概要
NLPのadversarial attack, defenseのサーベイ論文。 画像や音声など入力に微弱なノイズを加えるわけではなく、文字や単語、文単位での入れ替えなど、実際の文章に対して変換を加えるものに限定している。
今までの記事
基本的な背景などは初回のcharacter-levelの記事にてまとめられている。 今回は今まで紹介した3つの単位(文字、単語、文章)を組み合わせたマルチ単位の敵対的攻撃手法と、これまでの攻撃手法に対する防御手法を紹介していく。
論文情報
公開日
2020-5-28
著者情報
Aminul Huq, Mst. Tasnim Pervin
Dept. of Computer Science & Technology, Tsinghua University
論文情報・リンク
Adversarial attack for NLP
このサーベイ論文ではテキストデータに対する敵対的攻撃を文字単位、単語単位、文単位、またこれらを組み合わせる手法の4種類のカテゴリに分けている。それぞれカテゴリごとに攻撃手法を紹介していく。今回は文字、単語、文章単位を組み合わせたマルチ単位の敵対的攻撃手法に着目し、説明していく。今回でサーベイ論文の紹介は最後である。
Multi level attack
HotFlip: White-Box Adversarial Examples for Text Classification[arxiv abs]
文書分類タスクに対して、white-boxの敵対攻撃手法であるHotflipを提案した。Hotflipは文字単位を入力とする文書分類モデルに対して作られたが、単語単位のモデルに対しても適応できることを示した。
Hotflipは各文字のone-hotを入力とする文書分類の勾配情報に基づいて、文字を置換、消去、挿入の処理を行う。またビームサーチを用いて、より効率的な変更を複数同時に行うことができる。このとき、必要な計算はforwardとbackwardの一回ずつで済むため、敵対的文章の生成に対するコストも低い。
下の図は1文字のみを置換したときのHotflipの生成例である。

各段の上が元の文章で下が敵対的文章を表していて、変更箇所は太字になっている。各段1文字の変更だけでモデルの予測を変えることができている。
単語単位のモデルにHotflipを適応するときは、文章の意味を保持するような以下の制約を加える。
- 単語埋め込み表現のcos類似度が閾値(0.8)以上の単語
- 置換する単語が同じ品詞
- stop wordは置換しない
以下は1単語のみ置換したときのHotfipの生成例である。

()の中が置換後の単語を表している。それぞれの例で文章の意味を保持したまま、モデルの予測を変えることができている。中でも2行目のgood→terrificや4行目のnice→wonderfulは人間にも見分けのつかないような敵対的文章となっている。
Comparing Attention-based Convolutional and Recurrent Neural Networks: Success and Limitations in Machine Reading Comprehension[arxiv abs]
質疑応答タスクに対して、white-boxとblack-boxの敵対攻撃手法を提案した。それぞれ単語レベルと文章レベルの攻撃手法を用いている。
- black-box word-level attack 意味を保持する単語に手動で置換した。
- white-box word-level attack Attention mapの重みを基準に最も重要となる単語をデータセットの語彙集合からランダムに選択して置換する。 置換する単語を増やすことでより強力な攻撃になる。
- black-box sentence-level attack sentence-levelの手法であるADANNYを参考に、20個の候補単語から最もモデルの予測が変化するような単語列を選択する。
- white-box sentence-level attack Attention mapの重みを基準に最も重要となる文章を削除する。
Universal Adversarial Triggers for Attacking and Analyzing NLP[arxiv abs]
文書分類と質疑応答タスクに対して、white-boxの攻撃手法を提案した。トリガーと呼ばれるシーケンス(単語、文字、サブワードのいずれか)を文書の最初か最後につけることでモデルの出力を変更すること成功した。またこのトリガーはあるモデルの情報から生成するが、ほかのモデルに対しても有効なことが確認されている。またGPT-2のような文章生成モデルにもトリガーによって任意の特性を持った文章を生成することができる。
トリガーの生成は以下のステップで行う。
- トリガーの長さを決める。長いほうが効果的だが、見つかりやすい。
- 単語the、文字a、サブワードaのどれかをトリガーの長さ分繰り返し、単語列を生成。
- 目的のラベルとの誤差を最小化するようにトリガーを勾配情報から更新。 勾配計算をバッチ単位で行うことで、どんなデータに対しても成功するようなトリガーを生成できる。
以下はトリガーとモデルの出力の変化を示している。

Sentiment Analysisのタスクではzoning tapping finnesの単語列のトリガーで出力を変更できている。 質疑応答タスク(SQuAD)ではwhyから始まる質問文に対してトリガーを入れることで攻撃性の高い回答が生成できている。 またGPT-2による文章生成でも攻撃性の高い文章が生成できている。
Adversarial defence for NLP
上記や前回までの記事でNLP分野の敵対的攻撃手法について紹介してきた。ここではNLP分野の敵対的攻撃手法に対する防御手法について紹介する。
しかし、NLP分野では攻撃手法に焦点を当てているものが多く防御手法に着目している論文は少ない。今回は最も有名なadverasrial training(AT)といくつかの攻撃手法に対しての防御手法を紹介する。
Adverarial Training
Adversarial training(AT)とはadversarial exampleを学習に用いることでモデルの汎化性能を上げる手法である。汎化性能を上げるだけではなく、学習にadversarial exampleを用いるため、敵対的攻撃に対して有効な防御手法にもなる。 NLP分野でも文字レベル編で紹介したTEXTBUGGERや単語レベル編で紹介した意義素ベースの敵対的な文章を学習に用いることで、モデルの汎化性能の向上が確認された。しかしATを用いた学習では汎化性のが得られる反面、ATなしの場合よりもテストの精度がさがるといったことも報告されている。 またATは学習時に多くの敵対的攻撃手法を用いる必要ある。だからといって全ての攻撃手法を盛り込むと学習データにノイズが大きくなり、学習の妨げとなってしまう。そのため攻撃手法の多いNLP分野ではATが必ずしも万全な防御手法とは言えない。
Topic Specific Defense Techniques
ATは全ての攻撃に対して有効ではないため、ここではある攻撃手法に特化した防御手法を紹介していく。
Natural Language Adversarial Attacks and Defenses in Word Level[arxiv abs]
同義語ベースの敵対的攻撃手法に対して、ATが有効ではないことが報告されている。これに対してこの論文では全ての同義語をクラスター化して、同じクラスターの単語は似たベクトル表現になるようにする制約を加える。この制約により、同義語ベースの敵対的攻撃手法など4種類の攻撃手法でATよりも高い防御性能が確認できた。
Combating Adversarial Misspellings with Robust Word Recognition[arxiv abs]
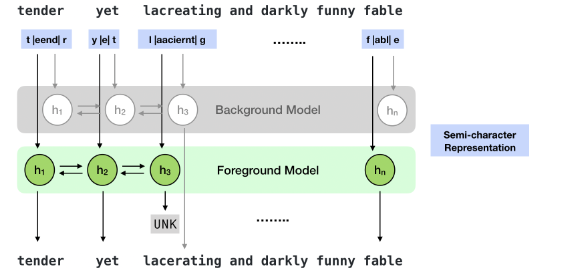
この論文では文字単位の敵対的攻撃手法のswapやdeleteに対して元の単語を復元する機構を提案している。この機構は防御手法としてだけではなく、誤字脱字を治す機構としても利用できる。 実際にはforegroundとbackgroundの2つのモデルを用いて、foreground modelは各ドメインで学習したモデルでBackground modelは大規模コーパスで学習したモデルとなっている。 基本的にはforeground modelで復元を行い、UNKトークンが出力されたときbackground modelを用いる。
以下の図はモデルの概要図になっている。

モデルには各単語の最初の文字と最後の文字、中間の文字のbag of words(順番関係なし)の3つが入力される。そこから各単語が実際にどの単語かを予測していく。
分類タスクのにおいて、攻撃によりaccuracyが90%から45%に落ちたモデルに対して、修正を挟むことにより75%まで精度の低下を抑えることができた。
Learning to discriminate perturbationsfor blocking adversarial attacks in text classification.[arxiv abs]
この論文では文章の各単語が敵対的攻撃によって変更された単語かどうかを見分けるdiscriminato perturbations(DISP)と、文脈に基づいて変更箇所を元の単語埋め込みに戻す役割を持つembedding estimatorを提案している。
以下は提案しているフレームワークの全体図になっている。
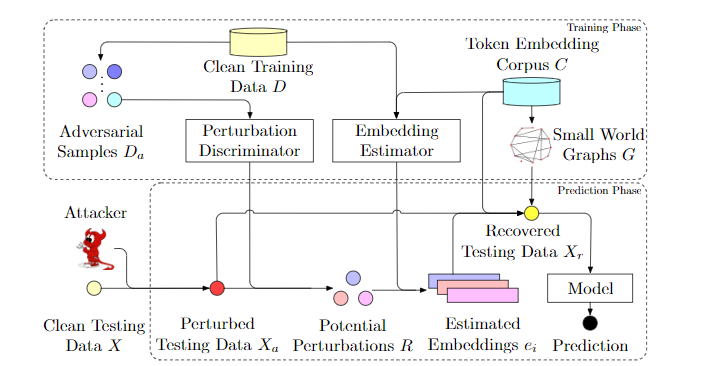
学習時は訓練データから生成された敵対的文章を入力として、各単語が変更されたものかどうかを見分けるように学習する。Embedding estimatorは周りの文脈から元の単語を復元するように学習を行う。
DISPは上記の文章を修正する手法と比較してより高い防御性能が確認されている。
議論
今回は文字、単語、文章のそれぞれの攻撃を組み合わせたマルチレベルの敵対的攻撃手法と、それらの敵対的攻撃からモデルを守るための防御手法について紹介を行った。 マルチレベルの敵対的攻撃手法では単純に1つの攻撃だけではなく、複数レベルの攻撃をく合わせることでモデルをよりだますことが可能になっている。 防御手法では代表的なadversarial trainingをはじめ、それぞれの攻撃手法に特化した防御手法について紹介した。防御手法は攻撃に対して精度の低下を抑えることができているが、まだ完全に防御できているとは言えない。また、最後に紹介した2つの防御手法は深層学習ベースの修正を行う手法のため、これらに対する敵対的攻撃が行われることなども考えられる。
最後に
これまで4回にわたってNLP分野の攻撃手法や防御手法について紹介を行ってきた。私が思うにこれまで論文を読んできて、NLP分野での敵対的攻撃手法には2つのケースがあると考えている。
モデルと人間両方を騙すケース
これは音声や画像分野と同じように、人間が見てもおかしな点がないような文章に対して、モデルが分類を間違えるといったものとなる。これはデータ拡張などにも適応できる攻撃的手法であると考えている。しかし、このようなケースは生成が難しく、white-boxを想定しているものが多い。
モデルのみを騙すケース
これはモデルは予測を間違えるが、人間は異常だと検知できたり元の文章を復元できるものである。これはSNSなどのコメントのフィルタリング機能を無視しつつ、相手に攻撃的な文章を送れるもので、日本語の例を出すと「タヒね」など1文字を2文字に分解するものや、「ア.ホ」など単語の間に.やスペースなどを入れるものなどがある。 これらの攻撃は比較的に簡単となっていて、機械学習などの知識を持っていない人々でも簡単に思いつく事のできる攻撃である。そのため特にSNSや匿名サービスなどではこれらの攻撃に対する対策は必要となると私は考えている。