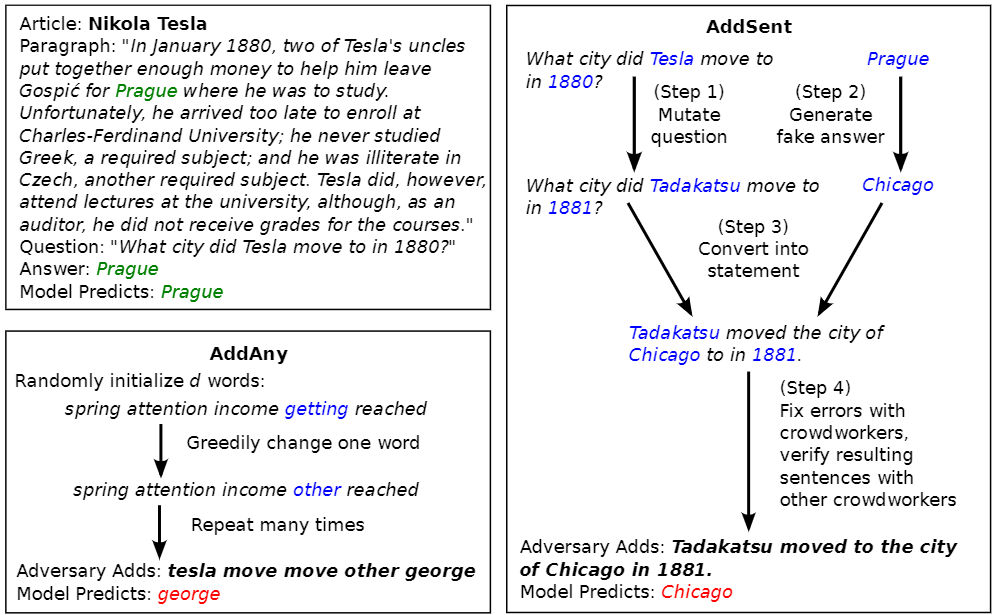
ADDSENTはモデル情報を用いないblack-box敵対的攻撃手法で、以下の4つのstepで生成される。
- 元の質問文の名詞、形容詞をWordNetを参考に反意語に置換、固有表現(場所や人名)と数字をGlove vectorの近傍単語に置換して偽の質問文を生成する。
- What city did Tesla move to in 1880? → What city did Tadakatsu move to in 1881?
- 元の回答を固有表現と品詞情報からカテゴリを定義し、同じカテゴリに属す偽の回答を生成する。
- Prague → Chicago
- 偽の質問に対して偽の回答を答えるための手助けとなる文章を生成する(ルールベースで当てはめる)。
- What city did Tadakatsu move to in 1881? + Chicago → Tadakatsu moved the city of Chicago to in 1881.
- step3で生成した文章に対して構文の誤りなどを手動で治す。
- Tadakatsu moved to the city of Chicago in 1881 → modelの出力 : Chicago (誤り)
このように質問文に対してより答えの根拠となるような敵対的な文章を加える。
ADDANYはモデルの情報を用いるwhite-boxの攻撃手法で、モデルの注目をそらすような単語列を加える処理を行う。ADDANYは以下のstepで生成される。
- 質問文の単語と20個の共通語の集合から単語をn個ランダムに持ってきて単語列Wを生成。
- 単語列Wを元の入力文に加えて、モデルに入力。
- モデルの勾配情報から予測が外れる(F1スコアの下がる)ような単語に変更して、単語列Wを更新。
- 2,3のstepを繰り返す。
ADDANYはADDSENTと違い、元がランダムな単語列を加えるため構文が正しくないことや意味的に成り立たないことが多い。
評価には二つのモデル(Match-LSTMとBiDAF)を用いた。 ADDSENTでは元のスコアの半分に、ADDANYでは1/10程度にモデルの性能を落とすことができた。 ADDSENTとADDANYで生成した文章に対して人的な評価を行い、人間がこれらの攻撃手法に強いことを示した。
Robust Machine Comprehension Models via Adversarial Training [arxiv abs]
上記の論文のADDSENTを改良したwhite-boxの攻撃手法のAddSentDiverseを提案した。 ADDSENTでは生成文を最後に挿入するため多様性がないこと、またルールベースによる生成のため生成文も単調なものとなる。これらの問題に対しAddSentDiverseでは2つの改良を加え、より多様性のある文章を生成できるようになった。
最初に挿入する位置に対しての改良として、挿入位置をランダムに変更した。 これはADDSENTを用いて敵対的学習を行う際に、一番後ろの文章を無視するように学習することを防ぐためである。最後に挿入した場合と最初に挿入した場合では敵対的学習の効果が弱いことが実験によりわかった。また挿入位置をランダムに変更することで敵対的学習の効果が向上することが分かった。
2つ目の改良として、偽の回答をルールベースから動的な生成に変更した。 SQuAD(質疑応答タスクのデータセット)には各データにタグ(人や場所など)が付与されている。ADDSENTでは固有表現や品詞情報を使用して偽の回答を用意したのに対し、AddSentDiverseでは元の回答と同じタグからランダムに別の回答を用意した。これにより生成文章の多様性が増加する。
Generating Natural Adversarial Examples[arxiv abs]
NLI(Natural Language Inference)や機械翻訳タスクに対し、GANを用いたblack-boxの攻撃手法を提案した。GANを用いることで自然な敵対的な文章を生成する。またこの手法がNLP分野以外に画像分野でも適応できることを示した。
GANを用いたテキスト生成のモデル図を以下に示す。

以下のようなstepで生成を行う。
- ARAE(Adversarially Regularized Autencoder)を用いて離散値xをエンコードし、連続コードccを獲得
- 連続コードccを全結合層で構成されたinverterで100次元のベクトルz′z′にマッピング
- zzにノイズを加えたzˇzˇを獲得
- zˇzˇを全結合層で構成されたgeneratorを用いて連続コードcˇcˇへマッピング
- ARAEでデコードして敵対的な文章を作成
NLIでは前提文と仮説文が与えられ仮説が前提文に依存している(entailment)か、矛盾している(contradiction)か、前提文と中立(neutral)かの三種類に分類する。このモデルでは前提文を変更せず、分類モデルを欺くような仮説文を生成できるように学習を行う。
上記の機構で生成した文章の例を以下に示す。

Embedding, LSTM, TReeLSTMはそれぞれ分類モデルで下に行くにつれ強力なモデルとなっている。Label列の矢印は敵対的な文章によって変化した出力を示す。3つのモデルに対してオリジナルと意味をほとんど変えず、モデルの予測を変えることができている。
Robust Neural Machine Translation with Doubly Adversarial Inputs [arxiv abs]
機械翻訳タスクに対するwhite-boxの敵対的攻撃手法のAdvGenを提案した。 AdvGenでは元の文との意味的類似度を保持しつつ、モデルの出力文章がおかしくなるような敵対的な文章を生成する。 以下はAdvGenのアルゴリズムを表している。

以下の流れで敵対的文章を生成する。
- ハイパパラメータγから置換する単語の位置をランダムに選択
- 選択された単語wの置換候補として、双方言語モデルが出力した確率分布から上位n個を取得
- 翻訳モデルから単語wの勾配を取得
- 単語wと置換候補の単語ベクトルの差と単語wの勾配のコサイン類似度を計算
- コサイン類似度が最大となる置換候補と単語wを置換
- 次の単語に対して2~5を行う
AdvGenによる敵対的な文章の生成例を以下に示す。

inputである他(彼)を她(彼女)に置換することで生成文を大きく変更することができる。
論文ではAdvGenで生成した敵対的な文章を使用して、機械翻訳モデルの汎化性能を評価した。
On Evaluation of Adversarial Perturbations for Sequence-to-Sequence Models [arxiv abs]
機械翻訳タスクに対するwhite-boxの敵対的攻撃手法を提案した。またこの論文では敵対的な文章の定量的な評価方法も定義した。 入力文と生成した敵対的な文章の類似度が低い場合、それは良い敵対的な文章といえなくなる。例えば、 「彼は優しい」と「彼は攻撃的」では意味が真逆になるため、出力が大きく変化することは妥当である。入力文と敵対的な文章との類似度を高く保持しつつ、それぞれの出力の類似度が低くなる時に良い敵対的な文章が生成できたといえる。 この論文では敵対的な文章の評価として以下の式用いた。
入力文と生成した敵対的な文章の類似度を測る式として
\[
\text{S}_{src}(x, \check{x})
\] \[
x : \text{入力文}, \check{x} : \text{生成した敵対的な文章}
\]
敵対的な文章に対してのモデルの評価として
\[
\text{d}_{tgt}(y,y_{M},\check{y}_{M}) = \begin{cases} 0\quad\text{if}\quad\text{S}_{tgt}(y, \check{y}_{M}) \geq \text{S}_{tgt}(y, y_{M})\\
\frac{\text{S})_{tgt}(y, y_{M}) – \text{S}_{tgt}(y, \check{y}_{M}) }{\text{S}_{tgt}(y, y)_{M}}\quad\text{otherwise}
\end{cases}
\] \[
y : \text{正解ラベル}, y_{M} : \text{入力}x\text{に対してモデルから生成された文章}
\] \[
\check{y}_{M} : \text{入力}\check{x}\text{に対してモデルから生成された文章}
\]
最終的な評価スコアとして
$\text{S} = \text{S}_{src} + \text{d}_{tgt}$ このスコア $S$ が1より大きいときに、良い敵対的な文章と言える。それぞれ $\text{d}_{tgt}$ と $\text{S}_{src}$ は0~1の値をとり、大きいほど良い敵対的な文章となる。 この評価指標は $\text{S}_{tgt}$ を変えることで分類問題などにも利用できる(binary crossentropy lossなど)。実際に論文ではBLEUやMETETORなどの評価指標などを用いた。
敵対的攻撃については勾配ベースのものに対して、意味の保持を考慮した手法を提案している。 単語を置換する際に、単語置換の候補をKNNにより近傍上位10個に絞ることで意味の保持を行った。
議論
今回は言語処理タスクにおける文章レベルの敵対的攻撃手法にについて紹介した。 モデルが注目する文章を無理やり変えるような文章や単語列を挿入することで。モデルの出力を変更させることができた。
また敵対的な文章を評価する評価手法についても紹介を行った。
次回は文字、単語、文章単位攻撃を混ぜ合わせたマルチ単位の敵対的攻撃手法を紹介していく。